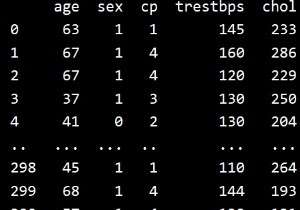
सांख्यिकीय विश्लेषण के लिए डेटा को उचित और गुणात्मक बनाने के लिए कई बार हम डेटा स्मूथिंग नामक एक विधि का उपयोग करते हैं। धूम्रपान प्रक्रिया के दौरान हम एक सीमा को परिभाषित करते हैं जिसे बिन भी कहा जाता है और सीमा के भीतर किसी भी डेटा मान को बिन में फिट करने के लिए बनाया जाता है। इसे बिनिंग विधि कहा जाता है। नीचे बिनिंग का एक उदाहरण है। फिर हम देखेंगे कि हम पायथन प्रोग्राम का उपयोग करके बिनिंग विधि को कैसे प्राप्त कर सकते हैं।
बिनिंग उदाहरण
आइए संख्याओं की एक श्रृंखला लें। अधिकतम और न्यूनतम मान ज्ञात कीजिए। विश्लेषण के लिए कितने डेटा बिंदुओं की आवश्यकता है, इसके आधार पर हमें आवश्यक डिब्बे की संख्या तय करें। ये समूह बनाएं और इनमें से प्रत्येक संख्या को इस समूह को असाइन करें। ऊपरी मान को बाहर रखा गया है और अगले समूह से संबंधित है।
उदाहरण
Given numbers: 12, 32, 10, 17, 19, 28, 22, 26, 29,16 Number of groups : 4 Here Max Value: 32 Min Value: 10 So the groups are – (10-15), (15-21), (21-27), (27-32)
आउटपुट
संख्याओं को डिब्बे में डालने पर, हमें निम्नलिखित परिणाम मिलते हैं -
12 -> (10-15) 32 -> (27-32) 10 -> (10-15) 17 -> (15-21) 19 -> (15-21) 28 -> (27-32) 22 -> (21-27) 26 -> (21-27) 29 -> (27-32) 16 -> (15-21)
बिनिंग प्रोग्राम
इस कार्यक्रम के लिए हम दो कार्यों को परिभाषित करते हैं। एक ऊपरी और निचली सीमा को परिभाषित करके डिब्बे बनाने के लिए। अन्य कार्य प्रत्येक बिन को इनपुट मान निर्दिष्ट करना है। प्रत्येक बिन को एक इंडेक्स भी मिलता है। हम देखते हैं कि कैसे प्रत्येक इनपुट मान बिन को असाइन किया जाता है और यह ट्रैक करते हैं कि एक विशिष्ट बिन में कितने मान जाते हैं।
उदाहरण
from collections import Counter
def Binning_method(lower_bound, width, quantity):
binning = []
for low in range(lower_bound, lower_bound + quantity * width + 1, width):
binning.append((low, low + width))
return binning
def bin_assign(v, b):
for i in range(0, len(b)):
if b[i][0] <= v < b[i][1]:
return i
the_bins = Binning_method(lower_bound=50,
width=4,
quantity=10)
print("The Bins: \n",the_bins)
weights_of_objects = [89.2, 57.2, 63.4, 84.6, 90.2, 60.3,88.7, 65.2, 79.8, 80.2, 93.5, 79.3,72.5, 59.2, 77.2, 67.0, 88.2, 73.5]
print("\nBinned Values:\n")
binned_weight = []
for val in weights_of_objects:
index = bin_assign(val, the_bins)
#print(val, index, binning[index])
print(val,"-with index-", index,":", the_bins[index])
binned_weight.append(index)
freq = Counter(binned_weight)
print("\nCount of values in each index: ")
print(freq) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
The Bins:
[(50, 54), (54, 58), (58, 62), (62, 66), (66, 70), (70, 74), (74, 78), (78, 82), (82, 86), (86, 90), (90, 94)]
Binned Values:
89.2 -with index- 9 : (86, 90)
57.2 -with index- 1 : (54, 58)
63.4 -with index- 3 : (62, 66)
84.6 -with index- 8 : (82, 86)
90.2 -with index- 10 : (90, 94)
60.3 -with index- 2 : (58, 62)
88.7 -with index- 9 : (86, 90)
65.2 -with index- 3 : (62, 66)
79.8 -with index- 7 : (78, 82)
80.2 -with index- 7 : (78, 82)
93.5 -with index- 10 : (90, 94)
79.3 -with index- 7 : (78, 82)
72.5 -with index- 5 : (70, 74)
59.2 -with index- 2 : (58, 62)
77.2 -with index- 6 : (74, 78)
67.0 -with index- 4 : (66, 70)
88.2 -with index- 9 : (86, 90)
73.5 -with index- 5 : (70, 74)
Count of values in each index:
Counter({9: 3, 7: 3, 3: 2, 10: 2, 2: 2, 5: 2, 1: 1, 8: 1, 6: 1, 4: 1})