हम सीबॉर्न का उपयोग करेंगे। सीबॉर्न एक पुस्तकालय है जो डेटा की कल्पना करने में मदद करता है। यह अनुकूलित थीम और एक उच्च-स्तरीय इंटरफ़ेस के साथ आता है। यह इंटरफ़ेस डेटा के प्रकार को अनुकूलित और नियंत्रित करने में मदद करता है और जब कुछ फ़िल्टर लागू होते हैं तो यह कैसे व्यवहार करता है।
'स्ट्रिपप्लॉट' फ़ंक्शन का उपयोग तब किया जाता है जब कम से कम एक चर श्रेणीबद्ध होता है। डेटा को कुल्हाड़ियों में से एक के साथ क्रमबद्ध तरीके से दर्शाया गया है। लेकिन नुकसान यह है कि कुछ बिंदु ओवरलैप हो जाते हैं। यह वह जगह है जहां चर के बीच अतिव्यापी से बचने के लिए 'घबराना' पैरामीटर का उपयोग किया जाना है।
यह डेटासेट में कुछ यादृच्छिक शोर जोड़ता है, और श्रेणीबद्ध अक्ष के साथ मानों की स्थिति को समायोजित करता है। लेकिन, 'घबराना' पैरामीटर का उपयोग करने के बजाय, हम श्रेणीबद्ध स्कैटर प्लॉट प्राप्त करने के लिए 'swarmplot' का उपयोग कर सकते हैं।
स्वार्मप्लॉट फ़ंक्शन का सिंटैक्स
seaborn.swarmplot(x, y,data,…)
इसे नीचे दिखाया गया है -
उदाहरण
पंडों को pdimport सीबोर्न के रूप में sbfrom matplotlib के रूप में आयात करें pltmy_df =sb.load_dataset('iris')sb.swarmplot(x ="species", y ="petal_length", data =my_df)plt.show()<के रूप में आयात करें। /पूर्व> आउटपुट
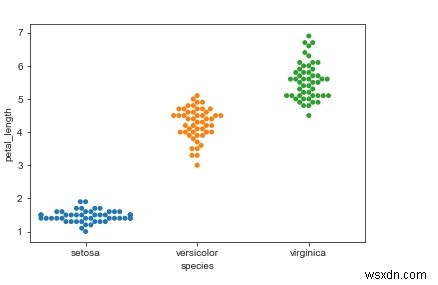
स्पष्टीकरण
- आवश्यक पैकेज आयात किए जाते हैं।
- इनपुट डेटा 'आईरिस_डेटा' है जो स्किकिट लर्न लाइब्रेरी से लोड किया गया है।
- यह डेटा डेटाफ़्रेम में संग्रहीत किया जाता है।
- 'load_dataset' फ़ंक्शन का उपयोग आईरिस डेटा को लोड करने के लिए किया जाता है।
- इस डेटा को 'swarmplot' फ़ंक्शन का उपयोग करके देखा जाता है।
- यहां, डेटाफ्रेम पैरामीटर के रूप में दिया गया है।
- साथ ही, x और y मान निर्दिष्ट हैं।
- यह डेटा कंसोल पर प्रदर्शित होता है।