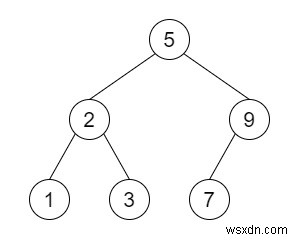
मान लीजिए कि हम एक बाइनरी सर्च ट्री को क्रमबद्ध और डीरियलाइज़ करने के लिए एक एल्गोरिथम डिज़ाइन करना चाहते हैं। सीरियलाइजेशन कुछ (डेटा संरचना या ऑब्जेक्ट) को बिट्स के अनुक्रम में परिवर्तित करने की प्रक्रिया है ताकि इसे फ़ाइल या मेमोरी बफर में संग्रहीत किया जा सके, या नेटवर्क कनेक्शन लिंक पर प्रसारित किया जा सके। इसे बाद में फिर से बनाया जा सकता है कि प्रक्रिया अक्रमांकन है।
इसलिए, यदि इनपुट [5,2,9,1,3,7] जैसा है, तो आउटपुट सीरियलाइज्ड आउटपुट 5.2.9.1.3.7. (इनऑर्डर ट्रैवर्सल)
इसे हल करने के लिए, हम इन चरणों का पालन करेंगे -
-
एक फ़ंक्शन को परिभाषित करें serialize() । यह जड़ लेगा
-
रेस :=एक नई सूची
-
एक कतार परिभाषित करें और रूट डालें
-
जबकि कतार खाली नहीं है, करें
-
जबकि कतार खाली नहीं है, करें
-
वर्तमान:=कतार[0]
-
रेस के अंत में करंट डालें
-
कतार से पहला तत्व हटाएं
-
अगर करंट गैर-शून्य है, तो
-
लूप से बाहर आएं
-
-
-
अगर करंट शून्य है, तो
-
लूप से बाहर आएं
-
-
अगर current.left शून्य नहीं है, तो
-
कतार के अंत में current.left डालें
-
-
अन्यथा,
-
कतार के अंत में कोई नहीं डालें
-
-
अगर current.right शून्य नहीं है, तो
-
कतार के अंत में current.right डालें
-
-
अन्यथा,
-
कतार के अंत में कोई नहीं डालें
-
-
-
s:=रिक्त स्ट्रिंग
-
मैं के लिए 0 से लेकर रेस के आकार तक के लिए, करें
-
अगर रेस [i] शून्य नहीं है, तो
-
s :=s concatenate res[i].data
-
-
अन्यथा,
-
s :=s "N" को जोड़ना
-
-
अगर मैं रेस -1 के आकार के समान हूं, तो
-
लूप से बाहर आएं
-
-
s :=s concatenate "।"
-
-
वापसी एस
-
एक फ़ंक्शन को परिभाषित करें deserialize() । यह डेटा लेगा
-
डेटा:=डॉट का उपयोग करके डेटा को विभाजित करने के बाद भागों की एक सूची
-
स्टैक :=एक नई सूची
-
अगर डेटा [0] 'एन' के समान है, तो
-
कोई नहीं लौटाएं
-
-
रूट:=डेटा डेटा के साथ एक नया नोड बनाएं[0]
-
स्टैक के अंत में रूट डालें
-
मैं :=1
-
वर्तमान:=0
-
जबकि मैं <डेटा का आकार, करता हूं
-
बायां:=झूठा
-
अगर डेटा [i] 'एन' के समान नहीं है, तो
-
अस्थायी:=डेटा डेटा के साथ एक नया नोड बनाएं[i]
-
स्टैक [वर्तमान]। बाएं:=अस्थायी
-
स्टैक के अंत में अस्थायी डालें
-
-
अन्यथा,
-
स्टैक [वर्तमान]। बाएं:=कोई नहीं
-
-
मैं :=मैं + 1
-
अगर डेटा [i] 'एन' के समान नहीं है, तो
-
अस्थायी:=डेटा डेटा के साथ एक नया नोड बनाएं[i]
-
स्टैक [वर्तमान]। दाएं:=अस्थायी
-
स्टैक के अंत में अस्थायी डालें
-
-
अन्यथा,
-
स्टैक [वर्तमान]। दाएं:=कोई नहीं
-
-
वर्तमान:=वर्तमान + 1
-
मैं :=मैं + 1
-
-
वापसी जड़
उदाहरण
आइए एक बेहतर समझ प्राप्त करने के लिए निम्नलिखित कार्यान्वयन देखें -
class TreeNode:
def __init__(self, data, left = None, right = None):
self.data = data
self.left = left
self.right = right
def insert(temp,data):
que = []
que.append(temp)
while (len(que)):
temp = que[0]
que.pop(0)
if (not temp.left):
if data is not None:
temp.left = TreeNode(data)
else:
temp.left = TreeNode(0)
break
else:
que.append(temp.left)
if (not temp.right):
if data is not None:
temp.right = TreeNode(data)
else:
temp.right = TreeNode(0)
break
else:
que.append(temp.right)
def make_tree(elements):
Tree = TreeNode(elements[0])
for element in elements[1:]:
insert(Tree, element)
return Tree
def print_tree(root):
#print using inorder traversal
if root is not None:
print_tree(root.left)
print(root.data, end = ', ')
print_tree(root.right)
class Codec:
def serialize(self, root):
res =[]
queue = [root]
while queue:
while True and queue:
current = queue[0]
res.append(current)
queue.pop(0)
if current:
break
if not current:
break
if current.left:
queue.append(current.left)
else:
queue.append(None)
if current.right:
queue.append(current.right)
else:
queue.append(None)
s=""
for i in range(len(res)):
if res[i]:
s+=str(res[i].data)
else:
s+="N"
if i == len(res)-1:
break
s+="."
return s
def deserialize(self, data):
data = data.split(".")
stack = []
if data[0]=='N':
return None
root = TreeNode(int(data[0]))
stack.append(root)
i = 1
current = 0
while i <len(data):
left= False
if data[i] !='N':
temp = TreeNode(int(data[i]))
stack[current].left = temp
stack.append(temp)
else:
stack[current].left = None
i+=1
if data[i] !='N':
temp = TreeNode(int(data[i]))
stack[current].right = temp
stack.append(temp)
else:
stack[current].right = None
current+=1
i+=1
return root
ob = Codec()
root = make_tree([5,2,9,1,3,7])
ser = ob.serialize(root)
print('Serialization:',ser)
print_tree(ob.deserialize(ser)) इनपुट
[5,2,9,1,3,7]
आउटपुट
Serialization: 5.2.9.1.3.7.N.N.N.N.N.N.N 1, 2, 3, 5, 7, 9,