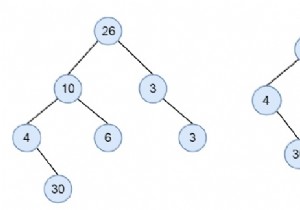
विचार करें कि हमारे पास एक बाइनरी ट्री है। हमें यह पता लगाना है कि पेड़ में आकार 2 या उससे अधिक के कुछ डुप्लिकेट सबट्री हैं या नहीं। मान लीजिए हमारे पास नीचे जैसा एक बाइनरी ट्री है -
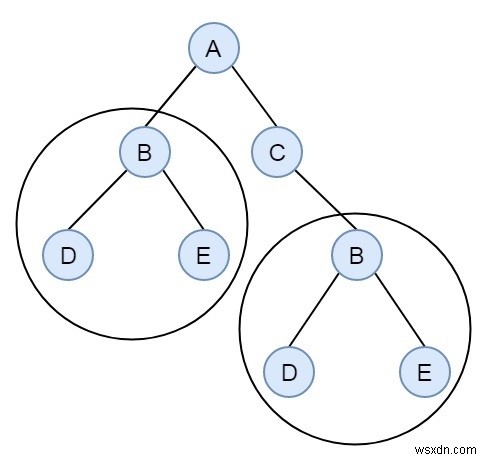
आकार 2 के दो समान उपप्रकार हैं। हम ट्री क्रमांकन और हैशिंग प्रक्रिया का उपयोग करके इस समस्या को हल कर सकते हैं। विचार उपट्री को स्ट्रिंग के रूप में क्रमबद्ध कर रहा है, और उन्हें हैश तालिका में संग्रहीत कर रहा है। एक बार जब हमें एक क्रमबद्ध पेड़ मिल जाता है जो पत्ती नहीं है, पहले से ही हैश टेबल में मौजूद है, तो सही लौटें।
उदाहरण
#include <iostream>
#include <unordered_set>
using namespace std;
const char MARKER = '$';
struct Node {
public:
char key;
Node *left, *right;
};
Node* getNode(char key) {
Node* newNode = new Node;
newNode->key = key;
newNode->left = newNode->right = NULL;
return newNode;
}
unordered_set<string> subtrees;
string duplicateSubtreeFind(Node *root) {
string res = "";
if (root == NULL) // If the current node is NULL, return $
return res + MARKER;
string l_Str = duplicateSubtreeFind(root->left);
if (l_Str.compare(res) == 0)
return res;
string r_Str = duplicateSubtreeFind(root->right);
if (r_Str.compare(res) == 0)
return res;
res = res + root->key + l_Str + r_Str;
if (res.length() > 3 && subtrees.find(res) != subtrees.end()) //if subtree is present, then return blank string return "";
subtrees.insert(res);
return res;
}
int main() {
Node *root = getNode('A');
root->left = getNode('B');
root->right = getNode('C');
root->left->left = getNode('D');
root->left->right = getNode('E');
root->right->right = getNode('B');
root->right->right->right = getNode('E');
root->right->right->left= getNode('D');
string str = duplicateSubtreeFind(root);
if(str.compare("") == 0)
cout << "It has dublicate subtrees of size more than 1";
else
cout << "It has no dublicate subtrees of size more than 1" ;
} आउटपुट
It has dublicate subtrees of size more than 1