<पी> एक्सेल में सटीक डेटा विश्लेषण के लिए डुप्लिकेट रिकॉर्ड प्रबंधित करना महत्वपूर्ण है। एक्सेल में डुप्लिकेट डेटा गलत गणना, ब्लॉट फ़ाइल आकार और भ्रम पैदा कर सकता है। एक्सेल डुप्लिकेट को हटाने के लिए कई तरीके प्रदान करता है। <पी> इस ट्यूटोरियल में, हम बिना डेटा खोए एक्सेल में डुप्लिकेट हटाने के 8 तरीके दिखाएंगे।
1. डुप्लिकेट टूल हटाएँ
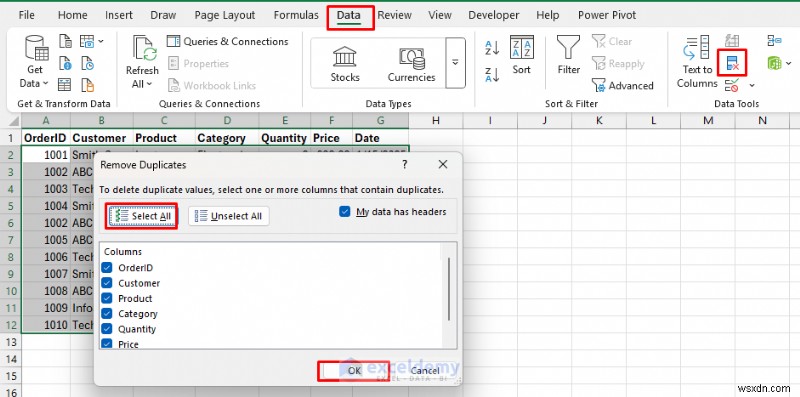
<पी> एक्सेल की अंतर्निहित रिमूव डुप्लिकेट सुविधा उपयोगकर्ता के अनुकूल इंटरफेस के साथ त्वरित समाधान प्रदान करती है। <पी> कदम:- हेडर सहित अपनी डेटा श्रेणी चुनें।
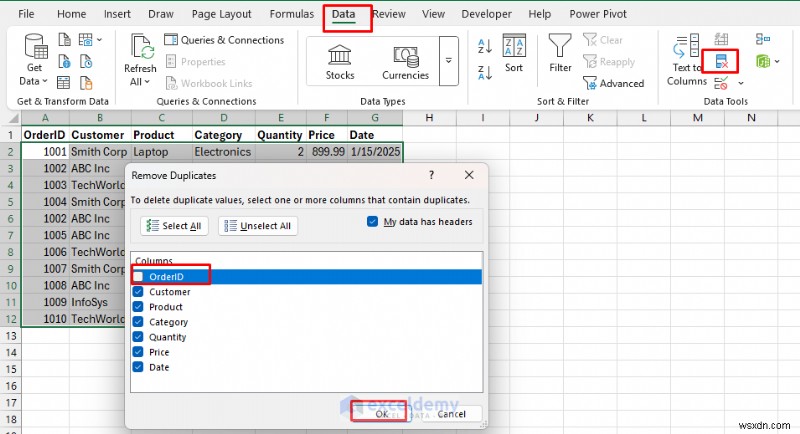
- डेटा पर जाएं टैब>> डेटा टूल्स से समूह>> डुप्लिकेट निकालें चुनें .
- कौन से संयोजन डुप्लिकेट बनाते हैं यह निर्धारित करने के लिए कॉलम को चेक/अनचेक करें।
- ठीक क्लिक करें .
 <पी> मामला:
<पी> मामला: - यदि हम सभी कॉलम चुनते हैं, तो केवल पंक्ति 6 (ऑर्डर आईडी 1002) हटा दी जाएगी क्योंकि यह पंक्ति 1 का सटीक डुप्लिकेट है।
- एक्सेल एक संदेश प्रदर्शित करेगा कि 1 डुप्लिकेट मान पाया गया और हटा दिया गया।
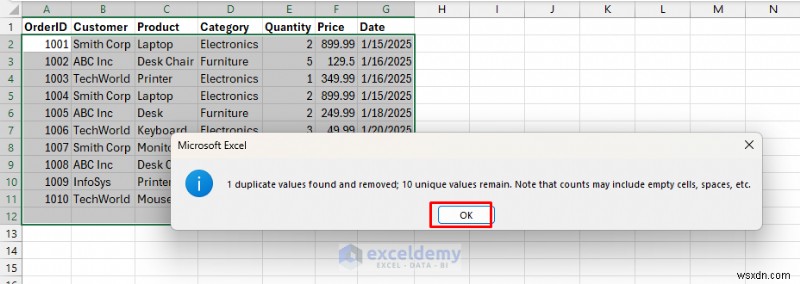
- यदि हम OrderID को अनचेक करते हैं और अन्य सभी कॉलम जांचें।
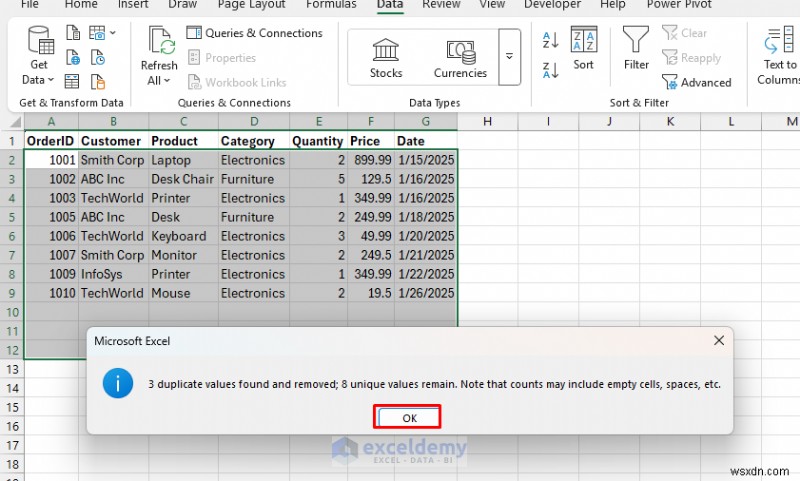
- पंक्तियों 5, 6 और 8 को डुप्लिकेट के रूप में हटा दिया जाएगा।
 <पी> फायदे:
<पी> फायदे: - विज़ुअल इंटरफ़ेस के साथ उपयोग करना सरल।
- सीधे आपके डेटा पर काम करता है।
- निर्दिष्ट कर सकते हैं कि कौन से कॉलम की जांच करनी है।
- डुप्लिकेट पंक्तियों को स्थायी रूप से हटा देता है।
- प्रत्येक रिकॉर्ड का केवल पहला उदाहरण रखता है।
- जब तक आपने बैकअप नहीं बनाया है तब तक मूल डेटा पुनर्प्राप्त नहीं किया जा सकता है।
2. उन्नत फ़िल्टर (केवल अद्वितीय रिकॉर्ड)
<पी> उन्नत फ़िल्टर आपको अद्वितीय रिकॉर्ड को एक नए स्थान पर कॉपी करने की सुविधा देकर अधिक नियंत्रण प्रदान करता है। <पी> कदम:- हेडर के साथ अपना डेटा व्यवस्थित करें।
- डेटा पर जाएं टैब>> सॉर्ट और फ़िल्टर से समूह>> उन्नत चुनें .
- दूसरे स्थान पर कॉपी करें चुनें .
- सूची श्रेणी में अपनी डेटा श्रेणी चुनें: A1:G12 .
- में कॉपी:J1 .
- चेक करें केवल अद्वितीय रिकॉर्ड .
- ठीक क्लिक करें .
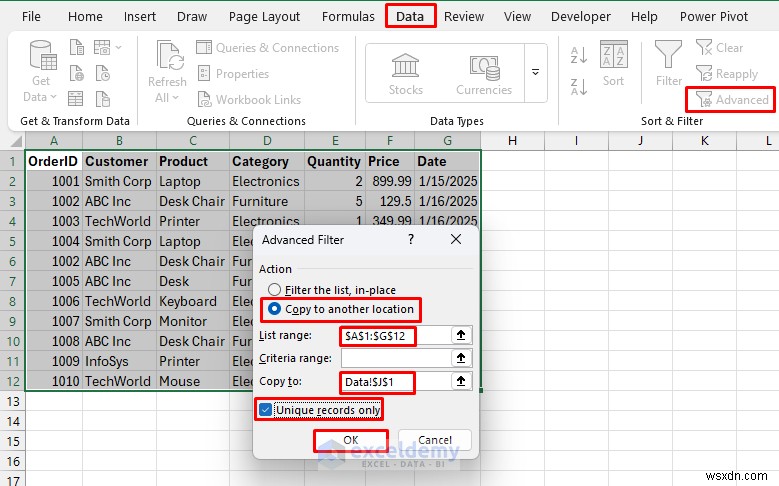 <पी> डुप्लिकेट पंक्ति 6 (ऑर्डरआईडी 1002) को परिणामों से बाहर रखा जाएगा। डेटा को डुप्लिकेट पंक्ति को छोड़कर, सेल J1 और नीचे कॉपी किया जाएगा। <पी>
<पी> डुप्लिकेट पंक्ति 6 (ऑर्डरआईडी 1002) को परिणामों से बाहर रखा जाएगा। डेटा को डुप्लिकेट पंक्ति को छोड़कर, सेल J1 और नीचे कॉपी किया जाएगा। <पी>  <पी> उन्नत उदाहरण: ऑर्डरआईडी की परवाह किए बिना डुप्लिकेट उत्पाद जानकारी के साथ लेनदेन की पहचान करने के लिए, आप यह कर सकते हैं:
<पी> उन्नत उदाहरण: ऑर्डरआईडी की परवाह किए बिना डुप्लिकेट उत्पाद जानकारी के साथ लेनदेन की पहचान करने के लिए, आप यह कर सकते हैं: - हेडर (B1:G1) के साथ एक मानदंड श्रेणी सेट करें।
- उन्नत फ़िल्टर लागू करें इस मानदंड के साथ समान लेनदेन खोजने की सीमा होती है।
- मूल डेटा को सुरक्षित रखता है।
- केवल अद्वितीय रिकॉर्ड को किसी अन्य स्थान पर कॉपी करता है।
- यदि आवश्यक हो तो जटिल मानदंडों के साथ काम करता है।
- फ़िल्टर किए गए परिणामों के लिए उपलब्ध स्थान की आवश्यकता है।
- जब स्रोत डेटा बदलता है तो मैन्युअल रीफ्रेश की आवश्यकता होती है।
3. पावर क्वेरी (प्राप्त करें और रूपांतरित करें)
<पी> पावर क्वेरी एक मजबूत समाधान प्रदान करता है जो मूल डेटा को संरक्षित करता है और बड़े डेटासेट को संभाल सकता है। <पी> कदम:- अपना डेटा चुनें.
- डेटा पर जाएं टैब>> डेटा प्राप्त करें और रूपांतरित करें से समूह>> तालिका/श्रेणी से चुनें .
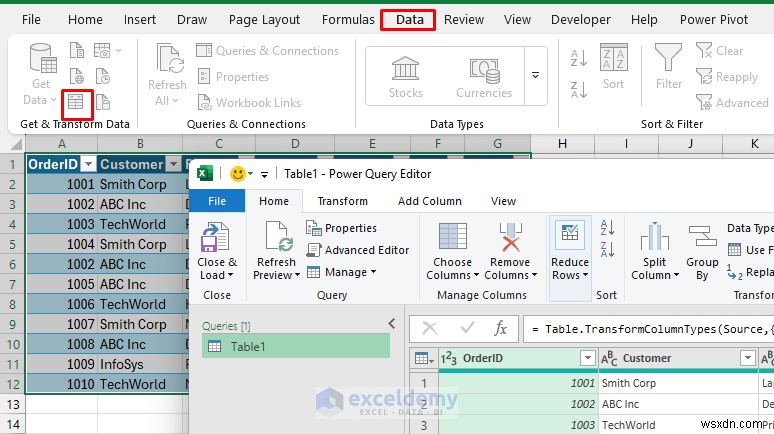
- तुलना के लिए कॉलम चुनें (आप सभी कॉलम या केवल विशिष्ट कॉलम चुन सकते हैं)।
- घर पर जाएं टैब>> पंक्तियाँ हटाएँ समूह>> डुप्लिकेट हटाएं .
- बंद करें और लोड करें पर क्लिक करें परिणामों को एक नई शीट में आयात करने के लिए।
- यदि हम सभी कॉलमों के आधार पर डुप्लिकेट हटाते हैं, तो केवल पंक्ति 6 (ऑर्डरआईडी 1002) हटा दी जाएगी।
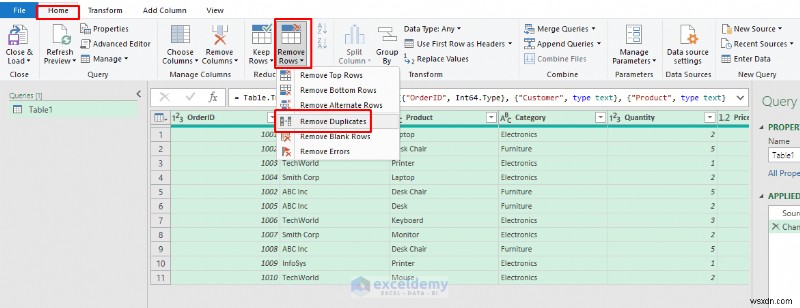
- यदि हम केवल ग्राहक, उत्पाद, मात्रा, मूल्य और दिनांक (ऑर्डरआईडी को छोड़कर) के आधार पर डुप्लिकेट हटाते हैं, तो पंक्ति 4 और 8 दोनों को डुप्लिकेट के रूप में पहचाना जाएगा।
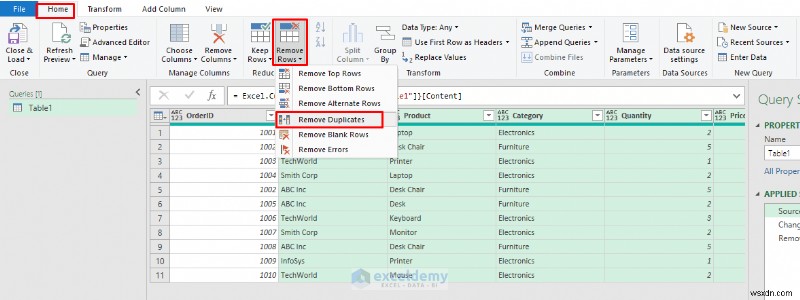 <पी> आउटपुट: <पी>
<पी> आउटपुट: <पी> 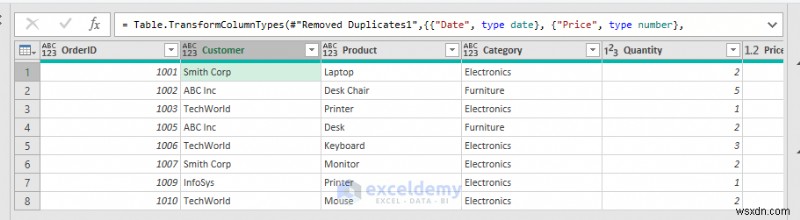 <पी> फायदे:
<पी> फायदे: - एक अलग परिणाम सेट बनाता है जिसे ताज़ा किया जा सकता है।
- बड़े डेटासेट को कुशलतापूर्वक संभालता है।
- मूल डेटा को सुरक्षित रखता है।
- दोहराने योग्य प्रक्रिया का हिस्सा हो सकता है।
- उन्नत परिवर्तन क्षमताएं।
- पावर क्वेरी की बुनियादी समझ की आवश्यकता है।
- बहुत बड़े डेटासेट के लिए अधिक संसाधनों का उपयोग करता है।
- जटिल डुप्लिकेशन तर्क के लिए अतिरिक्त चरणों की आवश्यकता है।
4. अद्वितीय फ़ंक्शन (एक्सेल 365/2021)
<पी> नए एक्सेल संस्करणों के लिए, UNIQUE फ़ंक्शन गतिशील रूप से अलग-अलग मान निकालता है। <पी> डुप्लिकेट पंक्तियाँ हटाएँ:- सेल I1 का चयन करें और निम्नलिखित सूत्र डालें।
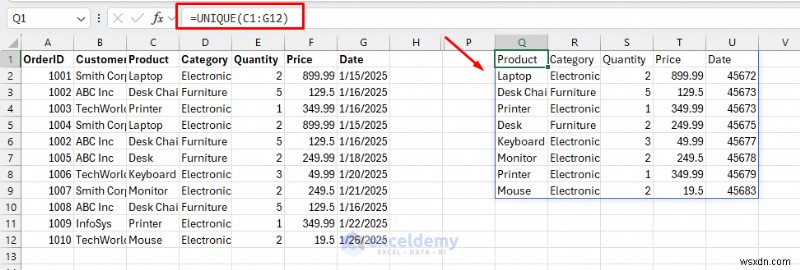
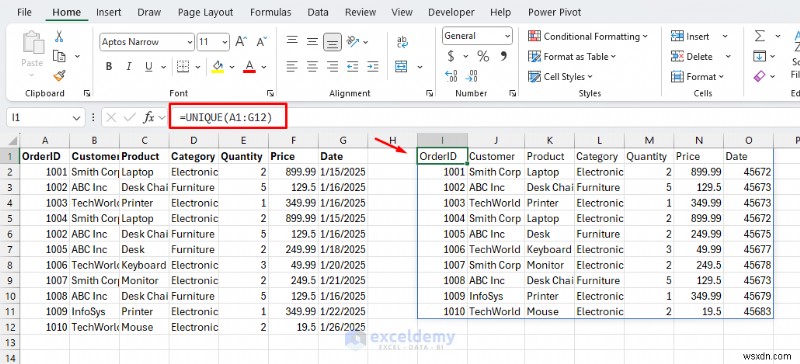 <पी> श्रेणी के अनुसार अद्वितीय उत्पाद: उत्पाद और श्रेणी के अनूठे संयोजन निकालने के लिए।
<पी> श्रेणी के अनुसार अद्वितीय उत्पाद: उत्पाद और श्रेणी के अनूठे संयोजन निकालने के लिए। - एक सेल का चयन करें और निम्नलिखित सूत्र डालें।
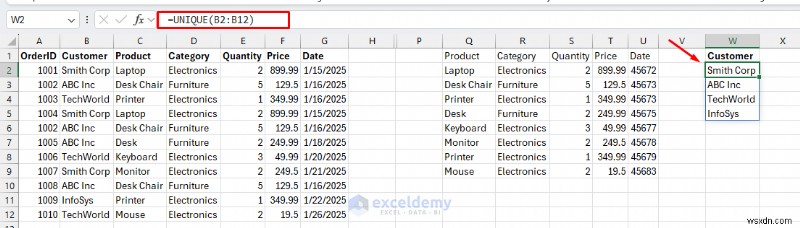
 <पी> अद्वितीय ग्राहक सूची: अद्वितीय ग्राहकों की सूची प्राप्त करने के लिए।
<पी> अद्वितीय ग्राहक सूची: अद्वितीय ग्राहकों की सूची प्राप्त करने के लिए। - एक सेल का चयन करें और निम्नलिखित सूत्र डालें।
 <पी> फायदे:
<पी> फायदे: - गतिशील परिणाम बनाता है जो स्रोत डेटा बदलने पर स्वचालित रूप से अपडेट हो जाते हैं।
- स्रोत डेटा के लिए गैर-विनाशकारी।
- अन्य कार्यों के साथ जोड़ा जा सकता है।
- एकाधिक कॉलम में अद्वितीय संयोजन लौटाता है।
- केवल एक्सेल 365 और एक्सेल 2021 में उपलब्ध है।
- एक स्पिल्ड ऐरे फॉर्मूला बनाता है (स्वचालित रूप से विस्तारित होता है)।
- कार्यस्थल योजना की आवश्यकता हो सकती है।
- बहुत जटिल डुप्लीकेशन तर्क को संभाल नहीं सकता।
5. सशर्त स्वरूपण + फ़िल्टर
<पी> यह दृश्य दृष्टिकोण डुप्लिकेट को हाइलाइट करने और फिर फ़िल्टर करने में मदद करता है। <पी> कदम:- अपनी डेटा श्रेणी चुनें.
- घर पर जाएं टैब>> सशर्त स्वरूपण से>>सेल नियमों को हाइलाइट करें चुनें>> डुप्लिकेट मान चुनें .
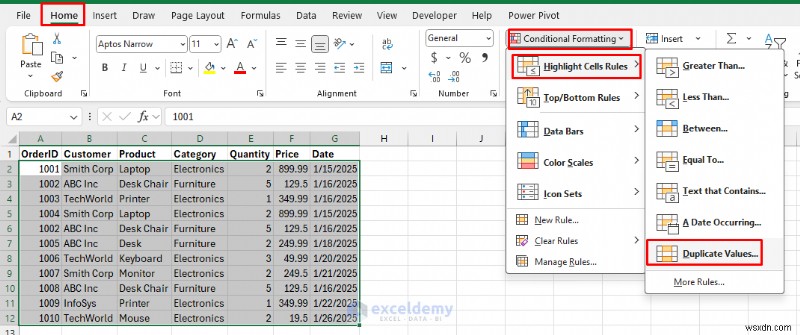
- फ़ॉर्मेटिंग शैली चुनें:हल्के लाल रंग को गहरे लाल टेक्स्ट से भरें .
- ठीक क्लिक करें .
- एक्सेल डुप्लिकेट सेल को हाइलाइट करता है (कॉलम द्वारा)।
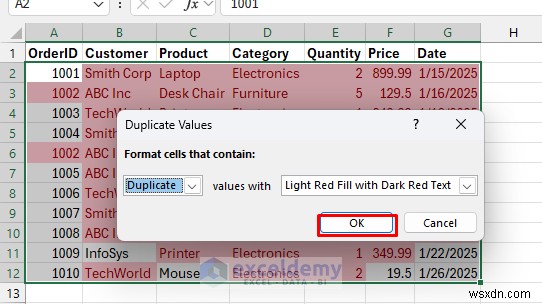
- डेटा पर जाएं टैब>> फ़िल्टर चुनें .
- डुप्लिकेट या अद्वितीय मान दिखाने के लिए सेल रंग के अनुसार फ़िल्टर करें।
- अद्वितीय चयन के लिए स्वचालित डुप्लिकेट के लिए रंग चुनें .
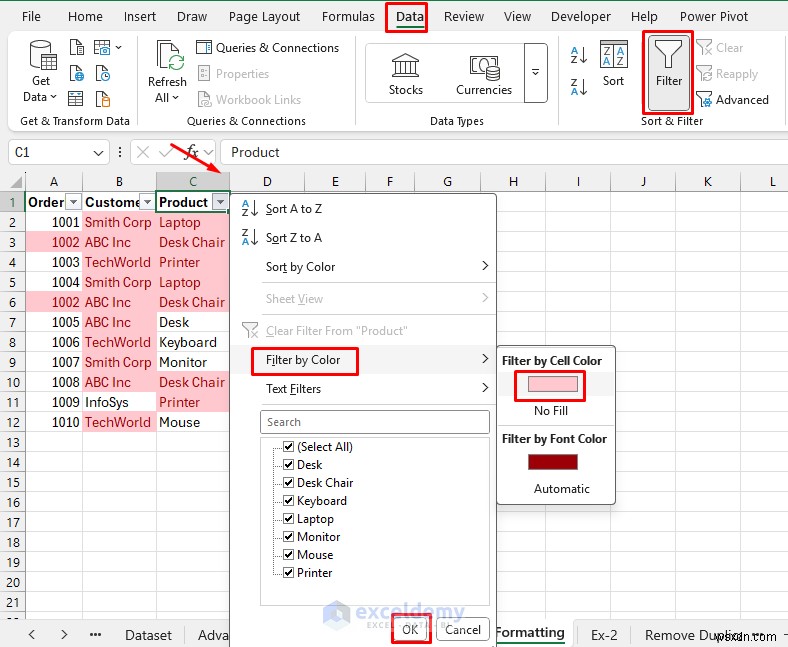 <पी> अद्वितीय: <पी>
<पी> अद्वितीय: <पी> 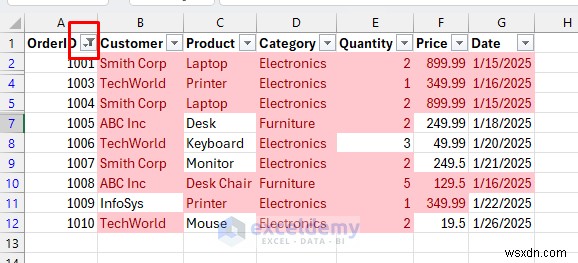 <पी> डुप्लिकेट: <पी>
<पी> डुप्लिकेट: <पी> 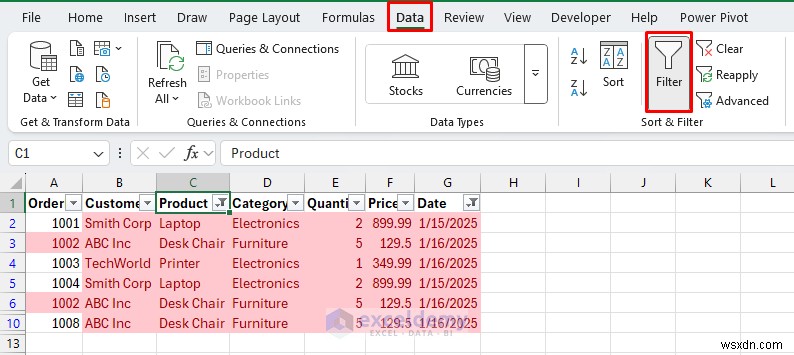 <पी> यदि आप संपूर्ण डुप्लिकेट पंक्तियों को हाइलाइट करना चाहते हैं, तो सूत्र नियम का उपयोग करें जैसे:
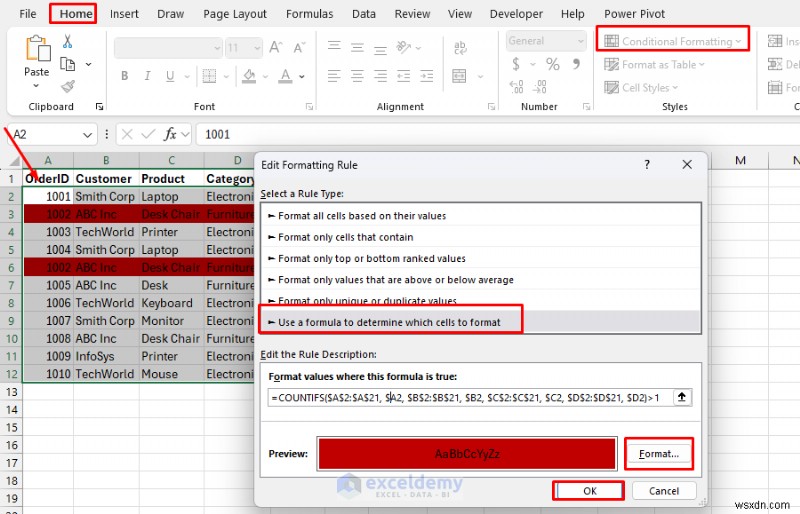
<पी> यदि आप संपूर्ण डुप्लिकेट पंक्तियों को हाइलाइट करना चाहते हैं, तो सूत्र नियम का उपयोग करें जैसे: - घर पर जाएं टैब>> सशर्त स्वरूपण से>>>>नया नियमचुनें .
- चुनें कौन से सेल को फ़ॉर्मेट करना है यह निर्धारित करने के लिए एक सूत्र का उपयोग करें .
- निम्न सूत्र डालें:
=COUNTIFS($A$2:$A$12, $A2, $B$2:$B$12, $B2, $C$2:$C$12, $C2, $D$2:$D$12, $D2, $E$2:$E$12, $E2, $F$2:$F$12, $F2, $G$2:$G$12, $G2)>1
- भरण रंग चुनें.
- ठीक क्लिक करें .
 <पी> फायदे:
<पी> फायदे: - हटाने से पहले डुप्लिकेट को दृश्य रूप से पहचानता है।
- सभी डेटा को सुरक्षित रखता है।
- चयनात्मक निष्कासन की अनुमति देता है।
- सभी एक्सेल संस्करणों में काम करता है।
- डुप्लिकेट पैटर्न को समझने में मदद करता है।
- बहु-चरणीय प्रक्रिया.
- मैन्युअल फ़िल्टरिंग की आवश्यकता है।
- स्वचालित रूप से अपडेट नहीं हो रहा है।
- यदि डेटा बदलता है तो फ़िल्टर को फिर से लागू करना होगा।
6. पिवोट टेबल विधि
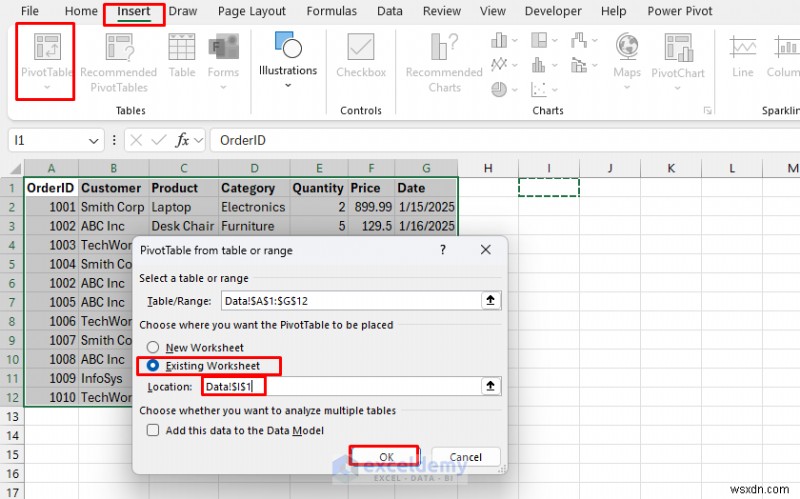
<पी> पिवट तालिकाएँ स्वाभाविक रूप से डेटा एकत्र करती हैं, प्रक्रिया में डुप्लिकेट को प्रभावी ढंग से हटा देती हैं। <पी> कदम:- अपना डेटा चुनें.
- सम्मिलित करें पर जाएं टैब>> पिवोटटेबल चुनें .
- मौजूदा वर्कशीट का चयन करें और स्थान.
- ठीक क्लिक करें .
- पिवोटटेबल फ़ील्ड सूची से;
- इन फ़ील्ड को पंक्तियों पर खींचें :
- ऑर्डर आईडी, ग्राहक, उत्पाद, श्रेणी, दिनांक .
- इन फ़ील्ड को मान पर खींचें :
- मात्रा, कीमत .
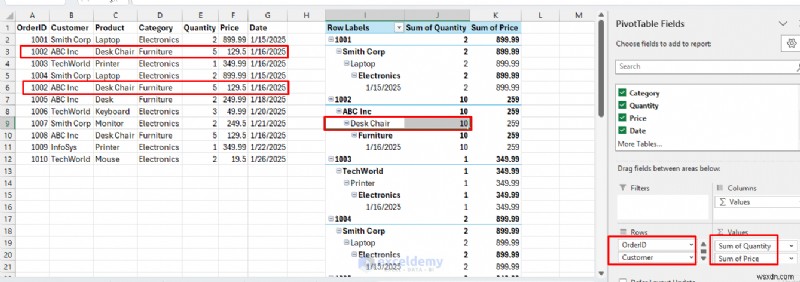 <पी> मात्रा (5+5=10) और कीमत (129.5+129.5=259) का योग दिखाते हुए, डुप्लिकेट पंक्तियों (3 और 6) को जोड़ दिया गया है। <पी> यदि आप डुप्लिकेट उत्पाद और ग्राहक दिखाने के लिए ऑर्डरआईडी को बाहर करना चाहते हैं:
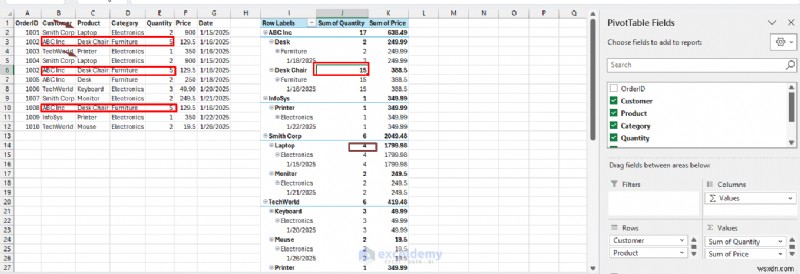
<पी> मात्रा (5+5=10) और कीमत (129.5+129.5=259) का योग दिखाते हुए, डुप्लिकेट पंक्तियों (3 और 6) को जोड़ दिया गया है। <पी> यदि आप डुप्लिकेट उत्पाद और ग्राहक दिखाने के लिए ऑर्डरआईडी को बाहर करना चाहते हैं: - ऑर्डर आईडी हटाएं पंक्तियों से क्षेत्र पहले.
- परिणामस्वरूप पिवट तालिका केवल उन लेनदेन को दिखाएगी जहां ऑर्डरआईडी को छोड़कर सब कुछ समान है।
 <पी> फायदे:
<पी> फायदे: - डुप्लिकेट डेटा को केवल हटाने के बजाय उसका सारांश प्रस्तुत कर सकते हैं।
- बड़े डेटासेट को कुशलतापूर्वक संभालता है।
- संख्यात्मक मानों को स्वचालित रूप से एकत्रित करता है।
- पिवोट टेबल्स की बुनियादी समझ की आवश्यकता है।
- निष्कर्षण के बाद आगे स्वरूपण की आवश्यकता हो सकती है।
- डिफ़ॉल्ट रूप से संख्यात्मक मान एकत्र करता है (कुछ फ़ील्ड के लिए वांछित नहीं हो सकता है)।
7. काउंटिफ़ हेल्पर कॉलम
<पी> यह विधि प्रत्येक रिकॉर्ड की पहली घटनाओं की पहचान करने के लिए एक कॉलम जोड़ती है। <पी> कदम:- शीर्षक "डुप्लिकेट चेक" के साथ एक सहायक कॉलम (कॉलम एच) जोड़ें।
- अद्वितीय पंक्तियों की पहचान करने के लिए एक सूत्र का उपयोग करें।
- केवल अद्वितीय रिकॉर्ड देखने के लिए उचित मानों को फ़िल्टर करें।
- सेल H2 का चयन करें, और यह सूत्र दर्ज करें।
=IF((COUNTIFS($A$2:$A$12, $A2, $B$2:$B$12, $B2, $C$2:$C$12, $C2, $D$2:$D$12, $D2, $E$2:$E$12, $E2, $F$2:$F$12, $F2, $G$2:$G$12, $G2))=1, "Unique","Duplicate")<पी>
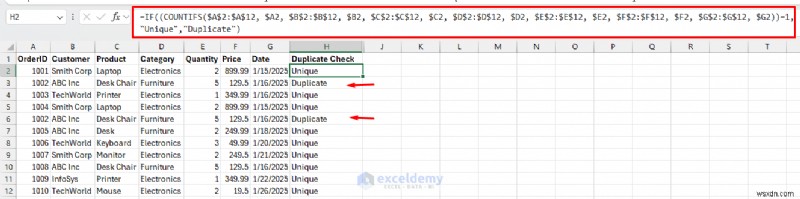 <पी> यह सूत्र उन डुप्लिकेट को चिह्नित करता है जहां पूरी पंक्ति डुप्लिकेट होती है। <पी> ऑर्डर आईडी को अनदेखा करना: ऑर्डरआईडी की परवाह किए बिना, लेनदेन विवरण के आधार पर डुप्लिकेट की पहचान करना:
<पी> यह सूत्र उन डुप्लिकेट को चिह्नित करता है जहां पूरी पंक्ति डुप्लिकेट होती है। <पी> ऑर्डर आईडी को अनदेखा करना: ऑर्डरआईडी की परवाह किए बिना, लेनदेन विवरण के आधार पर डुप्लिकेट की पहचान करना: =IF((COUNTIFS($B$2:$B$12, $B2, $C$2:$C$12, $C2, $D$2:$D$12, $D2, $E$2:$E$12, $E2, $F$2:$F$12, $F2, $G$2:$G$12, $G2))=1, "Unique","Duplicate")<पी>
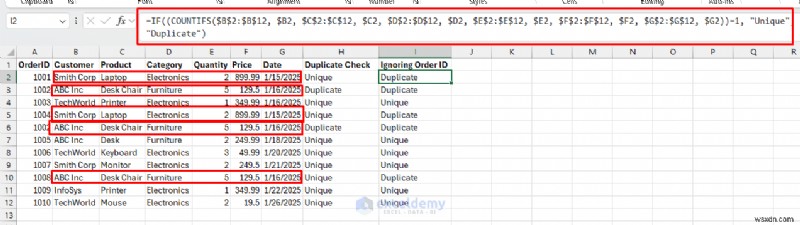 <पी> यह सूत्र पंक्तियों 2,3,5,6, और 10 को "डुप्लिकेट" के रूप में चिह्नित करता है क्योंकि वे लेनदेन विवरण की नकल करते हैं। <पी> फायदे:
<पी> यह सूत्र पंक्तियों 2,3,5,6, और 10 को "डुप्लिकेट" के रूप में चिह्नित करता है क्योंकि वे लेनदेन विवरण की नकल करते हैं। <पी> फायदे: - दिखाता है कि कौन से रिकॉर्ड डुप्लिकेट हैं और मूल डेटा रखता है।
- जटिल परिस्थितियों के अनुसार अनुकूलित किया जा सकता है।
- पहचानता है कि कौन सी पंक्तियाँ डुप्लिकेट हैं।
- एक अतिरिक्त कॉलम की आवश्यकता है।
- कई स्तंभों के लिए सूत्र जटिल हो सकता है।
- यदि डेटा बदलता है तो समायोजित करने की आवश्यकता है।
- नए डेटा के लिए इसे कॉपी किया जाना चाहिए।
8. फॉर्मूला-आधारित निष्कर्षण (सूचकांक/मैच या फ़िल्टर)
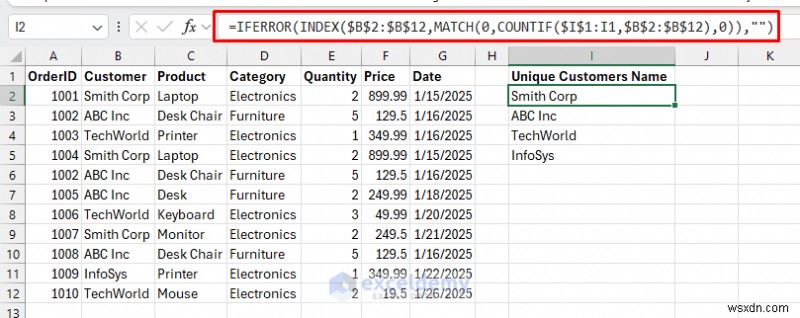
<पी> उन्नत उपयोगकर्ताओं के लिए, INDEX, MATCH और अन्य फ़ंक्शन के संयोजन अद्वितीय मान निकाल सकते हैं। <पी> INDEX/MATCH (पुराने एक्सेल संस्करण) का उपयोग करें: एक अलग स्थान के लिए अद्वितीय ग्राहक नाम निकालने के लिए।- एक सेल का चयन करें और निम्नलिखित सूत्र डालें।
=IFERROR(INDEX($B$2:$B$12,MATCH(0,COUNTIF($I$1:I1,$B$2:$B$12),0)),"")<पी>
 <पी> फ़िल्टर का उपयोग करें (एक्सेल 365/2021): सभी कॉलम रखते हुए अद्वितीय रिकॉर्ड निकालने के लिए।
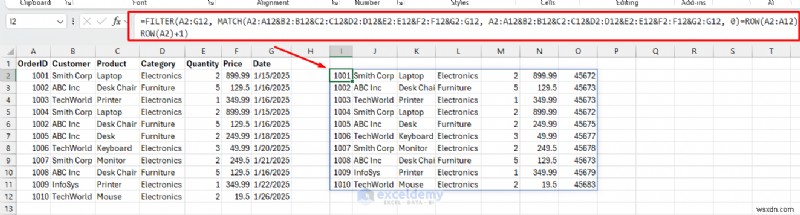
<पी> फ़िल्टर का उपयोग करें (एक्सेल 365/2021): सभी कॉलम रखते हुए अद्वितीय रिकॉर्ड निकालने के लिए। - एक सेल का चयन करें और निम्नलिखित सूत्र डालें।
=FILTER(A2:G12, MATCH(A2:A12&B2:B12&C2:C12&D2:D12&E2:E12&F2:F12&G2:G12, A2:A12&B2:B12&C2:C12&D2:D12&E2:E12&F2:F12&G2:G12, 0)=ROW(A2:A12)-ROW(A2)+1)<पी>
 <पी> फायदे:
<पी> फायदे: - अत्यधिक अनुकूलन योग्य।
- जब अन्य तरीके विफल हो जाते हैं तो काम करता है।
- जटिल तर्क को शामिल कर सकते हैं।
- स्रोत डेटा के लिए गैर-विनाशकारी।
- स्रोत डेटा परिवर्तनों के साथ गतिशील रूप से अपडेट होता है।
- उन्नत एक्सेल ज्ञान की आवश्यकता है।
- कार्यान्वयन और रखरखाव अधिक जटिल।
- पुराने एक्सेल संस्करणों में सरणी सूत्रों की आवश्यकता हो सकती है।
- बड़े डेटासेट के लिए संसाधन-गहन हो सकता है।