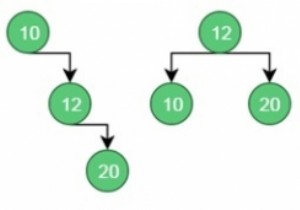
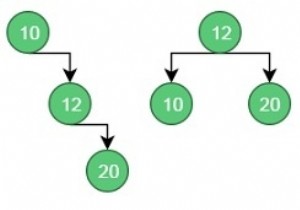
एक द्विदिशात्मक खोज एक खोज तकनीक है जो दो तरह से चलती है। यह उन दो लोगों के साथ काम करता है जो एक साथ चलने वाली खोज करते हैं, पहला स्रोत से लक्ष्य तक और दूसरा लक्ष्य से स्रोत तक पिछड़ी दिशा में। इष्टतम स्थिति में, दोनों खोजें डेटा संरचना के बीच में मिलेंगी।
द्विदिश खोज एल्गोरिथ्म स्रोत (प्रारंभिक नोड) के बीच लक्ष्य नोड के बीच सबसे छोटा रास्ता खोजने के लिए एक निर्देशित ग्राफ पर काम करता है। दो खोजें अपने-अपने स्थानों से शुरू होंगी और जब दो खोजें एक नोड पर मिलती हैं तो एल्गोरिथम रुक जाता है।
द्विपक्षीय दृष्टिकोण का महत्व - यह एक तेज़ तकनीक है, और ग्राफ़ को पार करने के लिए आवश्यक समय में सुधार करती है।
यह दृष्टिकोण उस मामले के लिए कुशल है जब शुरुआती नोड और लक्ष्य नोड अद्वितीय और परिभाषित होते हैं। दोनों दिशाओं के लिए शाखाकरण कारक समान है।
प्रदर्शन के उपाय
-
पूर्णता − यदि दोनों खोजों में BFS का उपयोग किया जाता है, तो द्विदिश खोज पूर्ण हो जाती है।
-
इष्टतमता - यह इष्टतम है यदि BFS का उपयोग खोज के लिए किया जाता है और पथों की लागत एक समान होती है।
-
समय और स्थान की जटिलता − समय और स्थान की जटिलता O(b^{d/2}) . है
उदाहरण
#include <bits/stdc++.h>
using namespace std;
class Graph {
int V;
list<int> *adj;
public:
Graph(int V);
int isIntersecting(bool *s_visited, bool *t_visited);
void addEdge(int u, int v);
void printPath(int *s_parent, int *t_parent, int s,
int t, int intersectNode);
void BFS(list<int> *queue, bool *visited, int *parent);
int biDirSearch(int s, int t);
};
Graph::Graph(int V) {
this->V = V;
adj = new list<int>[V];
};
void Graph::addEdge(int u, int v) {
this->adj[u].push_back(v);
this->adj[v].push_back(u);
};
void Graph::BFS(list<int> *queue, bool *visited,
int *parent) {
int current = queue->front();
queue->pop_front();
list<int>::iterator i;
for (i=adj[current].begin();i != adj[current].end();i++) {
if (!visited[*i]) {
parent[*i] = current;
visited[*i] = true;
queue->push_back(*i);
}
}
};
int Graph::isIntersecting(bool *s_visited, bool *t_visited) {
int intersectNode = -1;
for(int i=0;i<V;i++) {
if(s_visited[i] && t_visited[i])
return i;
}
return -1;
};
void Graph::printPath(int *s_parent, int *t_parent,
int s, int t, int intersectNode) {
vector<int> path;
path.push_back(intersectNode);
int i = intersectNode;
while (i != s) {
path.push_back(s_parent[i]);
i = s_parent[i];
}
reverse(path.begin(), path.end());
i = intersectNode;
while(i != t) {
path.push_back(t_parent[i]);
i = t_parent[i];
}
vector<int>::iterator it;
cout<<"Path Traversed by the algorithm\n";
for(it = path.begin();it != path.end();it++)
cout<<*it<<" ";
cout<<"\n";
};
int Graph::biDirSearch(int s, int t) {
bool s_visited[V], t_visited[V];
int s_parent[V], t_parent[V];
list<int> s_queue, t_queue;
int intersectNode = -1;
for(int i=0; i<V; i++) {
s_visited[i] = false;
t_visited[i] = false;
}
s_queue.push_back(s);
s_visited[s] = true;
s_parent[s]=-1;
t_queue.push_back(t);
t_visited[t] = true;
t_parent[t] = -1;
while (!s_queue.empty() && !t_queue.empty()) {
BFS(&s_queue, s_visited, s_parent);
BFS(&t_queue, t_visited, t_parent);
intersectNode = isIntersecting(s_visited, t_visited);
if(intersectNode != -1) {
cout << "Path exist between " << s << " and "
<< t << "\n";
cout << "Intersection at: " << intersectNode << "\n";
printPath(s_parent, t_parent, s, t, intersectNode);
exit(0);
}
}
return -1;
}
int main() {
int n=15;
int s=0;
int t=14;
Graph g(n);
g.addEdge(0, 4);
g.addEdge(1, 4);
g.addEdge(2, 5);
g.addEdge(3, 5);
g.addEdge(4, 6);
g.addEdge(5, 6);
g.addEdge(6, 7);
g.addEdge(7, 8);
g.addEdge(8, 9);
g.addEdge(8, 10);
g.addEdge(9, 11);
g.addEdge(9, 12);
g.addEdge(10, 13);
g.addEdge(10, 14);
if (g.biDirSearch(s, t) == -1)
cout << "Path don't exist between "
<< s << " and " << t << "\n";
return 0;
} आउटपुट
Path Traversed by the algorithm 0 4 6 7 8 10 14