डेटा को विज़ुअलाइज़ करना एक महत्वपूर्ण कदम है क्योंकि यह यह समझने में मदद करता है कि वास्तव में संख्याओं को देखे बिना और जटिल गणना किए बिना डेटा में क्या चल रहा है। सीबॉर्न एक पुस्तकालय है जो डेटा को विज़ुअलाइज़ करने में मदद करता है।
स्कैटर प्लॉट डेटा के वितरण को डेटा बिंदुओं के रूप में दिखाता है जो ग्राफ़ पर फैले/बिखरे हुए हैं। यह डेटासेट के मूल्यों का प्रतिनिधित्व करने के लिए डॉट्स का उपयोग करता है, जो प्रकृति में संख्यात्मक होते हैं। क्षैतिज और लंबवत अक्ष पर प्रत्येक बिंदु की स्थिति एकल डेटा बिंदु के मान को दर्शाती है।
वे दो चर के बीच संबंध को समझने में मदद करते हैं। आइए समझते हैं कि पायथन में सीबॉर्न लाइब्रेरी का उपयोग करके इसे कैसे प्राप्त किया जा सकता है -
उदाहरण
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show() के रूप में आयात करें आउटपुट
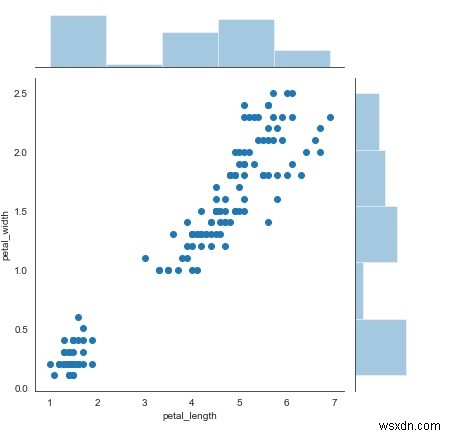
स्पष्टीकरण
- आवश्यक पैकेज आयात किए जाते हैं।
- इनपुट डेटा 'आईरिस_डेटा' है जो स्किकिट लर्न लाइब्रेरी से लोड किया गया है।
- यह डेटा डेटाफ़्रेम में संग्रहीत किया जाता है।
- 'load_dataset' फ़ंक्शन का उपयोग आईरिस डेटा को लोड करने के लिए किया जाता है।
- इस डेटा को 'jointplot' फ़ंक्शन का उपयोग करके देखा जाता है।
- यहां, 'x' और 'y' अक्ष मान पैरामीटर के रूप में दिए गए हैं।
- यह स्कैटरप्लॉट डेटा कंसोल पर प्रदर्शित होता है।