हमें RediSearch 2.0 के विकास में पहला मील का पत्थर जारी करने की घोषणा करते हुए खुशी हो रही है। RediSearch एक रीयल-टाइम खोज इंजन है जो आपको विविध प्रकार के जटिल प्रश्नों के उत्तर देने के लिए अपने Redis डेटा को क्वेरी करने देता है।
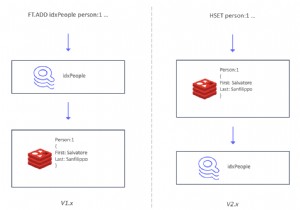
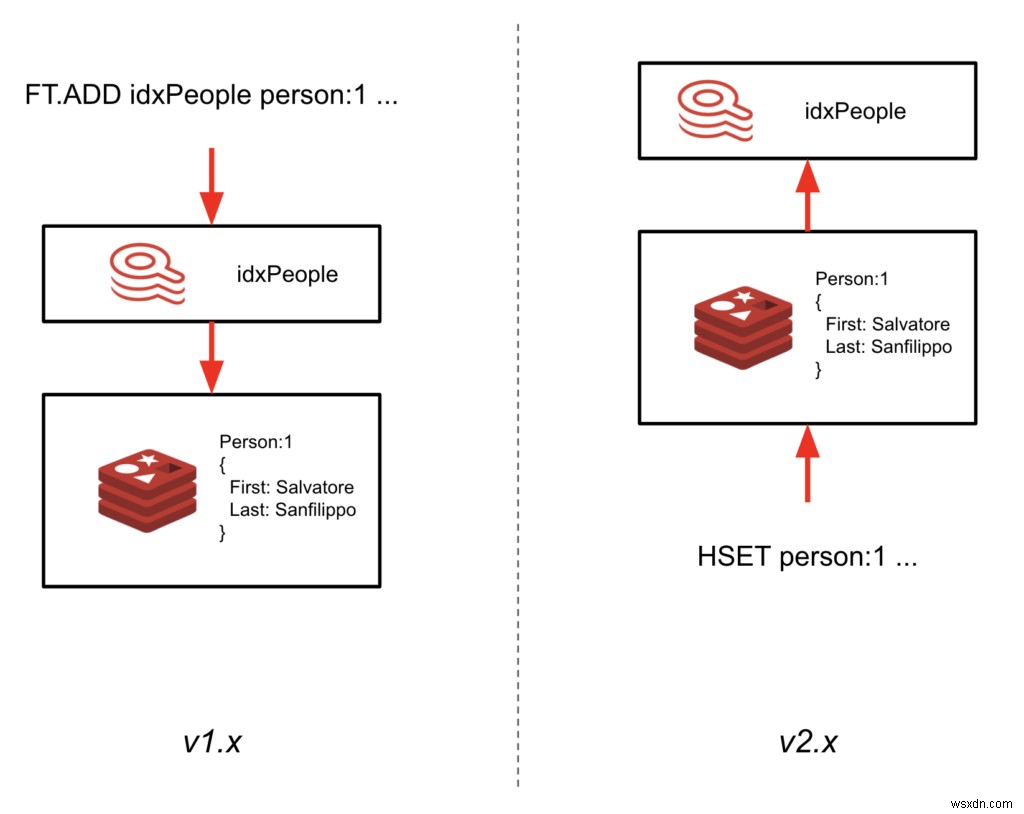
यह मील का पत्थर, जिसे 2.0-एम01 कहा जाता है, डेटा के साथ इंडेक्स को सिंक में रखने के तरीके के पुन:आर्किटेक्चर को चिह्नित करता है। इंडेक्स के माध्यम से डेटा लिखने के बजाय (FT.ADD . का उपयोग करके) कमांड), RediSearch अब हैश में लिखे गए डेटा का अनुसरण करेगा और इसे स्वचालित रूप से अनुक्रमित करेगा।
यहां बड़ा फायदा यह है कि अब आप अपने मौजूदा रेडिस इंस्टेंस में RediSearch जोड़ सकते हैं और अपने एप्लिकेशन कोड को अपडेट किए बिना एक सेकेंडरी इंडेक्स बना सकते हैं। यह आपको केवल RediSearch मॉड्यूल को लोड करके और स्कीमा को परिभाषित करके, अपने मौजूदा डेटा पर तुरंत RediSearch का उपयोग शुरू करने देता है। इस गिरावट में RediSearch 2.0 की सामान्य उपलब्धता अपेक्षित है।
(नोट: यह नई सुविधा एपीआई (नीचे सूचीबद्ध) में कुछ बदलाव पेश करती है। हम जितना हो सके पिछड़ी संगतता बनाए रखने की कोशिश करते हैं, लेकिन इस मामले में यह संभव नहीं था। हम ग्राहकों की प्रतिक्रिया एकत्र करते हुए आगे जाकर समायोजन और सुधार करने की योजना बना रहे हैं।)
एपीआई परिवर्तन
जैसा कि ऊपर बताया गया है, इस RediSearch 2.0 माइलस्टोन में API में कई बदलाव शामिल हैं:
- सूचकांक अब प्रमुख स्थान पर नहीं रहता है। यदि आपने डेटाबेस में इंडेक्स को सूचीबद्ध करने के लिए इंडेक्स कुंजी (idx:
) का उपयोग किया है, उदाहरण के लिए, यह अब काम नहीं करेगा। हालांकि, हमने एक कमांड FT._LIST शुरू किया है डेटाबेस में सभी सूचकांक वापस करने के लिए। - अनुक्रमणिका एक उपसर्ग/फ़िल्टर के साथ बनाई जानी चाहिए। ये निर्दिष्ट करते हैं कि RediSearch द्वारा कौन से दस्तावेज़ों को स्वचालित रूप से अनुक्रमित किया जाएगा। आप एक साधारण उपसर्ग और/या एक जटिल फ़िल्टर व्यंजक निर्दिष्ट कर सकते हैं।
- उन्नयन संभव नहीं है। यदि आपके पास RediSearch के पुराने संस्करण के साथ RDB बनाया गया है, तो RediSearch 2.0 इसे पढ़ने में सक्षम नहीं होगा। वर्तमान में, आपको संपूर्ण डेटा सेट को फिर से अनुक्रमित करना होगा। हालांकि, हम GA रिलीज़ के लिए एक अपग्रेड प्रक्रिया पर काम कर रहे हैं।
- यह केवल Redis 6 और इसके बाद के संस्करण के साथ काम करता है।
- FT कमांड को उनके रेडिस-समतुल्य कमांड से मैप किया गया था। यह मौजूदा अनुप्रयोगों को अभी भी RediSearch 2.0 के साथ काम करने की अनुमति देता है। मैपिंग इस प्रकार हैं:
- FT.ADD => <चिह्न>एचएसईटी
- FT.DEL => <चिह्न>DEL (डीडी डिफ़ॉल्ट रूप से)
- FT.GET => <चिह्न>HGETALL
- FT.MGET => <चिह्न>HGETALL
- उलटा अनुक्रमणिका स्वयं अब RDB में सहेजी नहीं जाती है . इसका मतलब यह नहीं है कि दृढ़ता समर्थित नहीं है। RediSearch सूचकांक परिभाषा को RDB में सहेजता है और Redis शुरू होने के बाद पृष्ठभूमि में डेटा को अनुक्रमित करता है। आप FT.INFO का उपयोग करके इंडेक्सिंग स्थिति की जांच करके पता लगा सकते हैं कि रीइंडेक्सिंग कब समाप्त हुई है आदेश।
नया एपीआई
एपीआई के लिए सबसे बड़ा अपडेट यह है कि इंडेक्स कैसे बनाए जाते हैं। RediSearch 2.0 में कमांड FT.CREATE सूचकांक बनाने के लिए प्रयोग किया जाता है। एपीआई के अतिरिक्त यहां पीले रंग में हाइलाइट किया गया है:
FT.CREATE {index}
ON {structure}
[PREFIX {count} {prefix} [{prefix} ..]
[FILTER {filter}]
[LANGUAGE_FIELD {lang_field}]
[LANGUAGE {lang}]
[SCORE_FIELD {score_field}]
[SCORE {score}]
[PAYLOAD_FIELD {payload_field}]
[TEMPORARY {seconds}]
[MAXTEXTFIELDS]
[NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS]
[STOPWORDS {num} {stopword} ...]
SCHEMA {field} [TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] ] [SORTABLE][NOINDEX] ... आइए कुछ विवरणों पर गौर करें:
- ऑन {स्ट्रक्चर} वर्तमान में केवल HASH का समर्थन करता है
- PREFIX {गिनती} {उपसर्ग} सूचकांक को बताता है कि उसे किन कुंजियों को अनुक्रमित करना चाहिए। आप अनुक्रमणिका में कई उपसर्ग जोड़ सकते हैं। चूंकि तर्क वैकल्पिक है, डिफ़ॉल्ट * . है (सभी कुंजियाँ)
- फ़िल्टर {फ़िल्टर} पूर्ण RediSearch एकत्रीकरण अभिव्यक्ति भाषा के साथ एक फ़िल्टर अभिव्यक्ति है। अभी-अभी जोड़ी/बदली गई कुंजी तक पहुंचने के लिए @__key का उपयोग करना संभव है
- भाषा और <चिह्न>स्कोर आपको डिफ़ॉल्ट भाषा को ओवरराइड करने और अनुक्रमित किए गए सभी दस्तावेज़ों के लिए स्कोर करने देता है
- LANGUAGE_FIELD , SCORE_FIELD , और PAYLOAD_FIELD आपको दस्तावेज़-विशिष्ट भाषा और स्कोरिंग, और दस्तावेज़ के भीतर एक फ़ील्ड के रूप में पेलोड का उपयोग करने की अनुमति देता है।
अन्य सीमाएं और परिवर्तन
RediSearch 2.0-M01 मील का पत्थर कुछ अन्य अपडेट भी लाता है:
- NOSAVE अब समर्थित नहीं है।
- हैश अपडेट करने का अर्थ है कि पूरे दस्तावेज़ को अनुक्रमित किया जाएगा (कीस्पेस नोटिफिकेशन यह नहीं बताता कि कौन से फ़ील्ड बदले गए थे)। इसलिए आंशिक अपडेट धीमे होंगे। ध्यान दें कि हम अभी भी इन स्थितियों में प्रदर्शन को बेहतर बनाने के विकल्पों की जांच कर रहे हैं।
- फ़ील्ड नाम अब केस संवेदी हो गए हैं, इसलिए किसी फ़ील्ड को "FOO" घोषित करने और उसे "foo" के रूप में अनुक्रमित करने से काम नहीं चलेगा।
- द FT.ADD कमांड को hset . पर मैप किया जाएगा जैसा कि यहां दिखाया गया है:
FT.ADD idx doc1 1.0 LANGUAGE eng PAYLOAD payload FIELDS f1 v1 f2 v2
पर मैप किया गया है
HSET doc1 __score 1.0 __language eng __payload payload f1 v1 f2 v2
इसका मतलब यह है कि आपके इंडेक्स पर स्कोर, भाषा और पेलोड फ़ील्ड को __score, __language, __payload कहा जाना चाहिए, ताकि मैपिंग उम्मीद के मुताबिक काम करे।
- FT.ADDHASH अब समर्थित नहीं है। <चिह्न>एचएसईटी का प्रयोग करें ।
- FT.OPTIMIZE अब समर्थित नहीं है, RediSearch कचरा संग्रह फ़ंक्शन अनुक्रमणिका को अनुकूलित करने के लिए ज़िम्मेदार है।
निष्कर्ष
हम इन परिवर्तनों के बारे में वास्तव में उत्साहित हैं क्योंकि अब आप अपने मौजूदा Redis डेटाबेस में RediSearch को लोड कर सकते हैं और इन दस्तावेज़ों में हेरफेर करते समय अपने एप्लिकेशन लॉजिक को अपडेट किए बिना, हैश में रहने वाले अपने मौजूदा डेटा को अनुक्रमित कर सकते हैं। आप GitHub से स्रोत कोड लेकर या 1:99:1 का उपयोग करके इस माइलस्टोन रिलीज़ को आज़मा सकते हैं रेडिससर्च डॉकर छवि। यह संस्करण अभी तक उत्पादन के लिए तैयार नहीं है, लेकिन हम आपकी प्रतिक्रिया प्राप्त करने के लिए इसे अभी आपके साथ साझा करना चाहते हैं। कृपया हमारे GitHub रिपॉजिटरी या रेडिस कम्युनिटी फोरम में कोई भी टिप्पणी या समस्या साझा करें।