परिचय
ऐसा लगता है कि दुनिया एक्सेल द्वारा शासित है। मुझे अपने डेटा इंजीनियरिंग कार्य में यह देखकर आश्चर्य हुआ है कि मेरे कितने सहकर्मी निर्णय लेने के लिए एक महत्वपूर्ण उपकरण के रूप में एक्सेल का उपयोग कर रहे हैं। हालांकि मैं एमएस ऑफिस और उनकी एक्सेल स्प्रेड शीट का बहुत बड़ा प्रशंसक नहीं हूं, फिर भी मैं आपको बड़ी एक्सेल स्प्रेड शीट को प्रभावी ढंग से संभालने के लिए एक साफ-सुथरी तरकीब दिखाऊंगा।
इसे कैसे करें..
इससे पहले कि हम सीधे कार्यक्रम में शामिल हों, आइए हम पंडों के साथ एक्सेल स्प्रेडशीट से निपटने के बारे में कुछ बुनियादी बातों को समझें।
1. स्थापना। आगे बढ़ें और openpyxl और xlwt इंस्टॉल करें। यदि आप सुनिश्चित नहीं हैं कि यह स्थापित है या नहीं, केवल पाइथॉन टर्मिनल से पाइप फ्रीज या पाइप सूची का उपयोग करके उपलब्ध पैकेज नहीं है।
हम पहले डेटा के टपल पास करके एक्सेल स्प्रेड शीट बनाएंगे। फिर हम डेटा को पांडा डेटाफ्रेम में लोड करेंगे। हम अंत में एक नई कार्यपुस्तिका में डेटाफ़्रेम डेटा लिखेंगे।
आयात xlsxwriterpd के रूप में पांडा आयात करें
2. छोटे डेटा के साथ एक्सेल स्प्रेड शीट बनाएं। एक्सेल स्प्रेडशीट में डिक्शनरी डेटा लिखने के लिए हमारे पास एक छोटा सा फंक्शन होगा। प्रत्येक चरण में सभी कोड तर्क परिभाषित होते हैं।
# फ़ंक्शन:write_data_to_filesdef write_data_to_files(inp_data, inp_file_name):"""फ़ंक्शन:इस कोडर को पास किए गए डेटा के साथ एक सीएसवी फ़ाइल बनाएं:inp_data:लक्ष्य पर लिखा जाने वाला टपल डेटा filefile_name:डेटा रिटर्न को स्टोर करने के लिए लक्ष्य फ़ाइल नाम :nonassumption :बनाई जाने वाली फाइल और यह कोड एक ही डायरेक्टरी में है।"""प्रिंट(f" *** डेटा को - {inp_file_name}")# एक वर्कबुक बनाएं। वर्कबुक =xlsxwriter.Workbook(inp_file_name)# ऐड एक वर्कशीट.वर्कशीट =वर्कबुक.ऐड_वर्कशीट ()# पहले सेल से शुरू करें। पंक्तियाँ और स्तंभ शून्य अनुक्रमित हैं। शीर्षक)पंक्ति +=1# कार्यपुस्तिका को बंद करें।
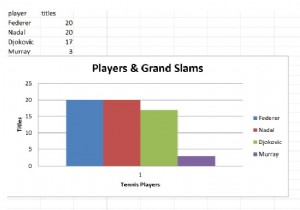
# फंक्शन:एक्सेल_फंक्शन्स_विथ_पांडासडेफ एक्सेल_फंक्शन्स_विथ_पांडास (इनप_फाइल_नाम):""" फंक्शन:उन फंक्शन्स का त्वरित अवलोकन जिन्हें आप पांडासर्ग के साथ एक्सेल पर लागू कर सकते हैं:inp_file_name:इनपुट एक्सेल स्प्रेड शीट। रिटर्न:गैर-अनुमान:इनपुट एक्सेल स्प्रेडशीट और यह कोड एक ही निर्देशिका में हैं """डेटा =pd.read_excel(inp_file_name)# प्रिंट टॉप 2 रोप्रिंट (f" *** की शीर्ष 2 पंक्तियों को प्रदर्शित करना - {inp_file_name} \n {data.head ()} ")# डेटा टाइपप्रिंट को देखें ( f" *** {inp_file_name} - {data.info ()}) के बारे में जानकारी प्रदर्शित करना)# एक नई स्प्रेडशीट "शीट2" बनाएं और उसमें डेटा लिखें।new_players_info =pd.DataFrame(data=[{"players":" न्यू रोजर फेडरर", "शीर्षक":20}, {"खिलाड़ी":"नया राफेल नडाल", "शीर्षक":20}, {"खिलाड़ी":"नया नोवाक जोकोविच", "शीर्षक":17}, {" खिलाड़ी":"नया एंडी मरे", "शीर्षक":3}], कॉलम =["खिलाड़ी", "शीर्षक"]) new_data =pd.ExcelWriter (inp_file_name) new_players_info.to_excel (new_data, शीट_नाम ="शीट 2") अगर __name__ =='__main__':# अपनी फ़ाइल का नाम और datafile_na परिभाषित करें me ="temporary_file.xlsx"# स्टोरेजफाइल_डेटा के लिए टपल डेटा =(['खिलाड़ी', 'शीर्षक'], ['फेडरर', 20], ['नडाल', 20], ['जोकोविच', 17], [' मुर्रे', 3])# file_data को file_name में लिखें# write_data_to_files(file_data, file_name)# # एक्सेल फाइल को पांडा में पढ़ें और फंक्शन लागू करें।# excel_functions_with_pandas(file_name)
if __name__ =='__main__':# अपनी फ़ाइल का नाम परिभाषित करें और datafile_name ="temporary_file.xlsx"# tuple data for storagefile_data =(['player', 'titles'], ['Federer', 20], [ 'नडाल', 20], ['जोकोविच', 17], ['मरे', 3])# file_data को file_name में लिखें# write_data_to_files(file_data, file_name)# # एक्सेल फ़ाइल को पांडा में पढ़ें और फ़ंक्शन लागू करें।# excel_functions_with_pandas( file_name)
आउटपुट
*** को डेटा लिखना - temper_file.xlsx*** को डेटा लिखना पूरा किया - अस्थायी_फाइल.xlsx*** की शीर्ष 2 पंक्तियों को प्रदर्शित करना - अस्थायी_फाइल। xlsxplayer खिताब0 फेडरर 201 नडाल 202 जोकोविच 173 मरे 3<वर्ग ' pandas.core.frame.DataFrame'>RangeIndex:4 प्रविष्टियां, 0 से 3डेटा कॉलम (कुल 2 कॉलम):# कॉलम नॉन-नल काउंट डीटाइप ------------------- ---- -----0 प्लेयर 4 नॉन-नल ऑब्जेक्ट1 टाइटल 4 नॉन-नल int64dtypes:int64(1), ऑब्जेक्ट(1)मेमोरी यूसेज:192.0+ बाइट्स*** Temporary_file.xlsx के बारे में जानकारी प्रदर्शित करना - कोई नहीं
अब जब बड़ी सीएसवी फाइलों से निपटते हैं तो हमारे पास टुकड़ों में उन्हें संसाधित करने के लिए बहुत सारे विकल्प होते हैं, हालांकि एक्सेल स्प्रेड शीट के लिए पांडा डिफ़ॉल्ट रूप से खंड विकल्प प्रदान नहीं करते हैं।
तो अगर आप एक्सेल स्प्रेड शीट को टुकड़ों में प्रोसेस करना चाहते हैं तो नीचे दिया गया प्रोग्राम काफी मददगार है।
उदाहरण
def global_excel_to_db_chunks(file_name, nrows):"""फ़ंक्शन:एक्सेल स्प्रेडशीट को चंक्सर्ग्स में हैंडल करें:inp_file_name:इनपुट एक्सेल स्प्रेड शीट। ]i_chunk =0# पहली पंक्ति हैडर है। हम इसे पहले ही पढ़ चुके हैं, इसलिए हम इसे छोड़ देते हैं।skiprows =1df_header =pd.read_excel(file_name, nrows=1)जबकि True:df_chunk =pd.read_excel(file_name, nrows=nrows, Skiprows=skiprows, Header=None)skiprows + =nrows# जब कोई डेटा नहीं होता है, तो हम जानते हैं कि हम लूप से बाहर निकल सकते हैं। यदि नहीं df_chunk.shape[0]:breakelse:print(f" ** {df_chunk.shape[0] के साथ खंड संख्या {i_chunk} पढ़ना } Rows")# Print(f" *** Reading खंड {i_chunk} ({df_chunk.shape[0]} Rows)")chunks.append(df_chunk)i_chunk +=1df_chunks =pd.concat(chunks)# का नाम बदलें शीर्षलेख के साथ भाग को जोड़ने के लिए कॉलम। df_header, df_chunks])print(f' *** पठन को टुकड़ों में पूरा किया जाता है...')अगर __name__ =='__main__':print(f" *** एक्सेल स्प्रेडशीट पर आँकड़े इकट्ठा करना और प्रदर्शित करना ***") file_name ='नमूना-बिक्री-डेटा-एक्सेल.xls'stats =pd.read_excel(file_name)print(f" ** स्प्रैडशीट में कुल पंक्तियां हैं - {len(stat s.index)} Rows")# एक बार में 1000 पंक्तियों के टुकड़ों में एक्सेल फ़ाइल को प्रोसेस करें।global_excel_to_db_chunks(file_name, 1000)
*** एक्सेल स्प्रेडशीट पर आंकड़े एकत्र करना और प्रदर्शित करना ***** स्प्रेडशीट में कुल पंक्तियां हैं - 9994 पंक्तियां** 1000 पंक्तियों के साथ खंड संख्या 0 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 1 पढ़ना** खंड पढ़ना 1000 पंक्तियों के साथ संख्या 2** 1000 पंक्तियों के साथ खंड संख्या 3 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 4 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 5 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 6 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 7 पढ़ना ** 1000 पंक्तियों के साथ खंड संख्या 8 पढ़ना** 994 पंक्तियों के साथ खंड संख्या 9 पढ़ना आउटपुट
*** एक्सेल स्प्रेडशीट पर आंकड़े एकत्र करना और प्रदर्शित करना ***** स्प्रेडशीट में कुल पंक्तियां हैं - 9994 पंक्तियां** 1000 पंक्तियों के साथ खंड संख्या 0 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 1 पढ़ना** खंड पढ़ना 1000 पंक्तियों के साथ संख्या 2** 1000 पंक्तियों के साथ खंड संख्या 3 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 4 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 5 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 6 पढ़ना** 1000 पंक्तियों के साथ खंड संख्या 7 पढ़ना ** 1000 पंक्तियों के साथ खंड संख्या 8 पढ़ना** 994 पंक्तियों के साथ खंड संख्या 9 पढ़ना