RediSearch, Redis के लिए पूर्ण-पाठ खोज क्षमताओं के साथ एक रीयल-टाइम सेकेंडरी इंडेक्स, सबसे परिपक्व और सुविधा संपन्न Redis मॉड्यूल में से एक है। यह हर दिन और भी अधिक लोकप्रिय होता जा रहा है—पिछले कुछ महीनों में RediSearch Docker pulls में 500% की वृद्धि हुई है! उस बढ़ती लोकप्रियता ने ग्राहकों को रीयल-टाइम इन्वेंट्री प्रबंधन से लेकर अल्पकालिक खोज तक कई तरह के दिलचस्प उपयोग के मामलों के साथ आने के लिए प्रेरित किया है।
उस गति को बढ़ाने के लिए, अब हम RediSearch 2.0 का सार्वजनिक पूर्वावलोकन पेश कर रहे हैं, जिसेडेवलपर अनुभव को बेहतर बनाने के लिए डिज़ाइन किया गया है और Redissearch का सबसे मापनीय संस्करण be बनें . RediSearch 2.0 Redis की सक्रिय-सक्रिय भू-वितरण तकनीक का समर्थन करता है, बिना डाउनटाइम के स्केलेबल है, और इसमें Redis ऑन फ्लैश सपोर्ट शामिल है (वर्तमान में निजी पूर्वावलोकन में)। प्रदर्शन को नकारात्मक रूप से प्रभावित किए बिना उन लक्ष्यों को पूरा करने के लिए, हमने RediSearch 2.0 के लिए एक बिल्कुल नया आर्किटेक्चर बनाया—और इसने काम किया:RediSearch 2.0 2.4x तेज है रेडिसर्च 1.6 की तुलना में।
RediSearch 2.0 के नए आर्किटेक्चर के अंदर
आपके Redis डेटाबेस में एक समृद्ध क्वेरी-एंड-एग्रीगेशन इंजन होने से कई तरह के नए उपयोग के मामले सक्षम होते हैं जो कैशिंग से परे होते हैं। RediSearch आपको उन परिस्थितियों में अपने प्राथमिक डेटाबेस के रूप में Redis का उपयोग करने देता है जहाँ आपको जटिल प्रश्नों का उपयोग करके डेटा तक पहुँचने की आवश्यकता होती है। इससे भी बेहतर, यह रेडिस की विश्व स्तरीय गति, विश्वसनीयता और मापनीयता को बरकरार रखता है, और आपको डेटा को अपडेट और इंडेक्स करने के लिए कोड में जटिलता जोड़ने की आवश्यकता नहीं है।
RediSearch 2.0 के लिए हमने इंडेक्स को डेटा के साथ सिंक में रखने के तरीके को फिर से तैयार किया है। इंडेक्स (FT.ADD कमांड का उपयोग करके) के माध्यम से डेटा लिखने के बजाय, RediSearch अब हैश में लिखे गए डेटा का अनुसरण करता है और इसे सिंक्रोनाइज़ करता है। यह री-आर्किटेक्चर एपीआई में कई बदलावों के साथ आता है, जिसकी चर्चा हमने पिछली पोस्ट में की थी जब RediSearch 2.0 ने अपना पहला मील का पत्थर मारा था।
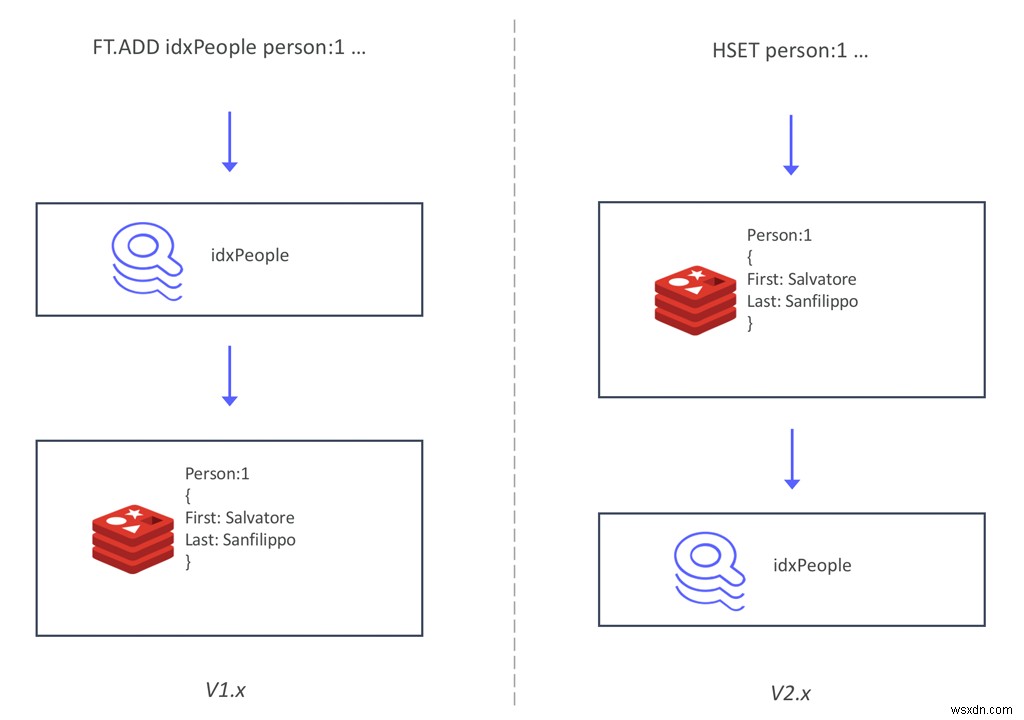
यह नई वास्तुकला दो मुख्य लाभ लाती है। सबसे पहले, अपने मौजूदा डेटा के शीर्ष पर द्वितीयक अनुक्रमणिका बनाना अब पहले से कहीं अधिक आसान है। आप बस RediSearch को अपने मौजूदा Redis डेटाबेस में जोड़ सकते हैं, एक इंडेक्स बना सकते हैं, और इसकी क्वेरी करना शुरू कर सकते हैं , अपने डेटा को माइग्रेट किए बिना या अनुक्रमणिका में डेटा जोड़ने के लिए नए आदेशों का उपयोग किए बिना। यह नए RediSearch उपयोगकर्ताओं के लिए सीखने की अवस्था को बहुत कम करता है और आपको अपने मौजूदा Redis डेटाबेस पर अनुक्रमणिका बनाने देता है—बिना उन्हें पुनरारंभ किए।
डेटा को इंडेक्स करने के लिए एक नया तरीका लागू करने के अलावा, हमने इंडेक्स को कीस्पेस से भी हटा लिया है। यह रेडिस एंटरप्राइज की सक्रिय-सक्रिय तकनीक को सक्षम बनाता है, जो संघर्ष-मुक्त प्रतिकृति डेटा प्रकारों (सीआरडीटी) पर आधारित है। दो उल्टे सूचकांकों को संघर्ष-मुक्त विलय करना मुश्किल है, लेकिन रेडिस के पास पहले से ही हैश का एक सिद्ध सीआरडीटी कार्यान्वयन है। तो इस नए आर्किटेक्चर का दूसरा बड़ा लाभ RediSearch 2.0 को और भी अधिक मापनीय बना रहा है . चूंकि RediSearch अब हैश का अनुसरण करता है और अनुक्रमणिका को कीस्पेस से बाहर ले जाया गया था, अब आप RediSearch को एक सक्रिय-सक्रिय भू-वितरित डेटाबेस में चला सकते हैं।
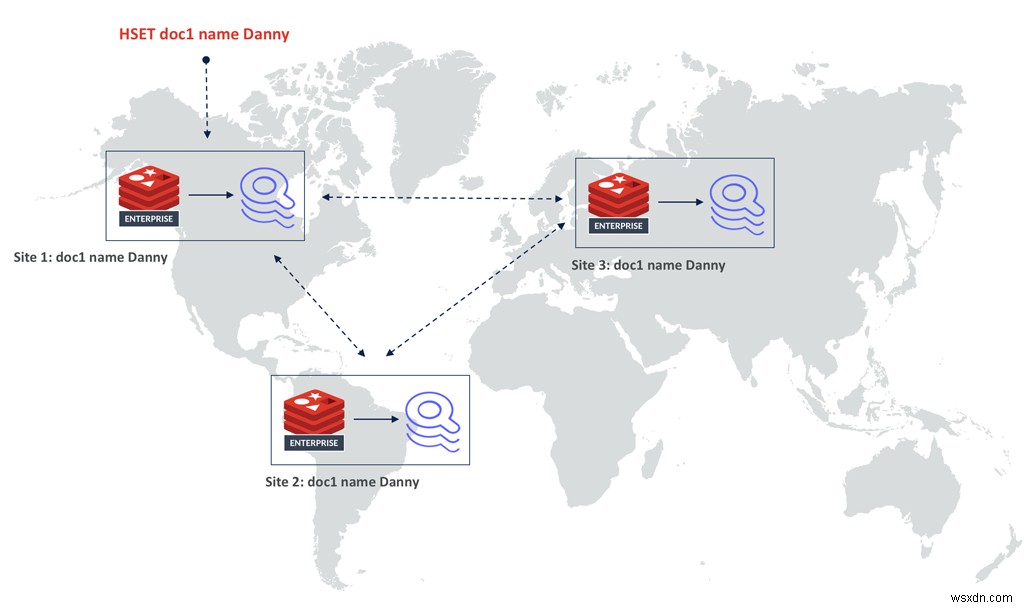
एक दस्तावेज़ को सभी डेटाबेस में प्रतिकृति सेट में दृढ़ता से अंतिम रूप से सुसंगत तरीके से दोहराया जाएगा। प्रत्येक प्रतिकृति में, RediSearch केवल हैश पर सभी अपडेट का पालन करेगा, जिसका अर्थ है कि सभी सूचकांक दृढ़ता से अंततः संगत हैं।
ओपन सोर्स रेडिस के लिए OSS क्लस्टर सपोर्ट
हम स्केलेबिलिटी क्षमताओं को केवल रेडिस एंटरप्राइज उपयोगकर्ताओं तक सीमित नहीं करना चाहते थे, इसलिए हमने ओपन सोर्स रेडिस क्लस्टर एपीआई के साथ एकल इंडेक्स को कई शार्क पर स्केल करने के लिए समर्थन जोड़ा। पहले, एक एकल RediSearch अनुक्रमणिका और उसके दस्तावेज़ों को एक ही शार्क पर रहना पड़ता था। इसका मतलब यह था कि ओएसएस रेडिस के लिए डेटासेट आकार और थ्रूपुट एक रेडिस प्रक्रिया को संभालने के लिए बाध्य था। रेडिस एंटरप्राइज ने क्लस्टर डेटाबेस में दस्तावेजों को वितरित करने और क्वेरी समय पर परिणामों को एकत्रित करने की क्षमता की पेशकश की। इस फैन-आउट और एकत्रीकरण को "समन्वयक" नामक एक घटक द्वारा नियंत्रित किया जाता है जो अब रेडिस स्रोत उपलब्ध लाइसेंस के तहत सार्वजनिक रूप से उपलब्ध है, इसलिए यह ओपन सोर्स रेडिस क्लस्टर के साथ-साथ रेडिस एंटरप्राइज के साथ काम करेगा। परिणाम अभी तक RediSearch का सबसे मापनीय संस्करण है।
मुझे नंबर दिखाओ!
RediSearch 2.0 के अंतर्ग्रहण प्रदर्शन का आकलन करने के लिए, हमने सार्वजनिक रूप से उपलब्ध NYC टैक्सी डेटासेट के साथ अपने पूर्ण-पाठ खोज बेंचमार्क (FTSB) सुइट का विस्तार किया। डेटा प्रकारों (पाठ, टैग, भौगोलिक और संख्यात्मक) के समृद्ध सेट और बड़ी संख्या में दस्तावेज़ों के कारण इस डेटासेट का उपयोग पूरे उद्योग में किया जाता है।
यह बेंचमार्क न्यूयॉर्क शहर में पीली कैब में सवारी के ट्रिप-रिकॉर्ड डेटा का उपयोग करते हुए, लेखन प्रदर्शन पर केंद्रित है। विशेष रूप से इस बेंचमार्क के लिए हमने जनवरी 2015 डेटासेट का उपयोग किया, जो प्रति दस्तावेज़ 500 बाइट्स के औसत आकार के साथ 12 मिलियन से अधिक दस्तावेज़ लोड करता है। पूर्ण बेंचमार्क विनिर्देश के लिए कृपया GitHub पर FTSB देखें।
सभी बेंचमार्क वेरिएशन Amazon वेब सर्विसेज इंस्टेंस पर चलाए गए थे, जो हमारे बेंचमार्क-टेस्टिंग इंफ्रास्ट्रक्चर के जरिए प्रोविजन किए गए थे। रेडिसर्च एंटरप्राइज संस्करण 1.6 और 2.0 के साथ 15 शार्क के साथ 3-नोड क्लस्टर पर परीक्षण निष्पादित किए गए थे। बेंचमार्किंग क्लाइंट और RediSearch सक्षम डेटाबेस वाले 3 नोड्स दोनों अलग-अलग c5.9xlarge इंस्टेंस पर चल रहे थे।
यह देखते हुए कि RediSearch 2.0, Redis में हैश में परिवर्तनों का पालन करने और उन्हें स्वचालित रूप से अनुक्रमित करने की क्षमता के साथ आता है, हमने FT.ADD और HSET कमांड के लिए वेरिएंट जोड़े हैं। अपग्रेड को आसान बनाने के लिए, हमने अब बहिष्कृत FT.ADD कमांड को RediSearch 2.0 में HSET कमांड में रीमैप किया है। नीचे दिए गए दो चार्ट सब-मिलीसेकंड लेटेंसी बनाए रखते हुए, RediSearch 1.6 और RediSearch 2.0 दोनों के लिए समग्र अंतर्ग्रहण दर और विलंबता प्रदर्शित करते हैं।
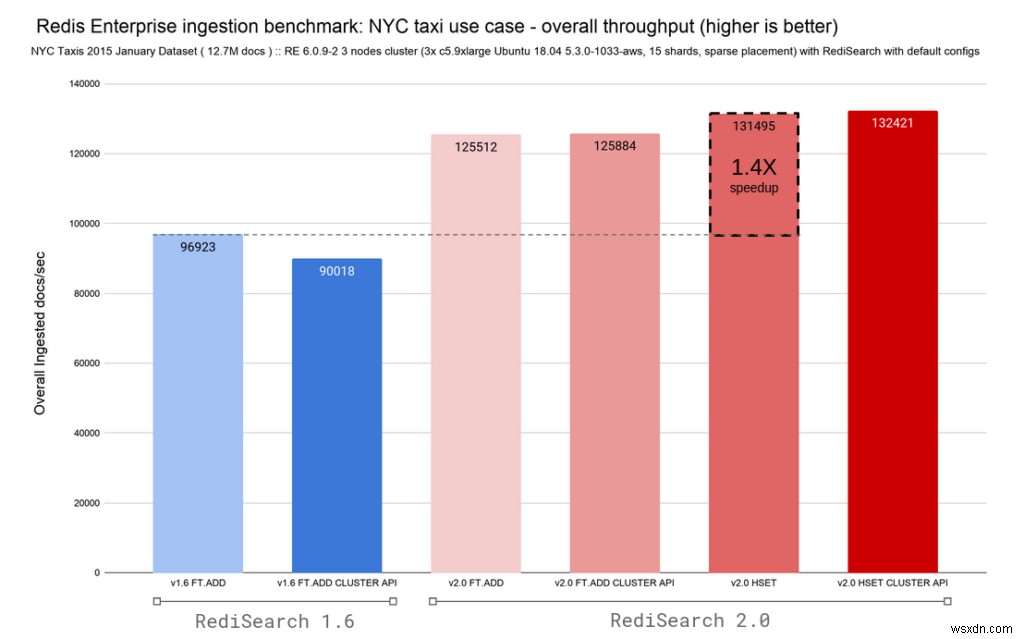
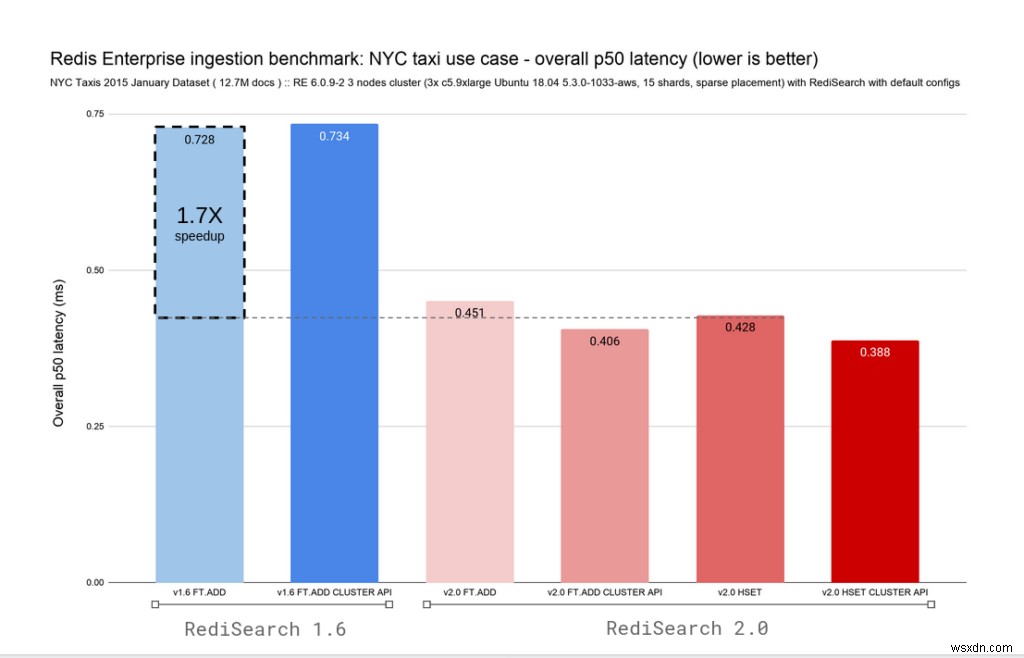
RediSearch हमेशा तेज रहा है, लेकिन इस वास्तु परिवर्तन के साथ हम 0.4ms की समग्र p50 अंतर्ग्रहण विलंबता पर 96K दस्तावेज़ प्रति सेकंड अनुक्रमणित करने से 132K दस्तावेज़/सेकंड पर चले गए हैं, जिससे लेखन स्केलिंग में अत्यधिक सुधार हुआ है।
न केवल आपको थ्रूपुट में वृद्धि से लाभ होगा, बल्कि प्रत्येक अंतर्ग्रहण भी तेज हो जाता है। आर्किटेक्चर में बदलावों के कारण समग्र अंतर्ग्रहण सुधार के अलावा, अब आप अपने खोज डेटाबेस के अंतर्ग्रहण को रैखिक रूप से मापने के लिए ओएसएस रेडिस क्लस्टर एपीआई क्षमताओं पर भी भरोसा कर सकते हैं।
थ्रूपुट और विलंबता सुधारों को मिलाकर, RediSearch 2.0 2.4X स्पीडअप तक प्रदान करता है RediSearch 1.6 की तुलना में।
RediSearch 2.0 के लिए आगे क्या है
संक्षेप में, RediSearch 2.0 उन सभी Redis उपयोगकर्ताओं के लिए सबसे तेज़ और सबसे स्केलेबल संस्करण है जिसे हमने कभी जारी किया है। इसके अलावा, RediSearch 2.0 का नया आर्किटेक्चर Redis के भीतर मौजूदा डेटा के लिए एक सहज तरीके से इंडेक्स बनाने के डेवलपर अनुभव को बेहतर बनाता है और आपके Redis डेटा को किसी अन्य RediSearch- सक्षम डेटाबेस में माइग्रेट करने की आवश्यकता को हटा देता है। यह नया आर्किटेक्चर RediSearch को अन्य डेटा संरचनाओं, जैसे कि स्ट्रीम या स्ट्रिंग्स का अनुसरण और ऑटो-इंडेक्स करने की अनुमति देता है। आगामी रिलीज़ में, यह आपको अतिरिक्त डेटा संरचनाओं जैसे कि RedisJSON में नेस्टेड डेटा संरचना के साथ काम करने देगा।
हम डेवलपर अनुभव को और बेहतर बनाने के लिए और अधिक सुविधाएं जोड़ने की योजना बना रहे हैं। इसके बाद, एक नया आदेश देखें जो आपको अपनी खोज क्वेरी को बेहतर ढंग से समझने की अनुमति देता है कि क्वेरी निष्पादन के दौरान प्रदर्शन की बाधाएं कहां होती हैं।
आरंभ करने के लिए तैयार हैं? पर Tug Grall का ब्लॉग देखें... RediSearch 2.0 के साथ शुरुआत करना! फिर GitHub पर इस ट्यूटोरियल के चरणों का पालन करें या Redis Enterprise Cloud Essentials में एक निःशुल्क डेटाबेस बनाएँ। (ध्यान दें कि RediSearch 2.0 का सार्वजनिक पूर्वावलोकन दो Redis Enterprise Cloud Essentials क्षेत्रों में उपलब्ध है:मुंबई और ओरेगन।)