वेब स्क्रैपर बनाने की इस श्रृंखला में आपका फिर से स्वागत है। इस ट्यूटोरियल में, मैं अपनी पॉडकास्ट साइट से डेटा स्क्रैप करने के एक उदाहरण के माध्यम से जाऊँगा। मैं विस्तार से कवर करूंगा कि मैंने डेटा कैसे निकाला, कैसे सहायक और उपयोगिता विधियां अपना काम पूरा करती हैं, और सभी पहेली टुकड़े एक साथ कैसे आते हैं।
विषय
- मेरा पॉडकास्ट स्क्रैप करना
- प्राइ
- खुरचनी
- सहायक तरीके
- पोस्ट लिखना
मेरा पॉडकास्ट स्क्रैप करना
आइए अब तक हमने जो सीखा है उसे व्यवहार में लाएं। विभिन्न कारणों से, | . के बीच मेरे पॉडकास्ट के लिए एक नया स्वरूप स्क्रीन लंबे समय से लंबित थीं. सुबह उठने पर कुछ मुद्दे थे जो मुझे चिल्लाते थे। इसलिए मैंने एक पूरी नई स्थिर साइट स्थापित करने का निर्णय लिया, जिसे मिडिलमैन के साथ बनाया गया और गिटहब पेज के साथ होस्ट किया गया।
जब मैंने एक बिचौलिए ब्लॉग को अपनी ज़रूरतों के अनुसार बदल दिया, तब मैंने नए डिज़ाइन पर काफी समय लगाया। मेरे डेटाबेस समर्थित सिनात्रा ऐप से सामग्री को आयात करने के लिए बस इतना करना बाकी था, इसलिए मुझे मौजूदा सामग्री को स्क्रैप करने और इसे अपनी नई स्थिर साइट में स्थानांतरित करने की आवश्यकता थी।
स्कमक फैशन में हाथ से ऐसा करना मेज पर नहीं था - एक सवाल भी नहीं - क्योंकि मैं अपने दोस्तों नोकोगिरी और मैकेनाइज पर भरोसा कर सकता था कि वे मेरे लिए काम करें। आपके आगे जो है वह एक छोटा सा स्क्रैप काम है जो बहुत जटिल नहीं है लेकिन कुछ दिलचस्प मोड़ प्रदान करता है जो वेब स्क्रैपिंग न्यूबीज के लिए शैक्षिक होना चाहिए।
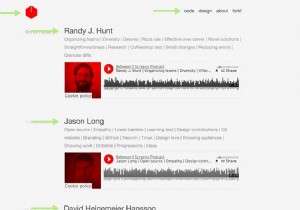
नीचे मेरे पॉडकास्ट के दो स्क्रीनशॉट हैं।
स्क्रीनशॉट पुराना पॉडकास्ट
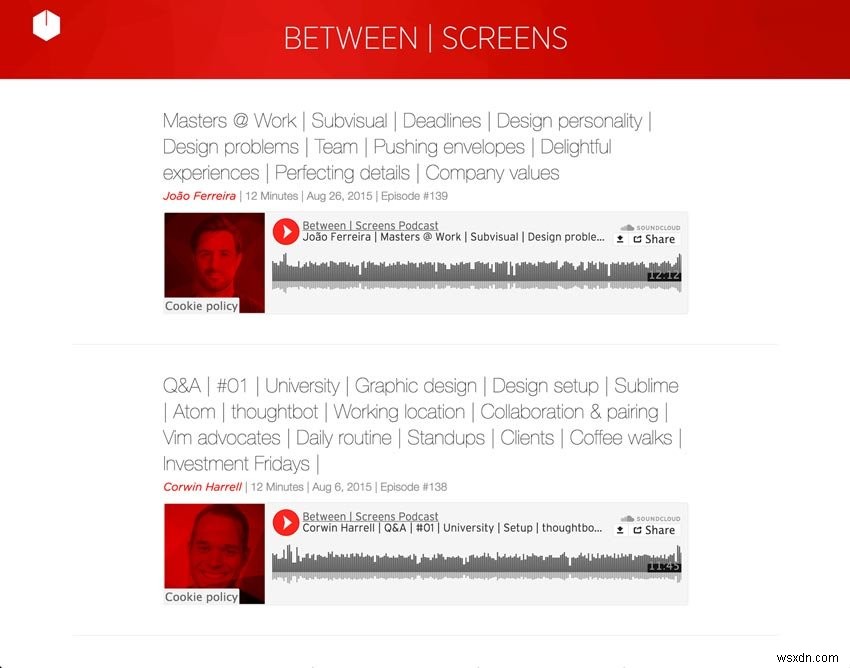
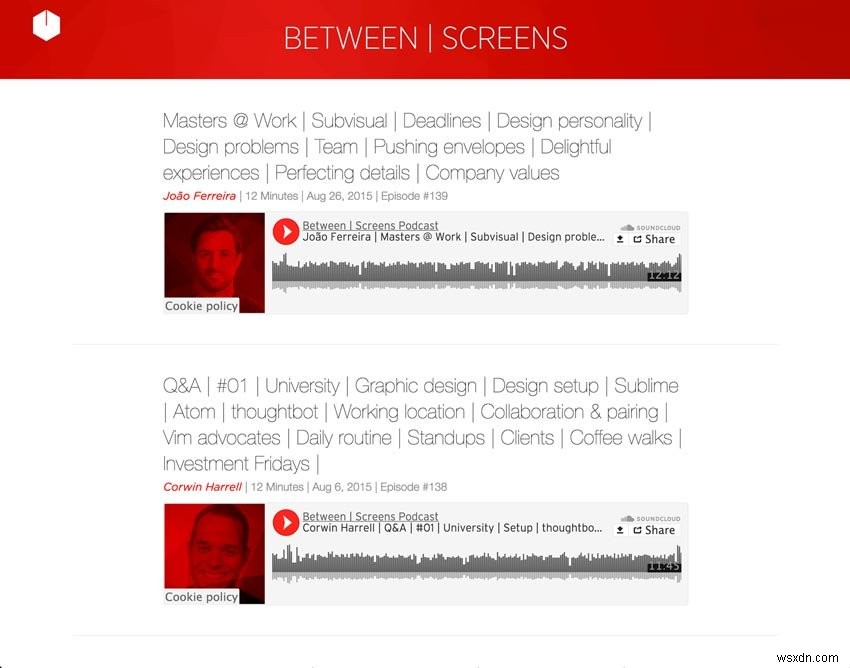
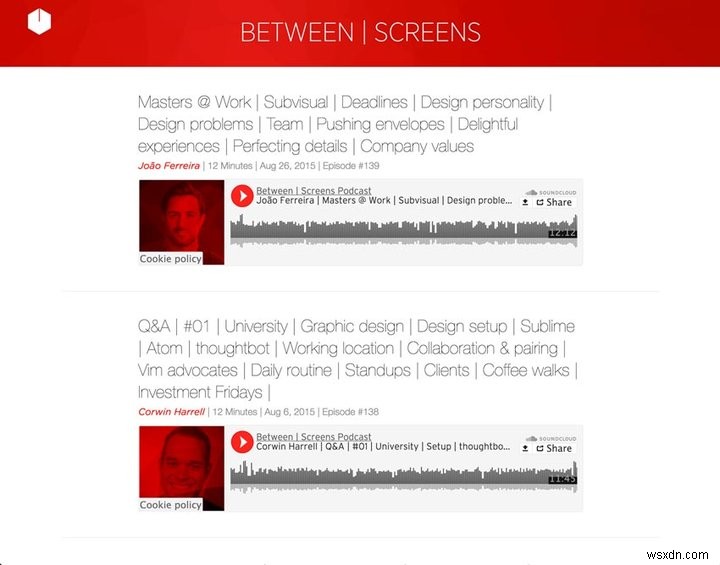
नया पॉडकास्ट का स्क्रीनशॉट
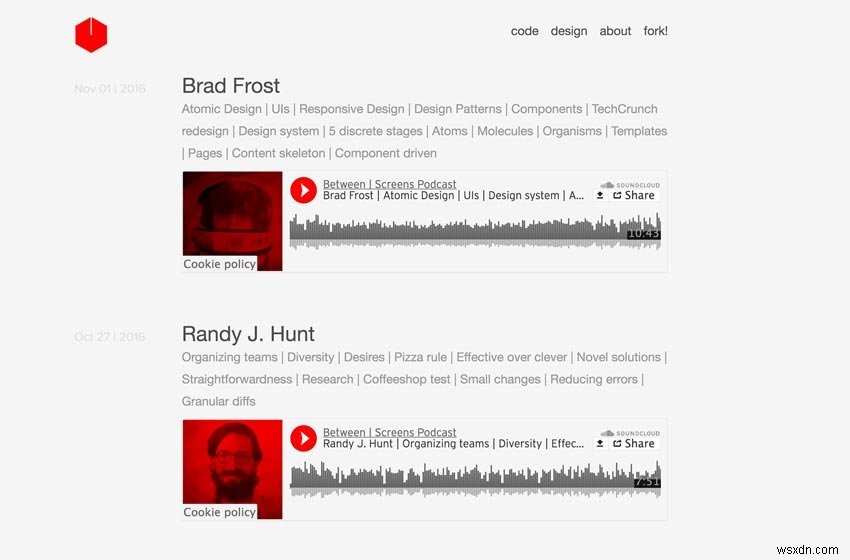
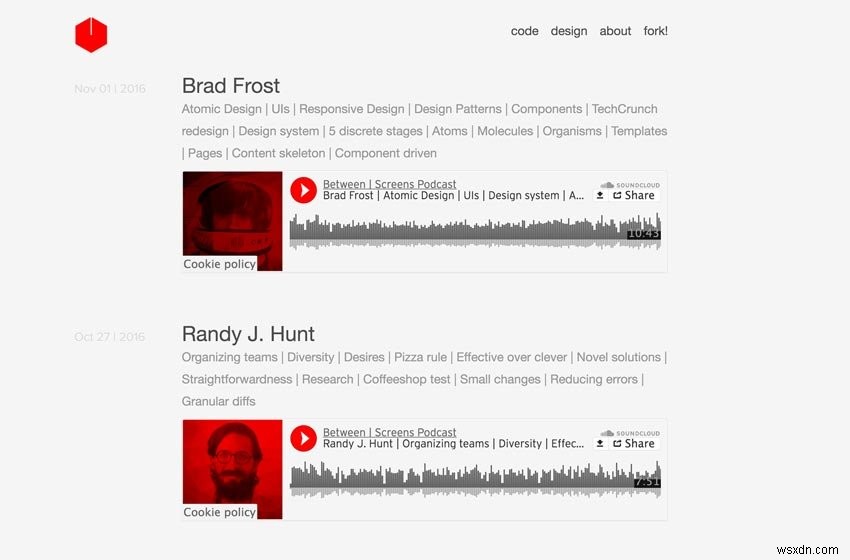
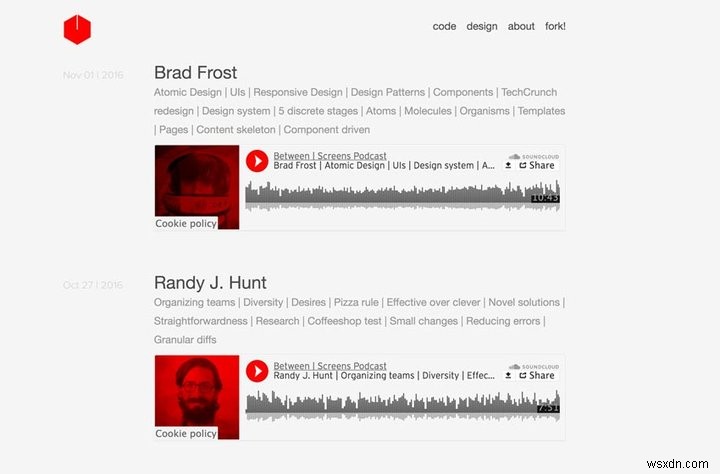
हम जो हासिल करना चाहते हैं, उसे तोड़ दें। हम 139 एपिसोड से निम्नलिखित डेटा निकालना चाहते हैं जो 21 पेजिनेटेड इंडेक्स साइटों पर फैले हुए हैं:
- शीर्षक
- साक्षात्कारकर्ता
- विषय सूची के साथ उपशीर्षक
- हर एपिसोड के लिए साउंडक्लाउड ट्रैक नंबर
- तारीख
- एपिसोड नंबर
- शो नोट्स से टेक्स्ट
- शो नोट्स के लिंक
हम पेजिनेशन के माध्यम से पुनरावृति करते हैं और मैकेनाइज को एक एपिसोड के लिए हर लिंक पर क्लिक करने देते हैं। निम्नलिखित विवरण पृष्ठ पर, हमें ऊपर से वह सभी जानकारी मिलेगी जिसकी हमें आवश्यकता है। उस स्क्रैप किए गए डेटा का उपयोग करके, हम प्रत्येक एपिसोड के लिए मार्कडाउन फ़ाइलों के फ्रंट मैटर और "बॉडी" को पॉप्युलेट करना चाहते हैं।
नीचे आप एक पूर्वावलोकन देख सकते हैं कि हम अपने द्वारा निकाली गई सामग्री के साथ नई मार्कडाउन फ़ाइलों की रचना कैसे करेंगे। मुझे लगता है कि यह आपको हमारे आगे के दायरे के बारे में एक अच्छा विचार देगा। यह हमारी छोटी लिपि में अंतिम चरण का प्रतिनिधित्व करता है। चिंता न करें, हम इसके बारे में और विस्तार से जानेंगे।
डिफ कंपोज़_मार्कडाउन
def compose_markdown(options={})
<<-HEREDOC
---
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
---
#{options[:text]}
HEREDOC
end
मैं कुछ तरकीबें भी जोड़ना चाहता था जो पुरानी साइट नहीं चला सकती थी। एक अनुकूलित, व्यापक टैगिंग प्रणाली का होना मेरे लिए महत्वपूर्ण था। मैं चाहता था कि श्रोताओं के पास एक गहन खोज उपकरण हो। इसलिए, मुझे प्रत्येक साक्षात्कारकर्ता के लिए टैग की आवश्यकता थी और उपशीर्षक को टैग में भी विभाजित किया। चूंकि मैंने अकेले पहले सीज़न में 139 एपिसोड का निर्माण किया था, इसलिए मुझे साइट को ऐसे समय के लिए तैयार करना पड़ा, जब सामग्री की मात्रा को सुलझाना कठिन हो जाता है। बुद्धिमानी से रखी गई सिफारिशों के साथ एक गहरी टैगिंग प्रणाली जाने का रास्ता था। इसने मुझे साइट को हल्का और तेज़ रखने की अनुमति दी।
आइए मेरी साइट की सामग्री को स्क्रैप करने के लिए पूरा कोड देखें। चारों ओर देखें और जो हो रहा है उसकी बड़ी तस्वीर जानने का प्रयास करें। चूंकि मुझे उम्मीद है कि आप चीजों के शुरुआती पक्ष में होंगे, इसलिए मैं बहुत अधिक सारगर्भित होने से दूर रहा और स्पष्टता के पक्ष में गलती की। मैंने कुछ रिफैक्टरिंग किए जिन्हें कोड स्पष्टता में सहायता के लिए लक्षित किया गया था, लेकिन जब आप इस लेख के साथ समाप्त कर लेंगे तो मैंने आपके लिए खेलने के लिए हड्डी पर थोड़ा सा मांस भी छोड़ दिया। आखिरकार, गुणवत्तापूर्ण शिक्षा तब होती है जब आप पढ़ने से परे जाते हैं और अपने दम पर कुछ कोड के साथ खिलवाड़ करते हैं।
साथ ही, मैं आपको अत्यधिक प्रोत्साहित करता हूं कि आप इस बारे में सोचना शुरू करें कि आप अपने सामने कोड को कैसे सुधार सकते हैं। इस लेख के अंत में यह आपका अंतिम कार्य होगा। मेरी ओर से एक छोटा सा संकेत:बड़े तरीकों को छोटे में तोड़ना हमेशा एक अच्छा प्रारंभिक बिंदु होता है। एक बार जब आप समझ जाते हैं कि कोड कैसे काम करता है, तो आपको उस रिफैक्टरिंग पर एक मजेदार समय बिताना चाहिए।
मैंने पहले से ही छोटे, केंद्रित सहायकों में विधियों का एक समूह निकालकर शुरू कर दिया है। कोड गंध और उनके रिफैक्टरिंग के बारे में मेरे पिछले लेखों से आपने जो सीखा है उसे आप आसानी से लागू करने में सक्षम होना चाहिए। यदि यह अभी भी आपके सिर पर चढ़ जाता है, तो चिंता न करें- हम सब वहाँ रहे हैं। बस इसे जारी रखें, और कुछ बिंदु पर चीजें तेजी से क्लिक करना शुरू कर देंगी।
पूर्ण कोड
require 'Mechanize'
require 'Pry'
require 'date'
# Helper Methods
# (Extraction Methods)
def extract_interviewee(detail_page)
interviewee_selector = '.episode_sub_title span'
detail_page.search(interviewee_selector).text.strip
end
def extract_title(detail_page)
title_selector = ".episode_title"
detail_page.search(title_selector).text.gsub(/[?#]/, '')
end
def extract_soundcloud_id(detail_page)
sc = detail_page.iframes_with(href: /soundcloud.com/).to_s
sc.scan(/\d{3,}/).first
end
def extract_shownotes_text(detail_page)
shownote_selector = "#shownote_container > p"
detail_page.search(shownote_selector)
end
def extract_subtitle(detail_page)
subheader_selector = ".episode_sub_title"
detail_page.search(subheader_selector).text
end
def extract_episode_number(episode_subtitle)
number = /[#]\d*/.match(episode_subtitle)
clean_episode_number(number)
end
# (Utility Methods)
def clean_date(episode_subtitle)
string_date = /[^|]*([,])(.....)/.match(episode_subtitle).to_s
Date.parse(string_date)
end
def build_tags(title, interviewee)
extracted_tags = strip_pipes(title)
"#{interviewee}"+ ", #{extracted_tags}"
end
def strip_pipes(text)
tags = text.tr('|', ',')
tags = tags.gsub(/[@?#&]/, '')
tags.gsub(/[w\/]{2}/, 'with')
end
def clean_episode_number(number)
number.to_s.tr('#', '')
end
def dasherize(text)
text.lstrip.rstrip.tr(' ', '-')
end
def extract_data(detail_page)
interviewee = extract_interviewee(detail_page)
title = extract_title(detail_page)
sc_id = extract_soundcloud_id(detail_page)
text = extract_shownotes_text(detail_page)
episode_subtitle = extract_subtitle(detail_page)
episode_number = extract_episode_number(episode_subtitle)
date = clean_date(episode_subtitle)
tags = build_tags(title, interviewee)
options = {
interviewee: interviewee,
title: title,
sc_id: sc_id,
text: text,
tags: tags,
date: date,
episode_number: episode_number
}
end
def compose_markdown(options={})
<<-HEREDOC
---
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
---
#{options[:text]}
HEREDOC
end
def write_page(link)
detail_page = link.click
extracted_data = extract_data(detail_page)
markdown_text = compose_markdown(extracted_data)
date = extracted_data[:date]
interviewee = extracted_data[:interviewee]
episode_number = extracted_data[:episode_number]
File.open("#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md", 'w') { |file| file.write(markdown_text) }
end
def scrape
link_range = 1
agent ||= Mechanize.new
until link_range == 21
page = agent.get("https://between-screens.herokuapp.com/?page=#{link_range}")
link_range += 1
page.links[2..8].map do |link|
write_page(link)
end
end
end
scrape
हमें require "Nokogiri" ? मशीनीकरण हमें हमारी सभी स्क्रैपिंग जरूरतें प्रदान करता है। जैसा कि हमने पिछले लेख में चर्चा की थी, मैकेनाइज नोकोगिरी के शीर्ष पर बनाता है और हमें सामग्री को भी निकालने की अनुमति देता है। हालाँकि, पहले लेख में उस रत्न को शामिल करना महत्वपूर्ण था क्योंकि हमें इसके ऊपर निर्माण करने की आवश्यकता थी।
प्राइ
पहली चीजें पहले। इससे पहले कि हम यहां अपने कोड में कूदें, मैंने सोचा कि आपको यह दिखाना आवश्यक है कि आप कैसे कुशलतापूर्वक जांच कर सकते हैं कि आपका कोड हर कदम पर अपेक्षित रूप से काम करता है या नहीं। जैसा कि आपने निश्चित रूप से देखा है, मैंने मिश्रण में एक और उपकरण जोड़ा है। अन्य बातों के अलावा, Pry डिबगिंग के लिए वास्तव में आसान है।
यदि आप Pry.start(binding) डालते हैं अपने कोड में कहीं भी, आप ठीक उसी बिंदु पर अपने आवेदन का निरीक्षण कर सकते हैं। आप एप्लिकेशन में विशिष्ट बिंदुओं पर वस्तुओं का पता लगा सकते हैं। यह वास्तव में आपके अपने पैरों पर ट्रिपिंग किए बिना आपके आवेदन को कदम से कदम उठाने में मददगार है। उदाहरण के लिए, इसे हमारे write_page . के ठीक बाद में रखें कार्य करें और जांचें कि क्या link वह है जिसकी हम अपेक्षा करते हैं।
प्राइ
...
def scrape
link_range = 1
agent ||= Mechanize.new
until link_range == 21
page = agent.get("https://between-screens.herokuapp.com/?page=#{link_range}")
link_range += 1
page.links[2..8].map do |link|
write_page(link)
Pry.start(binding)
end
end
end
...
यदि आप स्क्रिप्ट चलाते हैं, तो हमें कुछ ऐसा मिलेगा।
आउटपुट
»$ ruby noko_scraper.rb
321: def scrape
322: link_range = 1
323: agent ||= Mechanize.new
324:
326: until link_range == 21
327: page = agent.get("https://between-screens.herokuapp.com/?page=#{link_range}")
328: link_range += 1
329:
330: page.links[2..8].map do |link|
331: write_page(link)
=> 332: Pry.start(binding)
333: end
334: end
335: end
[1] pry(main)>
जब हम link . के लिए पूछते हैं ऑब्जेक्ट, हम अन्य कार्यान्वयन विवरणों पर आगे बढ़ने से पहले जांच सकते हैं कि क्या हम सही रास्ते पर हैं।
टर्मिनल
[2] pry(main)> link => #<Mechanize::Page::Link "Masters @ Work | Subvisual | Deadlines | Design personality | Design problems | Team | Pushing envelopes | Delightful experiences | Perfecting details | Company values" "/episodes/139">
ऐसा लगता है कि हमें क्या चाहिए। बढ़िया, हम आगे बढ़ सकते हैं। यह सुनिश्चित करने के लिए कि आप खो न जाएं और आप वास्तव में समझें कि यह कैसे काम करता है, पूरे एप्लिकेशन के माध्यम से इस चरण को चरणबद्ध तरीके से करना एक महत्वपूर्ण अभ्यास है। मैं यहां प्राइ को और विस्तार से कवर नहीं करूंगा क्योंकि ऐसा करने के लिए मुझे कम से कम एक और पूरा लेख लेना होगा। मैं केवल मानक IRB शेल के विकल्प के रूप में इसका उपयोग करने की अनुशंसा कर सकता हूं। हमारे मुख्य कार्य पर वापस।
स्क्रैपर
अब जब आपको पहेली के टुकड़ों से खुद को परिचित करने का मौका मिल गया है, तो मेरा सुझाव है कि हम एक-एक करके उन पर जाएं और यहां और वहां कुछ दिलचस्प बिंदुओं को स्पष्ट करें। आइए केंद्रीय टुकड़ों से शुरू करें।
podcast_scraper.rb
...
def write_page(link)
detail_page = link.click
extracted_data = extract_data(detail_page)
markdown_text = compose_markdown(extracted_data)
date = extracted_data[:date]
interviewee = extracted_data[:interviewee]
episode_number = extracted_data[:episode_number]
file_name = "#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md"
File.open(file_name, 'w') { |file| file.write(markdown_text) }
end
def scrape
link_range = 1
agent ||= Mechanize.new
until link_range == 21
page = agent.get("https://between-screens.herokuapp.com/?page=#{link_range}")
link_range += 1
page.links[2..8].map do |link|
write_page(link)
end
end
end
...
scrape में क्या होता है तरीका? सबसे पहले, मैं पुराने पॉडकास्ट में हर इंडेक्स पेज पर लूप करता हूं। मैं हेरोकू ऐप से पुराने यूआरएल का उपयोग कर रहा हूं क्योंकि नई साइट पहले से ही ऑनलाइन है। मेरे पास एपिसोड के 20 पृष्ठ थे जिन्हें मुझे लूप करने की आवश्यकता थी।
मैंने link_range . के ज़रिए लूप को सीमांकित किया चर, जिसे मैंने प्रत्येक लूप के साथ अद्यतन किया। पृष्ठ पर अंक लगाना उतना ही सरल था जितना कि प्रत्येक पृष्ठ के URL में इस चर का उपयोग करना। सरल और प्रभावी।
डीईएफ़ परिमार्जन
page = agent.get("https://between-screens.herokuapp.com/?page=#{link_range}")
फिर, जब भी मुझे स्क्रैप करने के लिए और आठ एपिसोड के साथ एक नया पेज मिलता है, तो मैं page.links का उपयोग करता हूं। उन लिंक्स की पहचान करने के लिए जिन्हें हम क्लिक करना चाहते हैं और प्रत्येक एपिसोड के विवरण पृष्ठ पर जाएं। मैंने कई लिंक्स के साथ जाने का फैसला किया (links[2..8] ) क्योंकि यह प्रत्येक पृष्ठ पर सुसंगत था। यह उन लिंक्स को लक्षित करने का सबसे आसान तरीका भी था जिनकी मुझे प्रत्येक अनुक्रमणिका पृष्ठ से आवश्यकता है। यहां सीएसएस चयनकर्ताओं के साथ खिलवाड़ करने की जरूरत नहीं है।
फिर हम उस लिंक को विवरण पृष्ठ के लिए write_page . पर फीड कर देते हैं तरीका। ज्यादातर काम यहीं होता है। हम उस लिंक को लेते हैं, उस पर क्लिक करते हैं, और उसके बाद विवरण पृष्ठ पर जाते हैं जहां हम उसका डेटा निकालना शुरू कर सकते हैं। उस पृष्ठ पर हमें नई साइट के लिए अपने नए मार्कडाउन एपिसोड लिखने के लिए आवश्यक सभी जानकारी मिलती है।
लिखें_पृष्ठ को परिभाषित करें
extracted_data = extract_data(detail_page)
def Extract_data
def extract_data(detail_page)
interviewee = extract_interviewee(detail_page)
title = extract_title(detail_page)
sc_id = extract_soundcloud_id(detail_page)
text = extract_shownotes_text(detail_page)
episode_subtitle = extract_subtitle(detail_page)
episode_number = extract_episode_number(episode_subtitle)
date = clean_date(episode_subtitle)
tags = build_tags(title, interviewee)
options = {
interviewee: interviewee,
title: title,
sc_id: sc_id,
text: text,
tags: tags,
date: date,
episode_number: episode_number
}
end
जैसा कि आप ऊपर देख सकते हैं, हम उस detail_page को लेते हैं और उस पर निष्कर्षण विधियों का एक गुच्छा लागू करें। हम interviewee . को निकालते हैं , title , sc_id , text , episode_title , और episode_number . मैंने इन निष्कर्षण जिम्मेदारियों के प्रभारी केंद्रित सहायक विधियों के एक समूह को दोबारा प्रतिक्रिया दी। आइए उन पर एक त्वरित नज़र डालें:
सहायक तरीके
निष्कर्षण के तरीके
मैंने इन सहायकों को निकाला क्योंकि इसने मुझे समग्र रूप से छोटे तरीके बनाने में सक्षम बनाया। उनके व्यवहार को समाहित करना भी महत्वपूर्ण था। कोड भी बेहतर पढ़ता है। उनमें से अधिकतर detail_page लेते हैं एक तर्क के रूप में और कुछ विशिष्ट डेटा निकालें जो हमें हमारे मध्यस्थ पदों के लिए चाहिए।
def extract_interviewee(detail_page) interviewee_selector = '.episode_sub_title span' detail_page.search(interviewee_selector).text.strip end
हम एक विशिष्ट चयनकर्ता के लिए पृष्ठ खोजते हैं और अनावश्यक सफेद स्थान के बिना पाठ प्राप्त करते हैं।
def extract_title(detail_page) title_selector = ".episode_title" detail_page.search(title_selector).text.gsub(/[?#]/, '') end
हम शीर्षक लेते हैं और ? . हटाते हैं और # चूंकि ये हमारे एपिसोड के लिए पोस्ट में सामने वाले मामले के साथ अच्छी तरह से नहीं खेलते हैं। सामने की बात के बारे में नीचे और अधिक।
def extract_soundcloud_id(detail_page)
sc = detail_page.iframes_with(href: /soundcloud.com/).to_s
sc.scan(/\d{3,}/).first
end
यहां हमें अपने होस्ट किए गए ट्रैक के लिए साउंडक्लाउड आईडी निकालने के लिए थोड़ी अधिक मेहनत करने की आवश्यकता है। सबसे पहले हमें href . के साथ मैकेनाइज आईफ्रेम की जरूरत है soundcloud.com . का और इसे स्कैनिंग के लिए एक स्ट्रिंग बनाएं...
"[#<Mechanize::Page::Frame\n nil\n \"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/221003494&auto_play=false&hide_related=false&show_comments=false&show_user=true&show_reposts=false&visual=true\">\n]"
फिर ट्रैक आईडी के अंकों के लिए रेगुलर एक्सप्रेशन का मिलान करें—हमारी soundcloud_id "221003494" ।
def extract_shownotes_text(detail_page) shownote_selector = "#shownote_container > p" detail_page.search(shownote_selector) end
शो नोट्स निकालना फिर से काफी सीधा है। हमें केवल विवरण पृष्ठ में शो नोट्स के पैराग्राफ देखने की जरूरत है। यहां कोई आश्चर्य नहीं है।
def extract_subtitle(detail_page) subheader_selector = ".episode_sub_title" detail_page.search(subheader_selector).text end
सबटाइटल के लिए भी यही बात लागू होती है, सिवाय इसके कि यह सिर्फ एपिसोड नंबर को साफ-सुथरा तरीके से निकालने की तैयारी है।
def extract_episode_number(episode_subtitle) number = /[#]\d*/.match(episode_subtitle) clean_episode_number(number) end
यहां हमें नियमित अभिव्यक्ति के एक और दौर की जरूरत है। आइए रेगेक्स लागू करने से पहले और बाद में देखें।
एपिसोड_उपशीर्षक
" João Ferreira | 12 Minutes | Aug 26, 2015 | Episode #139 "
संख्या
"#139"
एक और कदम जब तक हमारे पास एक साफ नंबर न हो।
def clean_episode_number(number)
number.to_s.tr('#', '')
end
हम उस नंबर को हैश के साथ लेते हैं # और इसे हटा दें। Voilà, हमारे पास हमारा पहला एपिसोड नंबर है 139 साथ ही निकाला। मेरा सुझाव है कि हम सभी को एक साथ लाने से पहले अन्य उपयोगिता विधियों को भी देखें।
उपयोगिता के तरीके
उस निष्कर्षण व्यवसाय के बाद, हमें कुछ सफाई करनी है। हम मार्कडाउन की रचना के लिए डेटा तैयार करना शुरू कर सकते हैं। उदाहरण के लिए, मैं episode_subtitle को काटता हूं एक साफ तारीख पाने के लिए और tags . बनाने के लिए कुछ और build_tags . के साथ तरीका।
def clean_date
def clean_date(episode_subtitle) string_date = /[^|]*([,])(.....)/.match(episode_subtitle).to_s Date.parse(string_date) end
हम एक और रेगेक्स चलाते हैं जो इस तरह की तारीखों की तलाश करता है: " Aug 26, 2015" . जैसा कि आप देख सकते हैं, यह अभी तक बहुत मददगार नहीं है। string_date . से हमें उपशीर्षक से मिलता है, हमें एक वास्तविक Date बनाना होगा वस्तु। अन्यथा यह बिचौलियों के पद सृजित करने के लिए बेकार होगा।
string_date
" Aug 26, 2015"
इसलिए हम उस स्ट्रिंग को लेते हैं और एक Date.parse करते हैं . परिणाम बहुत अधिक आशाजनक दिखता है।
तारीख
2015-08-26
बिल्ड_टैग को परिभाषित करें
def build_tags(title, interviewee)
extracted_tags = strip_pipes(title)
"#{interviewee}"+ ", #{extracted_tags}"
end
यह title लेता है और interviewee हमने extract_data . के अंदर बनाया है विधि और सभी पाइप वर्णों और जंक को हटा देता है। हम पाइप वर्णों को अल्पविराम से बदलते हैं, @ , ? , # , और & एक खाली स्ट्रिंग के साथ, और अंत में with . के लिए संक्षिप्ताक्षरों का ध्यान रखें .
डिफ स्ट्रिप_पाइप्स
def strip_pipes(text)
tags = text.tr('|', ',')
tags = tags.gsub(/[@?#&]/, '')
tags.gsub(/[w\/]{2}/, 'with')
end
अंत में हम टैग सूची में साक्षात्कारकर्ता का नाम भी शामिल करते हैं, और प्रत्येक टैग को अल्पविराम से अलग करते हैं।
पहले
"Masters @ Work | Subvisual | Deadlines | Design personality | Design problems | Team | Pushing envelopes | Delightful experiences | Perfecting details | Company values"
बाद
"João Ferreira, Masters Work , Subvisual , Deadlines , Design personality , Design problems , Team , Pushing envelopes , Delightful experiences , Perfecting details , Company values"
इनमें से प्रत्येक टैग उस विषय के लिए पोस्ट के संग्रह का लिंक बन जाएगा। यह सब extract_data . के अंदर हुआ तरीका। आइए एक और नजर डालते हैं कि हम कहां हैं:
def Extract_data
def extract_data(detail_page)
interviewee = extract_interviewee(detail_page)
title = extract_title(detail_page)
sc_id = extract_soundcloud_id(detail_page)
text = extract_shownotes_text(detail_page)
episode_subtitle = extract_subtitle(detail_page)
episode_number = extract_episode_number(episode_subtitle)
date = clean_date(episode_subtitle)
tags = build_tags(title, interviewee)
options = {
interviewee: interviewee,
title: title,
sc_id: sc_id,
text: text,
tags: tags,
date: date,
episode_number: episode_number
}
end
यहां जो कुछ करना बाकी है, वह हमारे द्वारा निकाले गए डेटा के साथ एक विकल्प हैश लौटाना है। हम इस हैश को compose_markdown . में फीड कर सकते हैं विधि, जो हमारे डेटा को एक फ़ाइल के रूप में लिखने के लिए तैयार करती है जिसकी मुझे मेरी नई साइट के लिए आवश्यकता है।
पोस्ट लिखना
डिफ कंपोज़_मार्कडाउन
def compose_markdown(options={})
<<-HEREDOC
---
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
---
#{options[:text]}
HEREDOC
end
मेरी मिडलमैन साइट पर पॉडकास्ट एपिसोड प्रकाशित करने के लिए, मैंने इसके ब्लॉगिंग सिस्टम को फिर से तैयार करने का विकल्प चुना। "शुद्ध" ब्लॉग पोस्ट बनाने के बजाय, मैं अपने एपिसोड के लिए शो नोट्स बनाता हूं जो साउंडक्लाउड होस्ट किए गए एपिसोड को iframes के माध्यम से प्रदर्शित करते हैं। इंडेक्स साइट्स पर, मैं केवल उस आईफ्रेम प्लस शीर्षक और सामान को प्रदर्शित करता हूं।
इसके लिए काम करने के लिए मुझे जिस प्रारूप की आवश्यकता है, वह फ्रंट मैटर नामक किसी चीज़ से बना है। यह मूल रूप से मेरी स्थिर साइटों के लिए एक कुंजी/मूल्य स्टोर है। यह मेरी पुरानी सिनात्रा साइट से मेरी डेटाबेस जरूरतों को बदल रहा है।
साक्षात्कारकर्ता का नाम, तिथि, साउंडक्लाउड ट्रैक आईडी, एपिसोड नंबर आदि जैसे डेटा तीन डैश (--- के बीच में चला जाता है। ) हमारे एपिसोड फाइलों के शीर्ष पर। नीचे प्रत्येक एपिसोड के लिए सामग्री आती है- जैसे प्रश्न, लिंक, प्रायोजक सामग्री, आदि।
फ्रंट मैटर
--- key: value key: value key: value key: value --- Episode content goes here.
compose_markdown . में विधि, मैं एक HEREDOC . का उपयोग करता हूं प्रत्येक एपिसोड के लिए उस फ़ाइल को उसके सामने वाले पदार्थ के साथ लिखने के लिए जिसे हम लूप करते हैं। विकल्प हैश से हम इस विधि को खिलाते हैं, हम extract_data में एकत्र किए गए सभी डेटा को निकालते हैं सहायक विधि।
डिफ कंपोज़_मार्कडाउन
...
<<-HEREDOC
---
title: #{options[:interviewee]}
interviewee: #{options[:interviewee]}
topic_list: #{options[:title]}
tags: #{options[:tags]}
soundcloud_id: #{options[:sc_id]}
date: #{options[:date]}
episode_number: #{options[:episode_number]}
---
#{options[:text]}
HEREDOC
...
यह वहीं पर एक नए पॉडकास्ट एपिसोड का खाका है। हम इसी लिए आए हैं। शायद आप इस विशेष सिंटैक्स के बारे में सोच रहे हैं: #{options[:interviewee]} . मैं हमेशा की तरह स्ट्रिंग्स के साथ इंटरपोलेट करता हूं, लेकिन चूंकि मैं पहले से ही <<-HEREDOC के अंदर हूं , मैं दोहरे उद्धरण चिह्नों को छोड़ सकता हूं।
बस खुद को उन्मुख करने के लिए, हम अभी भी लूप में हैं, write_page . के अंदर एक एकल एपिसोड के शो नोट्स के साथ एक विवरण पृष्ठ पर क्लिक किए गए प्रत्येक लिंक के लिए फ़ंक्शन। आगे क्या होता है इस खाका को फाइल सिस्टम में लिखने की तैयारी कर रहा है। दूसरे शब्दों में, हम एक फ़ाइल नाम और रचना markdown_text . प्रदान करके वास्तविक एपिसोड बनाते हैं .
उस अंतिम चरण के लिए, हमें केवल निम्नलिखित सामग्री तैयार करने की आवश्यकता है:तिथि, साक्षात्कारकर्ता का नाम और एपिसोड संख्या। साथ ही markdown_text बेशक, जो हमें अभी compose_markdown . से मिला है .
लिखें_पृष्ठ को परिभाषित करें
...
markdown_text = compose_markdown(extracted_data)
date = extracted_data[:date]
interviewee = extracted_data[:interviewee]
episode_number = extracted_data[:episode_number]
file_name = "#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md"
...
तब हमें केवल file_name . लेने की जरूरत है और markdown_text और फ़ाइल लिखें।
लिखें_पृष्ठ को परिभाषित करें
...
File.open(file_name, 'w') { |file| file.write(markdown_text) }
...
आइए इसे भी तोड़ दें। प्रत्येक पोस्ट के लिए, मुझे एक विशिष्ट प्रारूप की आवश्यकता है:2016-10-25-Avdi-Grimm-120 जैसा कुछ . मैं तारीख से शुरू होने वाली फाइलों को लिखना चाहता हूं और साक्षात्कारकर्ता का नाम और एपिसोड नंबर शामिल करना चाहता हूं।
बिचौलिए के नए पदों के लिए अपेक्षित प्रारूप से मेल खाने के लिए, मुझे साक्षात्कारकर्ता का नाम लेना होगा और इसे मेरी सहायक विधि के माध्यम से dasherize पर रखना होगा। मेरे लिए नाम, Avdi Grimm . से करने के लिए Avdi-Grimm . कुछ भी जादू नहीं, लेकिन देखने लायक:
डेशराइज़ करें
def dasherize(text)
text.lstrip.rstrip.tr(' ', '-')
end
यह उस टेक्स्ट से व्हॉट्सएप को हटा देता है जिसे हमने साक्षात्कारकर्ता के नाम के लिए स्क्रैप किया था और अवडी और ग्रिम के बीच के सफेद स्थान को डैश से बदल देता है। शेष फ़ाइल नाम स्ट्रिंग में ही एक साथ डैश किया गया है: "date-interviewee-name-episodenumber" .
लिखें_पृष्ठ को परिभाषित करें
...
"#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md"
...
चूंकि निकाली गई सामग्री सीधे एक HTML साइट से आती है, इसलिए मैं केवल .md . का उपयोग नहीं कर सकता या .markdown फ़ाइल नाम एक्सटेंशन के रूप में. मैंने .html.erb.md . के साथ जाने का फैसला किया . भविष्य के एपिसोड के लिए जिन्हें मैं स्क्रैप किए बिना लिखता हूं, मैं .html.erb . को छोड़ सकता हूं भाग और केवल .md need की आवश्यकता है .
इस चरण के बाद, scrape . में लूप समारोह समाप्त होता है, और हमारे पास एक ऐसा एपिसोड होना चाहिए जो इस तरह दिखता है:
2014-12-01-Avdi-Grimm-1.html.erb.md
--- title: Avdi Grimm interviewee: Avdi Grimm topic_list: What is Rake | Origins | Jim Weirich | Common use cases | Advantages of Rake tags: Avdi Grimm, What is Rake , Origins , Jim Weirich , Common use cases , Advantages of Rake soundcloud_id: 179619755 date: 2014-12-01 episode_number: 1 --- Questions: - What is Rake? - What can you tell us about the origins of Rake? - What can you tell us about Jim Weihrich? - What are the most common use cases for Rake? - What are the most notable advantages of Rake? Links: In">http://www.youtube.com/watch?v=2ZHJSrF52bc">In memory of the great Jim Weirich Rake">https://github.com/jimweirich/rake">Rake on GitHub Jim">https://github.com/jimweirich">Jim Weirich on GitHub Basic">http://www.youtube.com/watch?v=AFPWDzHWjEY">Basic Rake talk by Jim Weirich Power">http://www.youtube.com/watch?v=KaEqZtulOus">Power Rake talk by Jim Weirich Learn">http://devblog.avdi.org/2014/04/30/learn-advanced-rake-in-7-episodes/">Learn advanced Rake in 7 episodes - from Avdi Grimm ( free ) Avdi">http://about.avdi.org/">Avdi Grimm Avdi Grimm’s screencasts: Ruby">http://www.rubytapas.com/">Ruby Tapas Ruby">http://devchat.tv/ruby-rogues/">Ruby Rogues podcast with Avdi Grimm Great ebook: Rake">http://www.amazon.com/Rake-Management-Essentials-Andrey-Koleshko/dp/1783280778">Rake Task Management Essentials fromhttps://twitter.com/ka8725"> Andrey Koleshkoसे
यह स्क्रैपर निश्चित रूप से आखिरी एपिसोड में शुरू होगा, और पहले तक लूप करेगा। प्रदर्शन उद्देश्यों के लिए, एपिसोड 01 उतना ही अच्छा है जितना कि कोई भी। आप हमारे द्वारा निकाले गए डेटा के साथ सबसे ऊपर की बात देख सकते हैं।
वह सब पहले मेरे सिनात्रा ऐप-एपिसोड नंबर, तिथि, साक्षात्कारकर्ता का नाम, और इसी तरह के डेटाबेस में बंद था। अब हमने इसे मेरी नई स्थिर मिडलमैन साइट का हिस्सा बनने के लिए तैयार कर लिया है। दो ट्रिपल डैश के नीचे सब कुछ (--- ) शो नोट्स का टेक्स्ट है:प्रश्न और लिंक ज्यादातर।
अंतिम विचार
और हम कर रहे हैं। मेरा नया पॉडकास्ट पहले से ही चल रहा है। मुझे वास्तव में खुशी है कि मैंने जमीन से ऊपर की चीज को फिर से डिजाइन करने के लिए समय निकाला। अब नए एपिसोड प्रकाशित करना बहुत अच्छा है। नई सामग्री की खोज करना उपयोगकर्ताओं के लिए भी आसान होना चाहिए।
जैसा कि मैंने पहले उल्लेख किया है, यही वह समय है जब आपको कुछ मज़ा लेने के लिए अपने कोड संपादक में जाना चाहिए। इस कोड को लें और इसके साथ थोड़ा कुश्ती करें। इसे आसान बनाने के तरीके खोजने की कोशिश करें। कोड को दोबारा करने के कुछ अवसर हैं।
कुल मिलाकर, मुझे आशा है कि इस छोटे से उदाहरण ने आपको एक अच्छा विचार दिया है कि आप अपने नए वेब स्क्रैपिंग चॉप के साथ क्या कर सकते हैं। बेशक आप बहुत अधिक परिष्कृत चुनौतियों को प्राप्त कर सकते हैं- मुझे यकीन है कि इन कौशलों के साथ बहुत से छोटे व्यवसाय के अवसर भी बनाए जा सकते हैं।
लेकिन हमेशा की तरह, इसे एक बार में एक कदम उठाएं, और अगर चीजें तुरंत क्लिक न करें तो बहुत निराश न हों। यह न केवल अधिकांश लोगों के लिए सामान्य है बल्कि अपेक्षित भी है। यह यात्रा का हिस्सा है। हैप्पी स्क्रैपिंग!