Elasticsearch 5 में सबसे बढ़िया नई सुविधाओं में से एक इनेस्ट नोड है, जो Elasticsearch क्लस्टर में कुछ लॉगस्टैश-शैली प्रसंस्करण जोड़ता है, इसलिए इसे करने के लिए किसी अन्य सेवा और/या बुनियादी ढांचे की आवश्यकता के बिना अनुक्रमित होने से पहले डेटा को रूपांतरित किया जा सकता है। कुछ समय पहले, हमने लॉगस्टैश के साथ सीएसवी फाइलों को पार्स करने के तरीके पर एक त्वरित ब्लॉग पोस्ट किया था, इसलिए मैं तुलना के लिए इसका अंतर्ग्रहण पाइपलाइन संस्करण प्रदान करना चाहता हूं।
हम यहां जो दिखाएंगे वह फाइलबीट का उपयोग करके एक इंजेस्ट पाइपलाइन में डेटा शिप करने, इसे इंडेक्स करने और किबाना के साथ इसकी कल्पना करने का एक उदाहरण है।
डेटा
वहाँ मुफ्त डेटा के लिए बहुत सारे महान स्रोत हैं, लेकिन चूंकि ऑब्जेक्टरॉकेट में हम में से अधिकांश ऑस्टिन, TX में हैं, हम data.austintexas.gov से कुछ डेटा का उपयोग करने जा रहे हैं। रेस्तरां निरीक्षण डेटा सेट एक अच्छे आकार का डेटा सेट है जिसमें हमें वास्तविक दुनिया का उदाहरण देने के लिए पर्याप्त प्रासंगिक जानकारी है।
आपको डेटा की संरचना का अंदाजा लगाने के लिए इस डेटा सेट की कुछ पंक्तियाँ नीचे दी गई हैं:
Restaurant Name,Zip Code,Inspection Date,Score,Address,Facility ID,Process Description
Westminster Manor,78731,07/21/2015,96,"4100 JACKSON AVE
AUSTIN, TX 78731
(30.314499, -97.755166)",2800365,Routine Inspection
Wieland Elementary,78660,10/02/2014,100,"900 TUDOR HOUSE RD
AUSTIN, TX 78660
(30.422862, -97.640183)",10051637,Routine Inspection
डीओएच ... यह प्रति प्रविष्टि मामले में एक अच्छी, मैत्रीपूर्ण, एकल पंक्ति नहीं होगी, लेकिन यह ठीक है। जैसा कि आप देखने वाले हैं, फाइलबीट में मल्टीलाइन प्रविष्टियों को संभालने और डेटा में दबी नई लाइनों के आसपास काम करने की कुछ अंतर्निहित क्षमता है।
संपादकीय नोट:मैं कुछ "हिच" के साथ एक अच्छे सरल उदाहरण की योजना बना रहा था, लेकिन अंत में, मैंने सोचा कि कुछ ऐसे उपकरण देखना दिलचस्प हो सकता है जो इलास्टिक स्टैक आपको इन परिदृश्यों के आसपास काम करने के लिए देता है।
फ़ाइलबीट सेट करना
पहला कदम फाइलबीट को अपने इलास्टिक्स खोज क्लस्टर में डेटा शिपिंग शुरू करने के लिए तैयार करना है। एक बार जब आप फ़ाइलबीट डाउनलोड कर लेते हैं (अपने ईएस क्लस्टर के समान संस्करण का उपयोग करने का प्रयास करें) और निकाले जाने के बाद, शामिल filebeat.yml कॉन्फ़िगरेशन फ़ाइल के माध्यम से इसे स्थापित करना बेहद आसान है। हमारे परिदृश्य के लिए, यहां वह कॉन्फ़िगरेशन है जिसका मैं उपयोग कर रहा हूं।
filebeat.prospectors:
- input_type: log
paths:
- /Path/To/logs/*.csv
# Ignore the first line with column headings
exclude_lines: ["^Restaurant Name,"]
# Identifies the last two columns as the end of an entry and then prepends the previous lines to it
multiline.pattern: ',\d+,[^\",]+$'
multiline.negate: true
multiline.match: before
#================================ Outputs =====================================
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["https://dfw-xxxxx-0.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-1.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-2.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-3.es.objectrocket.com:xxxxx"]
pipeline: "inspectioncsvs"
# Optional protocol and basic auth credentials.
username: "esuser"
password: "supersecretpassword"
यहाँ सब कुछ बहुत सीधा है; आपके पास यह निर्दिष्ट करने के लिए एक अनुभाग है कि इनपुट फ़ाइलों को कहाँ और कैसे हथियाना है और यह निर्दिष्ट करने के लिए एक अनुभाग है कि डेटा कहाँ भेजा जाए। केवल एक ही भाग जिसे मैं विशेष रूप से बुलाऊंगा, वे हैं मल्टीलाइन बिट और इलास्टिक्स खोज कॉन्फ़िगरेशन टुकड़ा।
चूंकि इस डेटा सेट के लिए प्रारूपण अत्यधिक सख्त नहीं है, दोहरे उद्धरण चिह्नों के असंगत उपयोग और कई नई पंक्तियों के छिड़काव के साथ, सबसे अच्छा विकल्प एक प्रविष्टि के अंत की तलाश करना था, जिसमें एक संख्यात्मक आईडी के बाद एक निरीक्षण प्रकार होता है बिना ज्यादा बदलाव या डबल-कोट्स/न्यूलाइन के। वहां से, फाइलबीट किसी भी बेजोड़ लाइनों को कतारबद्ध करेगा और उन्हें पैटर्न से मेल खाने वाली अंतिम पंक्ति में जोड़ देगा। यदि आपका डेटा साफ-सुथरा है और प्रति प्रविष्टि प्रारूप में एक साधारण रेखा से चिपक जाता है, तो आप बहु-पंक्ति सेटिंग्स को काफी हद तक अनदेखा कर सकते हैं।
Elasticsearch आउटपुट अनुभाग को देखते हुए, यह पाइपलाइन के नाम के एक छोटे से जोड़ के साथ मानक Elasticsearch सेटिंग्स है जिसे आप पाइपलाइन के साथ उपयोग करना चाहते हैं:निर्देश। यदि आप ऑब्जेक्टरॉकेट सेवा पर हैं, तो आप यूआई में "कनेक्ट" टैब से आउटपुट स्निपेट को पकड़ सकते हैं, जो सभी सही मेजबानों के साथ पहले से आ जाएगा, और बस पाइपलाइन लाइन जोड़ें और अपना उपयोगकर्ता और पासवर्ड भरें . साथ ही, सुनिश्चित करें कि आपने अपने सिस्टम के आईपी को अपने क्लस्टर के एसीएल में जोड़ा है यदि आपने पहले से ऐसा नहीं किया है।
इनजेस्ट पाइपलाइन बनाना
अब जब हमारे पास इनपुट डेटा और फाइलबीट जाने के लिए तैयार है, तो हम अपनी अंतर्ग्रहण पाइपलाइन बना सकते हैं और उसमें बदलाव कर सकते हैं। पाइपलाइन को जिन मुख्य कार्यों को करने की आवश्यकता है वे हैं:
- सीएसवी सामग्री को सही क्षेत्रों में विभाजित करें
- निरीक्षण स्कोर को पूर्णांक में बदलें
@timestampसेट करें फ़ील्ड- कुछ अन्य डेटा स्वरूपण साफ़ करें
यहां एक पाइपलाइन है जो यह सब कर सकती है:
PUT _ingest/pipeline/inspectioncsvs
{
"description" : "Convert Restaurant inspections csv data to indexed data",
"processors" : [
{
"grok": {
"field": "message",
"patterns": ["%{REST_NAME:RestaurantName},%{REST_ZIP:ZipCode},%{MONTHNUM2:InspectionMonth}/%{MONTHDAY:InspectionDay}/%{YEAR:InspectionYear},%{NUMBER:Score},\"%{DATA:StreetAddress}\n%{DATA:City},?\\s+%{WORD:State}\\s*%{NUMBER:ZipCode2}\\s*\n\\(?%{DATA:Location}\\)?\",%{NUMBER:FacilityID},%{DATA:InspectionType}$"],
"pattern_definitions": {
"REST_NAME": "%{DATA}|%{QUOTEDSTRING}",
"REST_ZIP": "%{QUOTEDSTRING}|%{NUMBER}"
}
}
},
{
"grok": {
"field": "ZipCode",
"patterns": [".*%{ZIP:ZipCode}\"?$"],
"pattern_definitions": {
"ZIP": "\\d{5}"
}
}
},
{
"convert": {
"field" : "Score",
"type": "integer"
}
},
{
"set": {
"field" : "@timestamp",
"value" : "//"
}
},
{
"date" : {
"field" : "@timestamp",
"formats" : ["yyyy/MM/dd"]
}
}
],
"on_failure" : [
{
"set" : {
"field" : "error",
"value" : " - Error processing message - "
}
}
]
}
लॉगस्टैश के विपरीत, निगलना पाइपलाइन (इस लेखन के समय) में एक सीएसवी प्रोसेसर/प्लगइन नहीं है, इसलिए आपको सीएसवी को स्वयं बदलने की आवश्यकता होगी। मैंने भारी भारोत्तोलन करने के लिए एक ग्रोक प्रोसेसर का उपयोग किया, क्योंकि प्रत्येक पंक्ति में केवल कुछ कॉलम थे। कई और कॉलम वाले डेटा के लिए, ग्रोक प्रोसेसर सुंदर बालों वाला हो सकता है, इसलिए एक अन्य विकल्प स्प्लिट प्रोसेसर और कुछ दर्द रहित स्क्रिप्टिंग का उपयोग करके लाइन को अधिक पुनरावृत्त फैशन में संसाधित करना है। आप दूसरा ग्रोक प्रोसेसर भी देख सकते हैं, जो इस डेटा सेट में ज़िप कोड दर्ज किए गए दो अलग-अलग तरीकों से निपटने के लिए है।
डिबग उद्देश्यों के लिए, मैंने एक सामान्य on_failure अनुभाग शामिल किया जो सभी त्रुटियों को पकड़ेगा और प्रिंट करेगा कि किस प्रकार का प्रोसेसर विफल हुआ और क्या संदेश है जिसने पाइपलाइन को तोड़ दिया। यह डीबग रास्ता आसान बनाता है। मैं किसी भी दस्तावेज़ के लिए अपनी अनुक्रमणिका से पूछताछ कर सकता हूं जिसमें त्रुटि सेट है और फिर अनुकरण एपीआई के साथ डीबग कर सकता है। उस पर अभी और…
पाइपलाइन का परीक्षण
अब जब हमने अपनी अंतर्ग्रहण पाइपलाइन को कॉन्फ़िगर कर लिया है, तो आइए इसका परीक्षण करें और इसे सिम्युलेट एपीआई के साथ चलाएं। सबसे पहले आपको एक नमूना दस्तावेज़ की आवश्यकता होगी। आप इसे दो तरीकों से कर सकते हैं। आप या तो पाइपलाइन सेटिंग के बिना फ़ाइलबीट चला सकते हैं और फिर इलास्टिक्स खोज से एक असंसाधित दस्तावेज़ प्राप्त कर सकते हैं, या आप इलास्टिक्स खोज अनुभाग पर टिप्पणी करके और yml फ़ाइल में निम्नलिखित जोड़कर कंसोल आउटपुट सक्षम के साथ फ़ाइलबीट चला सकते हैं:
output.console:
pretty: true
यहाँ एक नमूना दस्तावेज़ है जिसे मैंने अपने परिवेश से लिया है:
POST _ingest/pipeline/inspectioncsvs/_simulate
{
"docs" : [
{
"_index": "inspections",
"_type": "log",
"_id": "AVpsUYR_du9kwoEnKsSA",
"_score": 1,
"_source": {
"@timestamp": "2017-03-31T18:22:25.981Z",
"beat": {
"hostname": "systemx",
"name": "RestReviews",
"version": "5.1.1"
},
"input_type": "log",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"offset": 2109798,
"source": "/Path/to/my/logs/Restaurant_Inspection_Scores.csv",
"tags": [
"debug",
"reviews"
],
"type": "log"
}
}
]
}
और प्रतिक्रिया (मैंने इसे उन क्षेत्रों में काट दिया है जिन्हें हम सेट करने का प्रयास कर रहे थे):
{
"docs": [
{
"doc": {
"_id": "AVpsUYR_du9kwoEnKsSA",
"_type": "log",
"_index": "inspections",
"_source": {
"InspectionType": "Routine Inspection",
"ZipCode": "78660",
"InspectionMonth": "10",
"City": "AUSTIN",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"RestaurantName": "Wieland Elementary",
"FacilityID": "10051637",
"Score": 100,
"StreetAddress": "900 TUDOR HOUSE RD",
"State": "TX",
"InspectionDay": "02",
"InspectionYear": "2014",
"ZipCode2": "78660",
"Location": "30.422862, -97.640183"
},
"_ingest": {
"timestamp": "2017-03-31T20:36:59.574+0000"
}
}
}
]
}
पाइपलाइन निश्चित रूप से सफल रही, लेकिन सबसे महत्वपूर्ण बात यह है कि सभी डेटा सही जगह पर हैं।
फ़ाइलबीट चलाना
फाइलबीट चलाने से पहले, हम एक आखिरी काम करेंगे। यह हिस्सा पूरी तरह से वैकल्पिक है यदि आप केवल अंतर्ग्रहण पाइपलाइन के साथ सहज होना चाहते हैं, लेकिन यदि आप स्थान फ़ील्ड का उपयोग करना चाहते हैं जिसे हम ग्रोक प्रोसेसर में भू-बिंदु के रूप में सेट करते हैं, तो आपको मैपिंग को फ़ाइलबीट में जोड़ना होगा। template.json फ़ाइल, गुण अनुभाग में निम्नलिखित जोड़कर:
"Location": {
"type": "geo_point"
},
अब जबकि यह बात खत्म हो गई है, हम ./filebeat -e -c filebeat.yml -d “elasticsearch” चलाकर फ़ाइलबीट को सक्रिय कर सकते हैं।
डेटा का उपयोग करना
GET /filebeat-*/_count
{}
{
"count": 25081,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
}
}
यह एक अच्छा संकेत है! आइए देखें कि क्या हमसे कोई त्रुटि हुई है:
GET /filebeat-*/_search
{
"query": {
"exists" : { "field" : "error" }
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
एक और अच्छा संकेत!
अब हम किबाना में अपने डेटा की कल्पना करने और दिखाने के लिए पूरी तरह तैयार हैं। हम दूसरी बार किबाना डैशबोर्ड बनाकर चल सकते हैं, लेकिन यह देखते हुए कि हमारे पास तिथियां, रेस्तरां के नाम, स्कोर और स्थान हैं, हमें कुछ शानदार विज़ुअलाइज़ेशन बनाने के लिए जाने की बहुत स्वतंत्रता है।
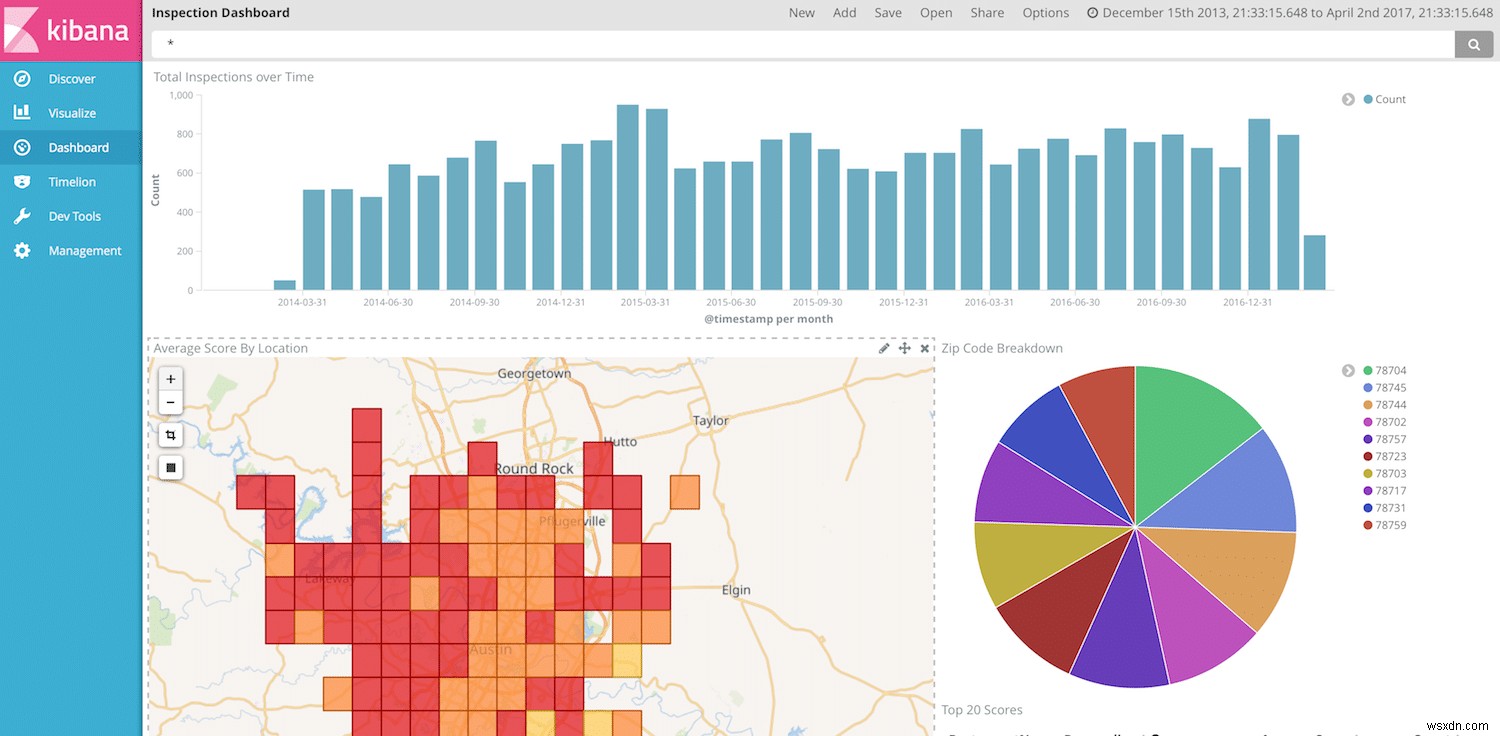
अंतिम नोट
एक बार फिर, निगलना पाइपलाइन बहुत शक्तिशाली है और परिवर्तनों को बहुत आसानी से संभाल सकती है। आप अपने सभी प्रसंस्करण को इलास्टिक्स खोज में स्थानांतरित कर सकते हैं और पाइपलाइन में कहीं लॉगस्टैश की आवश्यकता के बिना, अपने मेजबानों पर केवल हल्के बीट्स का उपयोग कर सकते हैं। हालाँकि, लॉगस्टैश की तुलना में अभी भी अंतर्ग्रहण नोड में कुछ अंतराल हैं। उदाहरण के लिए, निगलना पाइपलाइन में उपलब्ध प्रोसेसर की संख्या अभी भी सीमित है, इसलिए CSV को पार्स करने जैसे सरल कार्य लॉगस्टैश की तरह आसान नहीं हैं। ऐसा लगता है कि Elasticsearch टीम नियमित रूप से नए प्रोसेसर जारी कर रही है, इसलिए यह उम्मीद की जा रही है कि मतभेदों की सूची छोटी और छोटी होती जाएगी।