माटप्लोटलिब को प्लॉट करने के लिए PySpark SQL का उपयोग करना परिणाम, हम निम्नलिखित कदम उठा सकते हैं-
- आकृति का आकार सेट करें और सबप्लॉट के बीच और आसपास पैडिंग समायोजित करें।
- उदाहरण प्राप्त करें जो स्पार्क कार्यक्षमता के लिए मुख्य प्रवेश बिंदु है।
- स्पार्क एसक्यूएल के एक प्रकार का उदाहरण प्राप्त करें जो हाइव में संग्रहीत डेटा के साथ एकीकृत होता है।
- टपल के रूप में रिकॉर्ड की सूची बनाएं।
- RDD बनाने के लिए स्थानीय पायथन संग्रह वितरित करें।
- सूची रिकॉर्ड को DB स्कीमा के रूप में मैप करें।
- "my_table" में प्रविष्टि करने के लिए स्कीमा इंस्टेंस प्राप्त करें।
- तालिका में रिकॉर्ड डालें।
- SQL क्वेरी पढ़ें, रिकॉर्ड पुनर्प्राप्त करें।
- प्राप्त किए गए रिकॉर्ड को डेटा फ़्रेम में बदलें।
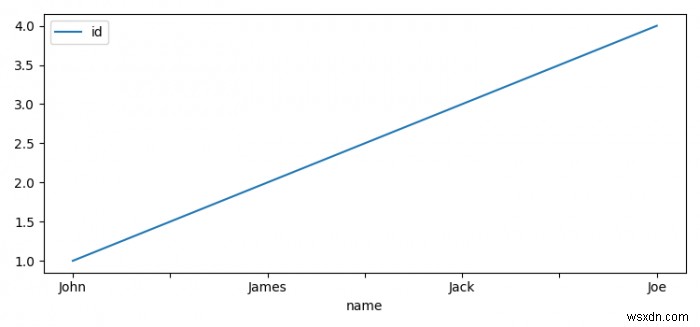
- इंडेक्स को नाम के साथ सेट करें विशेषता दें और उन्हें प्लॉट करें।
- आंकड़ा प्रदर्शित करने के लिए, दिखाएं () . का उपयोग करें विधि।
उदाहरण
from pyspark.sql import Row
from pyspark.sql import HiveContext
import pyspark
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [7.50, 3.50]
plt.rcParams["figure.autolayout"] = True
sc = pyspark.SparkContext()
sqlContext = HiveContext(sc)
test_list = [(1, 'John'), (2, 'James'), (3, 'Jack'), (4, 'Joe')]
rdd = sc.parallelize(test_list)
people = rdd.map(lambda x: Row(id=int(x[0]), name=x[1]))
schemaPeople = sqlContext.createDataFrame(people)
sqlContext.registerDataFrameAsTable(schemaPeople, "my_table")
df = sqlContext.sql("Select * from my_table")
df = df.toPandas()
df.set_index('name').plot()
plt.show() आउटपुट