यदि आपको पाठ का एक बड़ा संग्रह दिया जाए और आप उसमें से कुछ अर्थ निकालना चाहते हैं, तो आप क्या करेंगे?
अपने टेक्स्ट को n-grams . में विभाजित करना एक अच्छी शुरुआत है ।
यहां एक विवरण दिया गया है :
<ब्लॉकक्वॉट>कम्प्यूटेशनल भाषाविज्ञान और संभाव्यता के क्षेत्र में, एक n-ग्राम पाठ के दिए गए अनुक्रम से n वस्तुओं का एक सन्निहित अनुक्रम है। - विकिपीडिया
उदाहरण के लिए :
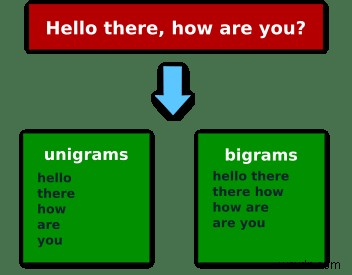
यदि हम वाक्यांश "हैलो देयर, हाउ आर यू?" तब यूनिग्राम (एक तत्व के ngrams) होंगे:"Hello", "there", "how", "are", "you" , और बिग्राम (दो तत्वों के ngrams):["Hello", "there"], ["there", "how"], ["how", "are"], ["are", "you"] ।
यदि आप छवियों के साथ बेहतर सीखते हैं तो यहां उसकी एक तस्वीर है:
अब देखते हैं कि आप इसे रूबी में कैसे लागू कर सकते हैं!
नमूना डेटा डाउनलोड करना
इससे पहले कि हम अपने हाथों को गंदा कर सकें, हमें कुछ नमूना डेटा की आवश्यकता होगी।
यदि आपके पास काम करने के लिए कोई नहीं है तो आप कुछ विकिपीडिया या ब्लॉग लेख डाउनलोड कर सकते हैं। इस विशेष मामले में, मैंने #ruby freenode के चैनल से कुछ IRC लॉग डाउनलोड करने का निर्णय लिया।
लॉग यहां पाए जा सकते हैं :
irclog.whitequark.org/ruby
डेटा प्रारूपों पर एक नोट :
यदि आप जिस संसाधन का विश्लेषण करना चाहते हैं उसका एक सादा पाठ संस्करण उपलब्ध नहीं है, तो आप पृष्ठ को पार्स करने और डेटा निकालने के लिए नोकोगिरी का उपयोग कर सकते हैं।
आईआरसी लॉग .txt . जोड़कर सादे पाठ में उपलब्ध हैं URL के अंत में ताकि हम उसका लाभ उठा सकें।
यह क्लास हमारे लिए डेटा डाउनलोड और सेव करेगी:
require 'restclient'
class LogParser
LOG_DIR = 'irc_logs'
def initialize(date)
@date = date
@log_name = "#{LOG_DIR}/irc-log-#{@date}.txt"
end
def download_page(url)
return log_contents if File.exist? @log_name
RestClient.get(url).body
end
def save_page(page)
File.open(@log_name, "w+") { |f| f.puts page }
end
def log_contents
File.readlines(@log_name).join
end
def get_messages
page = download_page("https://irclog.whitequark.org/ruby/#{@date}.txt")
save_page(page)
page
end
end
log = LogParser.new("2015-04-15")
msg = log.get_messages
यह काफी सीधा-सादा वर्ग है।
हम अपने HTTP क्लाइंट के रूप में RestClient का उपयोग करते हैं और फिर हम परिणामों को एक फ़ाइल में सहेजते हैं ताकि हमें अपने प्रोग्राम में संशोधन करते समय उन्हें कई बार अनुरोध न करना पड़े।
डेटा का विश्लेषण करना
अब जब हमारे पास अपना डेटा है तो हम उसका विश्लेषण कर सकते हैं।
यहाँ एक साधारण Ngram वर्ग है।
इस वर्ग में हम Array#each_cons पद्धति का उपयोग करते हैं जो ngrams उत्पन्न करती है।
क्योंकि यह विधि एक Enumerator लौटाती है हमें to_a . पर कॉल करने की आवश्यकता है उस पर Array प्राप्त करने के लिए ।
class Ngram
def initialize(input)
@input = input
end
def ngrams(n)
@input.split.each_cons(n).to_a
end
end
फिर हम लूप का उपयोग करके सब कुछ एक साथ रखते हैं, Hash#merge! &Enumerable#sort_by ।
इसे पसंद करें :
# Filter words that appear less times than this
MIN_REPETITIONS = 20
total = {}
# Get the logs for the first 15 days of the month and return the bigrams
(1..15).each do |n|
day = '%02d' % [n]
total.merge!(get_trigrams_for_date "2015-04-#{day}") { |k, old, new| old + new }
end
# Sort in descending order
total = total.sort_by { |k, v| -v }.reject { |k, v| v < MIN_REPETITIONS }
total.each { |k, v| puts "#{v} => #{k}" }
<ब्लॉकक्वॉट>
नोट:get_trigrams_for_date विधि यहाँ संक्षिप्तता के लिए नहीं है, लेकिन आप इसे जीथब पर पा सकते हैं।
आउटपुट ऐसा दिखता है :
112 => i want to 83 => link for more 82 => is there a 71 => you want to 66 => i don't know 66 => i have a 65 => i need to
जैसा कि आप देख सकते हैं कि चीजों को करने की इच्छा #ruby 🙂
. में बहुत लोकप्रिय हैनिष्कर्ष
अब आपकी बारी है!
अपने संपादक को क्रैक करें और कुछ एन-ग्राम विश्लेषण के साथ खेलना शुरू करें। n-grams को क्रिया में देखने का दूसरा तरीका Google Ngram व्यूअर है।
<ब्लॉकक्वॉट>प्राकृतिक भाषा प्रसंस्करण (एनएलपी) एक आकर्षक विषय हो सकता है, विकिपीडिया के पास इस विषय का अच्छा अवलोकन है।
आप इस पोस्ट का पूरा कोड यहां देख सकते हैं:https://github.com/matugm/ngram-analysis/blob/master/irc_histogram.rb