Github पर पूर्ण स्रोत
स्टॉफ़ल प्रोग्रामिंग भाषा का पूर्ण कार्यान्वयन GitHub पर उपलब्ध है। कोड को पढ़ने को आसान बनाने में मदद करने के लिए इस संदर्भ कार्यान्वयन में बहुत सारी टिप्पणियाँ हैं। अगर आपको बग मिलते हैं या आपके कोई प्रश्न हैं, तो बेझिझक कोई समस्या खोलें।
इस ब्लॉग पोस्ट में, हम स्टॉफ़ल के लिए पार्सर को लागू करने जा रहे हैं, जो पूरी तरह से रूबी में निर्मित एक खिलौना प्रोग्रामिंग भाषा है। आप इस श्रृंखला के पहले भाग में इस परियोजना के बारे में अधिक पढ़ सकते हैं।
खरोंच से एक पार्सर बनाने से मुझे कुछ अप्रत्याशित अंतर्दृष्टि और ज्ञान मिला। मुझे लगता है कि यह अनुभव हर व्यक्ति के लिए अलग-अलग हो सकता है, लेकिन मुझे लगता है कि यह मान लेना सुरक्षित है कि इस लेख के बाद, आपने निम्न में से कम से कम एक के बारे में अपना ज्ञान प्राप्त कर लिया होगा या गहरा कर लिया होगा:
- आप स्रोत कोड को अलग तरह से देखना शुरू कर देंगे और इसकी निर्विवाद पेड़ जैसी संरचना पर ध्यान देंगे बहुत अधिक आसानी से;
- आपको सिंटैक्टिक शुगर की गहरी समझ होगी और इसे हर जगह देखना शुरू कर देगा, चाहे वह स्टॉफ़ल, रूबी या अन्य प्रोग्रामिंग भाषाओं में हो।
मुझे लगता है कि एक पार्सर पारेतो सिद्धांत का एक आदर्श उदाहरण है। कुछ अतिरिक्त-अच्छी सुविधाओं को बनाने के लिए आवश्यक काम की मात्रा, जैसे कि भयानक त्रुटि संदेश, स्पष्ट रूप से अधिक है और मूल बातें प्राप्त करने और चलाने के लिए आवश्यक प्रयास के अनुपात में नहीं है। हम आवश्यक पर ध्यान केंद्रित करेंगे और सुधारों को आपके लिए चुनौती के रूप में छोड़ देंगे, मेरे प्रिय पाठक। हम इस श्रृंखला के बाद के लेख में कुछ और दिलचस्प अतिरिक्त चीजों को संभाल सकते हैं या नहीं भी कर सकते हैं।
<ब्लॉकक्वॉट>सिंटैक्टिक शुगर
वाक्यात्मक चीनी एक अभिव्यक्ति है जिसका उपयोग उन निर्माणों को निरूपित करने के लिए किया जाता है जो किसी भाषा को उपयोग में आसान बनाते हैं, लेकिन जिसके हटाने से प्रोग्रामिंग भाषा की कार्यक्षमता कम नहीं होगी। रूबी का elsif इसका एक अच्छा उदाहरण है निर्माण। स्टॉफ़ल में, हमारे पास ऐसी कोई संरचना नहीं है, इसलिए इसे व्यक्त करने के लिए हमें और अधिक क्रियात्मक होने के लिए मजबूर होना पड़ता है:
if some_condition
# ...
else # oops, no elsif available
if another_condition
# ...
end
end
पार्सर क्या है?
हम स्रोत कोड से शुरू करते हैं, वर्णों का एक कच्चा अनुक्रम। फिर, जैसा कि इस श्रृंखला में पिछले लेख में दिखाया गया है, लेक्सर इन वर्णों को टोकन नामक समझदार डेटा संरचनाओं में समूहित करता है। हालाँकि, हमारे पास अभी भी डेटा है जो पूरी तरह से सपाट है, कुछ ऐसा जो अभी भी स्रोत कोड की नेस्टेड प्रकृति का उचित रूप से प्रतिनिधित्व नहीं करता है। इस प्रकार, वर्णों के इस क्रम से एक पेड़ बनाने का काम पार्सर के पास है। जब यह अपना कार्य पूरा कर लेता है, तो हम डेटा के साथ समाप्त हो जाते हैं जो अंततः यह व्यक्त करने में सक्षम होते हैं कि हमारे कार्यक्रम का प्रत्येक भाग कैसे घोंसला बनाता है और एक दूसरे से संबंधित है।
पार्सर द्वारा बनाए गए पेड़ को आम तौर पर एब्सट्रैक्ट सिंटैक्स ट्री (एएसटी) कहा जाता है। जैसा कि नाम से ही स्पष्ट है, हम एक ट्री डेटा स्ट्रक्चर के साथ काम कर रहे हैं, जिसकी जड़ खुद प्रोग्राम का प्रतिनिधित्व करती है और इस प्रोग्राम नोड के बच्चे हमारे प्रोग्राम को बनाने वाले कई भाव हैं। शब्द सार एएसटी में सार दूर . करने की हमारी क्षमता को दर्शाता है भाग जो, पिछले चरणों में, स्पष्ट रूप से मौजूद थे। एक अच्छा उदाहरण है एक्सप्रेशन टर्मिनेटर (स्टॉफ़ल के मामले में नई लाइनें); एएसटी का निर्माण करते समय उन पर विचार किया जाता है, लेकिन टर्मिनेटर का प्रतिनिधित्व करने के लिए हमें एक विशिष्ट नोड प्रकार की आवश्यकता नहीं होती है। हालांकि, याद रखें, हमारे पास एक स्पष्ट टोकन था टर्मिनेटर का प्रतिनिधित्व करने के लिए।
क्या एएसटी उदाहरण का विज़ुअलाइज़ेशन उपयोगी नहीं होगा? आपकी इच्छा एक आदेश है! नीचे एक सरल स्टॉफ़ल प्रोग्राम है, जिसे हम इस पोस्ट में बाद में चरण-दर-चरण पार्स करेंगे, और इसके संगत सार सिंटैक्स ट्री:
fn double: num
num * 2
end
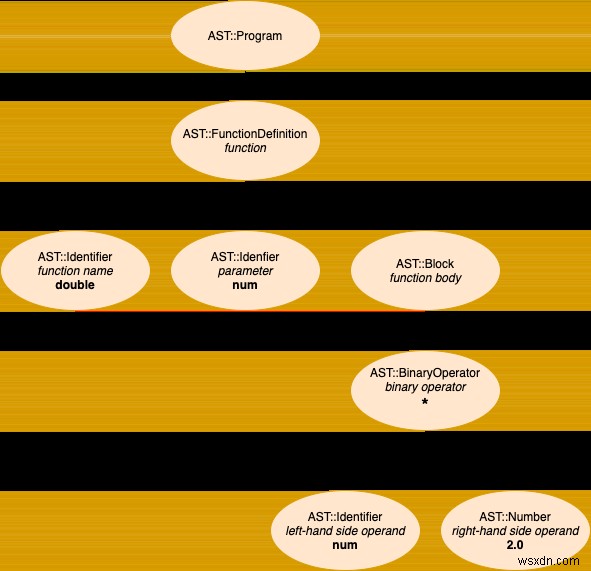
स्रोत से AST तक, पहला उदाहरण
पोस्ट के इस भाग में, हम चरण-दर-चरण यह पता लगाने जा रहे हैं कि हमारा पार्सर बहुत को कैसे संभालता है सरल स्टॉफ़ल प्रोग्राम, एक एकल पंक्ति से बना है जिसमें एक चर बंधन व्यक्त किया जाता है (यानी, हम एक चर के लिए एक मान निर्दिष्ट करते हैं)। यहां स्रोत है, लेक्सर द्वारा उत्पादित टोकन का सरलीकृत प्रतिनिधित्व (ये टोकन हमारे पार्सर को दिए गए इनपुट हैं) और अंत में, एएसटी का एक दृश्य प्रतिनिधित्व जिसे हम कार्यक्रम का प्रतिनिधित्व करने के लिए तैयार करने जा रहे हैं:
स्रोत
my_var = 1
टोकन (लेक्सर का आउटपुट, पार्सर के लिए इनपुट)
[:identifier, :'=', :number]
पार्सर के आउटपुट का दृश्य प्रतिनिधित्व (एक सार सिंटैक्स ट्री)
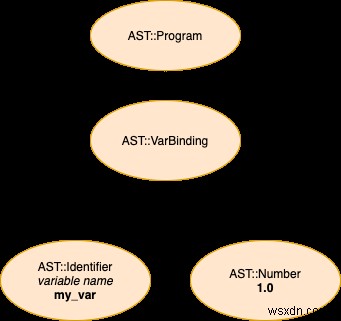
जैसा कि आप कल्पना कर सकते हैं, हमारे पार्सर का मूल हमारे लेक्सर के मूल के समान है। लेक्सर के मामले में, हमारे पास संसाधित करने के लिए पात्रों का एक समूह था। अब, हमें अभी भी एक संग्रह पर पुनरावृति करनी है, लेकिन पार्सर के मामले में, हम अपने लेक्सर मित्र द्वारा निर्मित टोकन की सूची पर जाएंगे। हमारे पास एक ही सूचक है (@next_p ) टोकन के संग्रह में हमारी स्थिति पर नज़र रखने के लिए। यह सूचक अगला . को चिह्नित करता है टोकन संसाधित किया जाना है। यद्यपि हमारे पास केवल यह एकल सूचक है, हमारे पास कई अन्य "आभासी" संकेत हैं जिनका हम आवश्यकतानुसार उपयोग कर सकते हैं; जैसे ही हम कार्यान्वयन के साथ आगे बढ़ेंगे वे दिखाई देंगे। ऐसा ही एक "वर्चुअल" पॉइंटर है वर्तमान (मूल रूप से, @next_p - 1 . पर टोकन )।
#पार्स टोकन को एएसटी में बदलने के लिए कॉल करने की विधि है, जो @ast पर उपलब्ध होगी। उदाहरण चर। #parse . का क्रियान्वयन सीधा है। हम #consume . पर कॉल करके संग्रह के माध्यम से आगे बढ़ना जारी रखते हैं और चल रहा है @next_p जब तक संसाधित होने के लिए कोई और टोकन नहीं हैं (यानी, जबकि next_p #parse_expr_recursively एक एएसटी नोड या कुछ भी नहीं लौटा सकता है; याद रखें, उदाहरण के लिए, हमें एएसटी में टर्मिनेटरों का प्रतिनिधित्व करने की आवश्यकता नहीं है। यदि लूप के वर्तमान पुनरावृत्ति में एक नोड बनाया गया था, तो हम इसे @ast . में जोड़ते हैं जारी रखने से पहले। यह ध्यान रखना महत्वपूर्ण है कि #parse_expr_recursively @next_p भी चल रहा है चूंकि, जब हम एक टोकन पाते हैं जो एक विशिष्ट निर्माण की शुरुआत को चिह्नित करता है, तो हमें कई बार आगे बढ़ना होगा जब तक कि हम अंत में पूरी तरह से एक नोड का निर्माण करने में सक्षम नहीं होते हैं जो हम वर्तमान में पार्स कर रहे हैं। कल्पना कीजिए कि एक if . का प्रतिनिधित्व करने वाला एक नोड बनाने के लिए हमें कितने टोकन का उपभोग करना होगा ।
module Stoffle
class Parser
attr_accessor :tokens, :ast, :errors
# ...
def initialize(tokens)
@tokens = tokens
@ast = AST::Program.new
@next_p = 0
@errors = []
end
def parse
while pending_tokens?
consume
node = parse_expr_recursively
ast << node if node != nil
end
end
# ...
end
end
उपरोक्त स्निपेट में, पहली बार हमें कई प्रकार के एएसटी नोड्स में से एक के साथ प्रस्तुत किया गया था जो हमारे पार्सर कार्यान्वयन का हिस्सा हैं। नीचे, हमारे पास AST::Program . के लिए पूर्ण स्रोत कोड है नोड प्रकार। जैसा कि आप अनुमान लगा रहे होंगे, यह हमारे पेड़ की जड़ है, जो पूरे कार्यक्रम का प्रतिनिधित्व करती है। आइए इसके सबसे दिलचस्प अंशों पर करीब से नज़र डालें:
- एक स्टॉफ़ल प्रोग्राम
@expressions. से बना होता है; ये हैं#बच्चोंएकAST::Program. का नोड; - जैसा कि आप फिर से देखेंगे, प्रत्येक नोड प्रकार
#==. को लागू करता है तरीका। एक परिणाम के रूप में, दो सरल नोड्स की तुलना करना आसान है, साथ ही साथ पूरे प्रोग्राम को पूरी तरह से! दो कार्यक्रमों (या दो जटिल नोड्स) की तुलना करते समय, उनकी समानता प्रत्येक बच्चों की समानता, प्रत्येक बच्चों के प्रत्येक बच्चे की समानता, और इसी तरह से निर्धारित की जाएगी।#==. द्वारा उपयोग की जाने वाली यह सरल लेकिन शक्तिशाली कार्यनीति हमारे कार्यान्वयन के परीक्षण के लिए अत्यंत उपयोगी है।
class Stoffle::AST::Program
attr_accessor :expressions
def initialize
@expressions = []
end
def <<(expr)
expressions << expr
end
def ==(other)
expressions == other&.expressions
end
def children
expressions
end
end
एक्सप्रेशन बनाम स्टेटमेंट
कुछ भाषाओं में, कई संरचनाएँ कोई मूल्य नहीं उत्पन्न करती हैं; एक सशर्त एक क्लासिक उदाहरण है। इन्हें कथन . कहा जाता है . हालाँकि, अन्य निर्माण एक मूल्य (जैसे, एक फ़ंक्शन कॉल) का मूल्यांकन करते हैं। इन्हें अभिव्यक्ति . कहा जाता है . हालांकि, अन्य भाषाओं में, सब कुछ एक अभिव्यक्ति है और एक मूल्य पैदा करता है। रूबी इस दृष्टिकोण का एक उदाहरण है। उदाहरण के लिए, निम्न स्निपेट को IRB में टाइप करके यह पता लगाने का प्रयास करें कि एक विधि परिभाषा किस मूल्य का मूल्यांकन करती है:
irb(main):001:0> def two; 2; end
यदि आप आईआरबी को बंद करने का मन नहीं कर रहे हैं, तो मैं आपको खबर देता हूं; रूबी में, एक विधि परिभाषा अभिव्यक्ति एक प्रतीक (विधि का नाम) का मूल्यांकन करता है। जैसा कि आप जानते हैं, स्टॉफ़ल रूबी में बहुत अधिक प्रेरित है, इसलिए हमारी छोटी खिलौना भाषा में, सब कुछ भी एक अभिव्यक्ति है।
ध्यान रखें कि ये परिभाषाएं व्यावहारिक उद्देश्यों के लिए पर्याप्त हैं, लेकिन वास्तव में कोई आम सहमति नहीं है, और आप देख सकते हैं कि शब्दों के कथन और अभिव्यक्ति को कहीं और अलग तरह से परिभाषित किया जा रहा है।
गहराई से गोता लगाना:#parse_expr_recursively के कार्यान्वयन की शुरुआत
जैसा कि हमने अभी ऊपर के स्निपेट में देखा, #parse_expr_recursively संभावित रूप से एक नया एएसटी नोड बनाने के लिए कहा जाने वाला तरीका है। #parse_expr_recursively पार्सिंग प्रक्रिया में अन्य छोटे तरीकों के ढेरों का उपयोग करता है, लेकिन हम शांति से कह सकते हैं कि यह हमारे पार्सर का असली इंजन है। हालांकि यह बहुत लंबा नहीं है, इस विधि को पचाना अधिक कठिन है। इसलिए, हम इसे दो भागों में काटने जा रहे हैं। पोस्ट के इस खंड में, आइए इसके प्रारंभिक खंड से शुरू करते हैं, जो पहले से ही इतना शक्तिशाली है कि स्टॉफ़ल प्रोग्रामिंग भाषा के कुछ सरल भागों को पार्स कर सकता है। एक पुनश्चर्या के रूप में, याद रखें कि हम एक साधारण प्रोग्राम को पार्स करने के लिए आवश्यक चरणों से गुजर रहे हैं जिसमें एक एकल चर बाध्यकारी अभिव्यक्ति शामिल है:
स्रोत
my_var = 1
टोकन (लेक्सर का आउटपुट, पार्सर के लिए इनपुट)
[:identifier, :'=', :number]
टोकन को देखने के बाद हमें निपटना होगा और कल्पना करना होगा कि अन्य समान सरल अभिव्यक्तियों के लिए लेक्सर आउटपुट क्या होगा, टोकन प्रकारों को विशिष्ट पार्सिंग विधियों के साथ जोड़ने का प्रयास करना एक अच्छा विचार है:
def parse_expr_recursively
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
send(parsing_function)
end
#parse_expr_recursively . के इस प्रारंभिक कार्यान्वयन में , ठीक यही हम करते हैं। चूंकि काफी कुछ होगा विभिन्न टोकन प्रकारों को हमें संभालना होगा, इस निर्णय लेने की प्रक्रिया को एक अलग विधि से निकालना बेहतर है -#determine_parsing_function , जिसे हम एक पल में देखेंगे।
जब हम समाप्त कर लेंगे, तो कोई टोकन नहीं होना चाहिए जिसे हम नहीं पहचानते हैं, लेकिन एक सुरक्षा के रूप में, हम जांच करेंगे कि कोई पार्सिंग फ़ंक्शन वर्तमान टोकन से जुड़ा हुआ है या नहीं। अगर ऐसा नहीं है, तो हम अपने इंस्टेंस वेरिएबल @errors . में एक एरर जोड़ देंगे , जो पार्सिंग के दौरान हुई सभी समस्याओं को रखता है। हम इसे यहां विस्तार से कवर नहीं करेंगे, लेकिन यदि आप उत्सुक हैं तो आप गिटहब पर पार्सर के पूर्ण कार्यान्वयन की जांच कर सकते हैं।
#determine_parsing_function कॉल करने के लिए पार्सिंग विधि के नाम का प्रतिनिधित्व करने वाला एक प्रतीक देता है। हम रूबी के भेजें . का उपयोग करेंगे फ्लाई पर उपयुक्त विधि को कॉल करने के लिए।
पार्सिंग विधि का निर्धारण और एक वैरिएबल बाइंडिंग को पार्स करना
इसके बाद, आइए एक नज़र डालते हैं #determine_parsing_function . पर स्टॉफ़ल के विभिन्न निर्माणों को पार्स करने के लिए विशिष्ट तरीकों को कॉल करने के लिए इस प्रारंभिक तंत्र को समझने के लिए। #determine_parsing_function बाइनरी ऑपरेटरों को छोड़कर सब कुछ (जैसे, कीवर्ड और यूनरी ऑपरेटर) के लिए उपयोग किया जाएगा। हम बाद में बाइनरी ऑपरेटरों के मामले में इस्तेमाल की जाने वाली तकनीक का पता लगाएंगे। अभी के लिए, आइए देखें #determine_parsing_function :
def determine_parsing_function
if [:return, :identifier, :number, :string, :true, :false, :nil, :fn,
:if, :while].include?(current.type)
"parse_#{current.type}".to_sym
elsif current.type == :'('
:parse_grouped_expr
elsif [:"\n", :eof].include?(current.type)
:parse_terminator
elsif UNARY_OPERATORS.include?(current.type)
:parse_unary_operator
end
end
जैसा कि पहले बताया गया है, #current एक आभासी है टोकन के लिए सूचक इस समय संसाधित किया जा रहा है। #determine_parsing_function . का क्रियान्वयन बहुत सीधा है; हम वर्तमान टोकन को देखते हैं (विशेष रूप से, इसका प्रकार ) और कॉल करने के लिए उपयुक्त विधि का प्रतिनिधित्व करने वाला एक प्रतीक लौटाएं।
याद रखें कि हम एक वैरिएबल बाइंडिंग को पार्स करने के लिए आवश्यक चरणों से गुजर रहे हैं (my_var =1 ), इसलिए हम जिन टोकन प्रकारों को संभाल रहे हैं वे हैं [:identifier, :'=', :number] . वर्तमान टोकन प्रकार है :पहचानकर्ता , इसलिए #determine_parsing_function वापस आ जाएगा :parse_identifier , जैसा कि आप अनुमान लगा रहे होंगे। आइए हमारे अगले चरण पर नज़र डालें, #parse_identifier विधि:
def parse_identifier
lookahead.type == :'=' ? parse_var_binding : AST::Identifier.new(current.lexeme)
end
यहां, हमारे पास एक बहुत ही सरल अभिव्यक्ति है, मूल रूप से, अन्य सभी पार्स विधियां क्या करती हैं। #parse_identifier . में - और अन्य पार्स विधियों में - हम यह निर्धारित करने के लिए टोकन की जांच करते हैं कि हम जिस संरचना की अपेक्षा कर रहे हैं वह वास्तव में मौजूद है या नहीं। हम जानते हैं कि हमारे पास एक पहचानकर्ता है, लेकिन हमें यह निर्धारित करने के लिए अगले टोकन को देखना होगा कि क्या हम एक चर बंधन के साथ काम कर रहे हैं, जो कि अगले टोकन प्रकार के :'=' होने पर होगा। , या अगर हमारे पास केवल एक पहचानकर्ता है या अधिक जटिल अभिव्यक्ति में भाग ले रहा है। उदाहरण के लिए, एक अंकगणितीय व्यंजक की कल्पना करें जिसमें हम चरों में संग्रहीत मानों में हेर-फेर कर रहे हैं।
चूँकि हमारे पास एक :'=' है अगला आ रहा है, #parse_var_binding कहा जाने वाला है:
def parse_var_binding
identifier = AST::Identifier.new(current.lexeme)
consume(2)
AST::VarBinding.new(identifier, parse_expr_recursively)
end
यहां, हम उस पहचानकर्ता का प्रतिनिधित्व करने के लिए एक नया एएसटी नोड बनाकर शुरू करते हैं जिसे हम वर्तमान में संसाधित कर रहे हैं। AST::Identifier . के लिए कंस्ट्रक्टर पहचानकर्ता टोकन (यानी, वर्णों का क्रम, स्ट्रिंग "my_var" की शब्दावली की अपेक्षा करता है हमारे मामले में), इसलिए हम इसे आपूर्ति करते हैं। फिर हम प्रसंस्करण के तहत टोकन की धारा में दो स्थानों को आगे बढ़ाते हैं, जिससे टोकन प्रकार :number . बन जाता है अगले विश्लेषण किया जाना है। याद रखें कि हम [:identifier, :'=', :number] के साथ काम कर रहे हैं ।
अंत में, हम वैरिएबल बाइंडिंग का प्रतिनिधित्व करने वाले एएसटी नोड का निर्माण और वापसी करते हैं। AST::VarBinding . के लिए कंस्ट्रक्टर दो मापदंडों की अपेक्षा करता है:एक पहचानकर्ता एएसटी नोड (बाध्यकारी अभिव्यक्ति के बाईं ओर) और कोई भी मान्य अभिव्यक्ति (दाईं ओर)। यहाँ एक महत्वपूर्ण बात ध्यान देने योग्य है; वेरिएबल बाइंडिंग एक्सप्रेशन के दायीं ओर उत्पन्न करने के लिए, हम #parse_expr_recursively कहते हैं फिर से . यह पहली बार में थोड़ा अजीब लग सकता है, लेकिन ध्यान रखें कि एक चर एक बहुत ही जटिल अभिव्यक्ति के लिए बाध्य हो सकता है, न कि केवल एक संख्या के लिए, जैसा कि हमारे उदाहरण में है। यदि हम अपनी पार्सिंग रणनीति को एक शब्द में परिभाषित करते हैं, तो यह पुनरावर्ती . होगा . अब, मुझे लगता है कि आप समझना शुरू कर रहे हैं कि क्यों #parse_expr_recursively इसका नाम है।
इस अनुभाग को समाप्त करने से पहले, हमें जल्दी से AST::Identifier . दोनों का पता लगाना चाहिए और AST::VarBinding . सबसे पहले, AST::Identifier :
class Stoffle::AST::Identifier < Stoffle::AST::Expression
attr_accessor :name
def initialize(name)
@name = name
end
def ==(other)
name == other&.name
end
def children
[]
end
end
यहाँ कुछ भी फैंसी नहीं है। यह उल्लेखनीय है कि नोड चर के नाम को संग्रहीत करता है और उसके बच्चे नहीं होते हैं।
अब, AST::VarBinding :
class Stoffle::AST::VarBinding < Stoffle::AST::Expression
attr_accessor :left, :right
def initialize(left, right)
@left = left
@right = right
end
def ==(other)
children == other&.children
end
def children
[left, right]
end
end
बाईं ओर एक AST::Identifier है नोड. दाहिनी ओर लगभग हर संभव प्रकार का नोड है - एक साधारण संख्या से, जैसा कि हमारे उदाहरण में, कुछ अधिक जटिल - उस अभिव्यक्ति का प्रतिनिधित्व करता है जिससे पहचानकर्ता बाध्य है। #बच्चों वेरिएबल बाइंडिंग में से AST नोड्स @left . में होते हैं और @दाएं ।
स्रोत से AST तक, दूसरा उदाहरण
#parse_expr_recursively . का वर्तमान अवतार पहले से ही कुछ सरल भावों को पार्स करने में सक्षम है, जैसा कि हमने पिछले भाग में देखा था। इस खंड में, हम इसके कार्यान्वयन को समाप्त कर देंगे ताकि यह अधिक जटिल संस्थाओं, जैसे कि बाइनरी और लॉजिकल ऑपरेटरों को भी पार्स करने में सक्षम हो। यहां, हम चरण-दर-चरण पता लगाएंगे कि हमारा पार्सर किसी फ़ंक्शन को परिभाषित करने वाले प्रोग्राम को कैसे संभालता है। यहां स्रोत है, लेक्सर द्वारा निर्मित टोकन का सरलीकृत प्रतिनिधित्व और, जैसा कि हमने पहले खंड में किया था, एएसटी का एक दृश्य प्रतिनिधित्व हम कार्यक्रम का प्रतिनिधित्व करने के लिए तैयार करेंगे:
स्रोत
fn double: num
num * 2
end
टोकन (लेक्सर का आउटपुट, पार्सर के लिए इनपुट)
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
पार्सर आउटपुट का दृश्य प्रतिनिधित्व (एक सार सिंटैक्स ट्री)
इससे पहले कि हम आगे बढ़ें, आइए एक कदम पीछे हटें और ऑपरेटर वरीयता नियमों के बारे में बात करें। ये गणितीय सम्मेलनों पर आधारित हैं; गणित में, वे सिर्फ सम्मेलन हैं, और वास्तव में, कुछ भी मौलिक नहीं है जिसके परिणामस्वरूप हम ऑपरेटर प्राथमिकता का उपयोग करते हैं। ये नियम हमें किसी व्यंजक का मूल्यांकन करने के लिए सही क्रम निर्धारित करने और, हमारे मामले में, पहले इसे पार्स करने की अनुमति भी देते हैं। प्रत्येक ऑपरेटर की प्राथमिकता को परिभाषित करने के लिए, हमारे पास बस एक नक्शा है (यानी, एक Hash ) टोकन प्रकार और पूर्णांकों के। अधिक संख्या का मतलब है कि एक ऑपरेटर को पहले संभाला जाना चाहिए :
# We define these precedence rules at the top of Stoffle::Parser.
module Stoffle
class Parser
# ...
UNARY_OPERATORS = [:'!', :'-'].freeze
BINARY_OPERATORS = [:'+', :'-', :'*', :'/', :'==', :'!=', :'>', :'<', :'>=', :'<='].freeze
LOGICAL_OPERATORS = [:or, :and].freeze
LOWEST_PRECEDENCE = 0
PREFIX_PRECEDENCE = 7
OPERATOR_PRECEDENCE = {
or: 1,
and: 2,
'==': 3,
'!=': 3,
'>': 4,
'<': 4,
'>=': 4,
'<=': 4,
'+': 5,
'-': 5,
'*': 6,
'/': 6,
'(': 8
}.freeze
# ...
end
end
#parse_expr_recursively . में उपयोग की जाने वाली तकनीक कंप्यूटर वैज्ञानिक वॉन प्रैट द्वारा अपने 1973 के पेपर, "टॉप डाउन ऑपरेटर प्रिसिडेंस" में प्रस्तुत प्रसिद्ध पार्सर एल्गोरिथ्म पर आधारित है। जैसा कि आप देखेंगे, एल्गोरिथ्म बहुत सरल है, लेकिन पूरी तरह से समझना थोड़ा मुश्किल है। कोई कह सकता है कि यह थोड़ा जादुई लगता है। इस तकनीक के कामकाज की सहज समझ हासिल करने की कोशिश करने के लिए हम इस पोस्ट में क्या करेंगे, चरण-दर-चरण, जब हम ऊपर बताए गए स्टॉफ़ल स्निपेट को पार्स करते हैं, तो क्या होता है। तो, आगे की हलचल के बिना, यहां #parse_expr_recursively का पूरा संस्करण दिया गया है :
def parse_expr_recursively(precedence = LOWEST_PRECEDENCE)
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
expr = send(parsing_function)
return if expr.nil? # When expr is nil, it means we have reached a \n or a eof.
# Note that, here, we are checking the NEXT token.
while nxt_not_terminator? && precedence < nxt_precedence
infix_parsing_function = determine_infix_function(nxt)
return expr if infix_parsing_function.nil?
consume
expr = send(infix_parsing_function, expr)
end
expr
end
#parse_expr_recursively अब एक पैरामीटर स्वीकार करता है, वरीयता . यह विधि के दिए गए कॉल में विचार करने के लिए प्राथमिकता "स्तर" का प्रतिनिधित्व करता है। इसके अतिरिक्त, विधि का पहला भाग काफी समान है। फिर - अगर हम इस पहले भाग में एक अभिव्यक्ति बनाने में सक्षम थे - विधि का उपन्यास टुकड़ा आता है। जबकि अगला टोकन टर्मिनेटर नहीं है (यानी, एक लाइन ब्रेक या फ़ाइल का अंत) और प्राथमिकता (प्राथमिकता param) अगले टोकन की प्राथमिकता से कम है, हम संभावित रूप से टोकन स्ट्रीम का उपभोग जारी रखते हैं।
अंदर देखने से पहले जबकि , आइए इसकी दूसरी शर्त के अर्थ के बारे में थोड़ा सोचते हैं (प्राथमिकता expr स्थानीय चर) संभवत:अभी तक बनने वाले नोड का बच्चा है (याद रखें कि हम एक एएसटी बना रहे हैं, एक सार वाक्य रचना पेड़ ) हमारे स्टॉफ़ल स्निपेट को पार्स करने से पहले, आइए एक साधारण अंकगणितीय व्यंजक के विश्लेषण पर विचार करें:2 + 2 . इस व्यंजक को पार्स करते समय, हमारी विधि का पहला भाग एक AST::Number बनाएगा पहले 2 . का प्रतिनिधित्व करने वाला नोड और इसे expr . में स्टोर करें . फिर, हम जबकि . में कदम रखेंगे क्योंकि अगले टोकन की प्राथमिकता (:'+' ) डिफ़ॉल्ट प्राथमिकता से अधिक होगा। इसके बाद हमारे पास AST::Number नामक राशि को संभालने के लिए पार्सिंग विधि होगी। नोड और एक बाइनरी ऑपरेटर का प्रतिनिधित्व करने वाला नोड वापस प्राप्त करना (AST::BinaryOperator ) अंत में, हम ओवरराइट . करेंगे expr . में संग्रहीत मान , पहले 2 . का प्रतिनिधित्व करने वाला नोड 2 + 2 में , इस नए नोड के साथ प्लस ऑपरेटर का प्रतिनिधित्व करता है। ध्यान दें कि अंत में, इस एल्गोरिथम ने हमें नोड्स को पुनर्व्यवस्थित करने . की अनुमति दी; हमने AST::Number . के निर्माण के साथ शुरुआत की नोड और हमारे पेड़ में एक गहरा नोड होने के साथ समाप्त हुआ, AST::BinaryOperator के बच्चों में से एक के रूप में नोड.
फ़ंक्शन परिभाषा को चरण-दर-चरण पार्स करना
अब जबकि हम #parse_expr_recursively की पूरी व्याख्या कर चुके हैं , आइए अपनी सरल कार्य परिभाषा पर वापस आते हैं:
fn double: num
num * 2
end
पार्सर निष्पादन के सरलीकृत विवरण पर एक नज़र डालने का विचार भी, जैसा कि हम इस स्निपेट को पार्स करते हैं, थकाऊ लग सकता है (और, वास्तव में, शायद यह है!), लेकिन मुझे लगता है कि #parse_expr_recursively<दोनों को बेहतर ढंग से समझने के लिए यह बहुत मूल्यवान है। /कोड> और विशिष्ट बिट्स (फ़ंक्शन परिभाषा और उत्पाद ऑपरेटर) की पार्सिंग। सबसे पहले चीज़ें, यहां टोकन प्रकार हैं जिनसे हम निपटेंगे (नीचे @tokens.map(&:type) के लिए आउटपुट है , पार्सर के अंदर लेक्सर द्वारा हमारे द्वारा देखे गए स्निपेट को टोकन करना समाप्त करने के बाद):
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
नीचे दी गई तालिका उस क्रम को दिखाती है जिसमें सबसे महत्वपूर्ण तरीकों को बुलाया जाता है क्योंकि हम ऊपर टोकन को पार्स करते हैं। ध्यान रखें कि यह एक सरलीकरण है, और यदि आप वास्तव में पार्सर निष्पादन के सभी सटीक चरणों को समझना चाहते हैं, तो मैं रूबी डीबगर का उपयोग करने की सलाह देता हूं, जैसे कि बायबग, और प्रोग्राम के निष्पादन के रूप में अग्रिम पंक्ति-दर-पंक्ति। <ब्लॉकक्वॉट>
माइक्रोस्कोप के अंतर्गत हमारा पार्सर
एक परीक्षण है जो इस सटीक स्निपेट का उपयोग करता है जिसे हम खोज रहे हैं, जो स्टॉफ़ल के स्रोत में उपलब्ध है। आप इसे spec/lib/stoffle/parser_spec.rb के अंदर पा सकते हैं; यह परीक्षण है जो complex_program_ok_2.sfe . नामक स्निपेट का उपयोग करता है ।
पार्सर निष्पादन को चरण-दर-चरण एक्सप्लोर करने के लिए, आप स्रोत को संपादित कर सकते हैं और byebug में कॉल जोड़ सकते हैं Parser#parse . की शुरुआत में , RSpec के साथ केवल उपरोक्त परीक्षण चलाएँ, और फिर Byebug के चरण . का उपयोग करें प्रोग्राम को एक बार में एक लाइन आगे बढ़ाने का आदेश।
बायबग कैसे काम करता है और सभी उपलब्ध कमांड के बारे में अधिक जानकारी के लिए GitHub पर प्रोजेक्ट की README फ़ाइल पर जाकर देखें।
| विधि कहा जाता है | वर्तमान टोकन | अगला टोकन | उल्लेखनीय चर / कॉल परिणाम | अवलोकन |
|---|---|---|---|---|
| पार्स | शून्य | :fn | ||
| parse_expr_recursively | :fn | :पहचानकर्ता | प्राथमिकता =0, पार्सिंग_फ़ंक्शन =:parse_fn | |
| parse_function_definition | :fn | :पहचानकर्ता | parse_fn, parse_function_definition का एक उपनाम है | |
| parse_function_params | :पहचानकर्ता | :":" | ||
| parse_block | :"\n" | :पहचानकर्ता | ||
| parse_expr_recursively | :पहचानकर्ता | :* | पूर्वता =0, पार्सिंग_फंक्शन =:parse_identifier, nxt_precedence() रिटर्न 6, infix_parsing_function =:parse_binary_operator | |
| parse_identifier | :पहचानकर्ता | :* | ||
| parse_binary_operator | :* | :संख्या | op_precedence =6 | |
| parse_expr_recursively | :संख्या | :"\n" | प्राथमिकता =6, पार्सिंग_फंक्शन =:parse_number, nxt_precedence() रिटर्न 0 | |
| parse_number | :संख्या | :"\n" |
अब जबकि हमारे पास एक सामान्य धारणा है कि किन विधियों को कहा जाता है, साथ ही अनुक्रम, आइए कुछ पार्सिंग विधियों का अध्ययन करें जिन्हें हमने अभी तक अधिक विस्तार से नहीं देखा है।
#parse_function_definition विधि
विधि #parse_function_definition कॉल किया गया था जब वर्तमान टोकन :fn . था और अगला था :identifier :
def parse_function_definition
return unless consume_if_nxt_is(build_token(:identifier))
fn = AST::FunctionDefinition.new(AST::Identifier.new(current.lexeme))
if nxt.type != :"\n" && nxt.type != :':'
unexpected_token_error
return
end
fn.params = parse_function_params if nxt.type == :':'
return unless consume_if_nxt_is(build_token(:"\n", "\n"))
fn.body = parse_block
fn
end
#consume_if_nxt_is - जैसा कि आप अनुमान लगा रहे होंगे - यदि अगला टोकन किसी दिए गए प्रकार का है तो हमारे पॉइंटर को आगे बढ़ाता है। अन्यथा, यह @errors . में एक त्रुटि जोड़ता है . #consume_if_nxt_is बहुत उपयोगी है - और कई पार्सर विधियों में उपयोग किया जाता है - जब हम यह निर्धारित करने के लिए टोकन की संरचना की जांच करना चाहते हैं कि हमारे पास वैध वाक्यविन्यास है या नहीं। ऐसा करने के बाद, वर्तमान टोकन :identifier . प्रकार का है (हम 'double' . को संभाल रहे हैं , फ़ंक्शन का नाम), और हम एक AST::Identifier . बनाते हैं और फ़ंक्शन परिभाषा (AST::FunctionDefinition) का प्रतिनिधित्व करने के लिए नोड बनाने के लिए इसे कंस्ट्रक्टर को पास करें ) हम इसे यहां विस्तार से नहीं देखने जा रहे हैं, लेकिन मूल रूप से, एक AST::FunctionDefinition नोड फ़ंक्शन नाम, संभावित रूप से पैरामीटर की एक सरणी और फ़ंक्शन बॉडी की अपेक्षा करता है।
#parse_function_definition में अगला चरण यह सत्यापित करना है कि पहचानकर्ता के बाद अगला टोकन एक अभिव्यक्ति टर्मिनेटर है (यानी, बिना पैरा के एक फ़ंक्शन) या एक कोलन (यानी, एक या एकाधिक पैरामीटर वाला फ़ंक्शन)। यदि हमारे पास पैरामीटर हैं, जैसा कि डबल . के मामले में है फ़ंक्शन जिसे हम परिभाषित कर रहे हैं, हम #parse_function_params . कहते हैं उन्हें पार्स करने के लिए। हम इस विधि को एक पल में देखेंगे, लेकिन आइए पहले जारी रखें और #parse_function_definition के अपने अन्वेषण को पूरा करें। ।
अंतिम चरण यह सत्यापित करने के लिए एक और सिंटैक्स जांच करना है कि फ़ंक्शन नाम + पैरा के बाद एक टर्मिनेटर है और फिर, #parse_block पर कॉल करके फ़ंक्शन बॉडी को पार्स करने के लिए आगे बढ़ें। . अंत में, हम fn . लौटाते हैं , जो हमारी पूरी तरह से निर्मित AST::FunctionDefinition . रखता है उदाहरण, एक फ़ंक्शन नाम, पैरामीटर और एक बॉडी के साथ पूर्ण।
फ़ंक्शन पैरामीटर पार्सिंग के नट और बोल्ट
पिछले भाग में, हमने देखा कि #parse_function_params #parse_function_definition . के अंदर कॉल किया जाता है . यदि हम अपने पार्सर के निष्पादन प्रवाह और स्थिति को सारांशित करते हुए अपनी तालिका पर वापस जाते हैं, तो हम देख सकते हैं कि जब #parse_function_params चलना शुरू होता है, वर्तमान टोकन प्रकार का है :identifier , और अगला है :":" (अर्थात, हमने अभी-अभी फंक्शन नाम को पार्स करना समाप्त किया है)। इस सब को ध्यान में रखते हुए, आइए कुछ और कोड देखें:
def parse_function_params
consume
return unless consume_if_nxt_is(build_token(:identifier))
identifiers = []
identifiers << AST::Identifier.new(current.lexeme)
while nxt.type == :','
consume
return unless consume_if_nxt_is(build_token(:identifier))
identifiers << AST::Identifier.new(current.lexeme)
end
identifiers
end
इससे पहले कि मैं इस पद्धति के प्रत्येक भाग की व्याख्या करूँ, आइए उन टोकनों का पुनर्कथन करें जिन्हें हमें संसाधित करना है और हम इस कार्य में कहाँ हैं:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# here ▲
#parse_function_params का पहला भाग सीधा है। यदि हमारे पास वैध सिंटैक्स है (: . के बाद कम से कम एक पहचानकर्ता ), हम अपने पॉइंटर को दो स्थितियों से आगे बढ़ाते हैं:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
अब, हम पार्स किए जाने वाले पहले पैरामीटर पर बैठे हैं (एक प्रकार का टोकन :identifier ) जैसा अपेक्षित था, हम एक AST::Identifier बनाते हैं और इसे संभावित रूप से पार्स किए जाने वाले कई अन्य पैरामीटर की एक सरणी में धक्का दें। अगले बिट में #parse_function_params , हम तब तक पैरा को पार्स करना जारी रखते हैं जब तक कि पैरामीटर सेपरेटर (यानी, :',' प्रकार के टोकन हैं) ) हम स्थानीय var पहचानकर्ता . को वापस करके विधि को समाप्त करते हैं , एक सरणी, संभावित रूप से, एकाधिक AST::Identifier . के साथ नोड्स, प्रत्येक एक परम का प्रतिनिधित्व करते हैं। हालांकि, हमारे मामले में, इस सरणी में केवल एक तत्व है।
फ़ंक्शन बॉडी के बारे में क्या?
आइए अब एक फ़ंक्शन परिभाषा को पार्स करने के अंतिम भाग में गहराई से जाएं:इसके शरीर से निपटना। जब #parse_block कहा जाता है, हम टर्मिनेटर पर बैठे हैं जिसने फ़ंक्शन मापदंडों की सूची के अंत को चिह्नित किया है:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
And, here's the implementation of #parse_block :
def parse_block
consume
block = AST::Block.new
while current.type != :end && current.type != :eof && nxt.type != :else
expr = parse_expr_recursively
block << expr unless expr.nil?
consume
end
unexpected_token_error(build_token(:eof)) if current.type == :eof
block
end
AST::Block is the AST node for representing, well, a block of code. In other words, AST::Block just holds a list of expressions, in a very similar fashion as the root node of our program, an AST::Program node (as we saw at the beginning of this post). To parse the block (i.e., the function body), we continue advancing through unprocessed tokens until we encounter a token that marks the end of the block.
To parse the expressions that compose the block, we use our already-known #parse_expr_recursively . We will step into this method call in just a moment; this is the point in which we will start parsing the product operation happening inside our double function. Following this closely will allow us to understand the use of precedence values inside #parse_expr_recursively and how an infix operator (the * in our case) gets dealt with. Before we do that, however, let's finish our exploration of #parse_block ।
Before returning an AST node representing our block, we check whether the current token is of type :eof . If this is the case, we have a syntax error since Stoffle requires a block to end with the end keyword. To wrap up the explanation of #parse_block , I should mention something you have probably noticed; one of the conditions of our loop verifies whether the next token is of type :else . This happens because #parse_block is shared by other parsing methods, including the methods responsible for parsing conditionals and loops. Pretty neat, huh?!
Parsing Infix Operators
The name may sound a bit fancy, but infix operators are, basically, those we are very used to seeing in arithmetic, plus some others that we may be more familiar with by being software developers:
module Stoffle
class Parser
# ...
BINARY_OPERATORS = [:'+', :'-', :'*', :'/', :'==', :'!=', :'>', :'<', :'>=', :'<='].freeze
LOGICAL_OPERATORS = [:or, :and].freeze
# ...
end
end
They are expected to be used infixed when the infix notation is used, as is the case with Stoffle, which means they should appear in the middle of their two operands (e.g., as * appears in num * 2 in our double function). Something worth mentioning is that although the infix notation is pretty popular, there are other ways of positioning operators in relation to their operands. If you are curious, research a little bit about "Polish notation" and "reverse Polish notation" methods.
To finish parsing our double function, we have to deal with the * operator:
fn double: num
num * 2
end
In the previous section, we mentioned that parsing the expression that composes the body of double starts when #parse_expr_recursively is called within #parse_block . When that happens, here's our position in @tokens :
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
And, to refresh our memory, here's the code for #parse_expr_recursively again:
def parse_expr_recursively(precedence = LOWEST_PRECEDENCE)
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
expr = send(parsing_function)
return if expr.nil? # When expr is nil, it means we have reached a \n or a eof.
# Note that here, we are checking the NEXT token.
while nxt_not_terminator? && precedence < nxt_precedence
infix_parsing_function = determine_infix_function(nxt)
return expr if infix_parsing_function.nil?
consume
expr = send(infix_parsing_function, expr)
end
expr
end
In the first part of the method, we will use the same #parse_identifier method we used to parse the num variable. Then, for the first time, the conditions of the while loop will evaluate to true; the next token is not a terminator, and the precedence of the next token is greater than the precedence of this current execution of parse_expr_recursively (precedence is the default, 0, while nxt_precedence returns 6 since the next token is of type :'*' ) This indicates that the node we already built (an AST::Identifier representing num ) will probably be deeper in our AST (i.e., it will be the child of a node yet to be built). We enter the loop and call #determine_infix_function , passing to it the next token (the * ):
def determine_infix_function(token = current)
if (BINARY_OPERATORS + LOGICAL_OPERATORS).include?(token.type)
:parse_binary_operator
elsif token.type == :'('
:parse_function_call
end
end
Since * is a binary operator, running #determine_infix_function will result in :parse_binary_operator . Back in #parse_expr_recursively , we will advance our tokens pointer by one position and then call #parse_binary_operator , passing along the value of expr (the AST::Identifier representing num ):
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
#▲
def parse_binary_operator(left)
op = AST::BinaryOperator.new(current.type, left)
op_precedence = current_precedence
consume
op.right = parse_expr_recursively(op_precedence)
op
end
class Stoffle::AST::BinaryOperator < Stoffle::AST::Expression
attr_accessor :operator, :left, :right
def initialize(operator, left = nil, right = nil)
@operator = operator
@left = left
@right = right
end
def ==(other)
operator == other&.operator && children == other&.children
end
def children
[left, right]
end
end
At #parse_binary_operator , we create an AST::BinaryOperator (its implementation is shown above if you are curious) to represent * , setting its left operand to the identifier (num ) we received from #parse_expr_recursively . Then, we save the precedence value of * at the local var op_precedence and advance our token pointer. To finish building our node representing * , we call #parse_expr_recursively again! We need to proceed in this fashion because the right-hand side of our operator will not always be a single number or identifier; it can be a more complex expression, such as something like num * (2 + 2) ।
One thing of utmost importance that happens here at #parse_binary_operator is the way in which we call #parse_expr_recursively back again. We call it passing 6 as a precedence value (the precedence of * , stored at op_precedence ) Here we observe an important aspect of our parsing algorithm, which was mentioned previously. By passing a relatively high precedence value, it seems like * is pulling the next token as its operand. Imagine we were parsing an expression like num * 2 + 1; in this case, the precedence value of * passed in to this next call to #parse_expr_recursively would guarantee that the 2 would end up being the right-hand side of * and not an operand of + , which has a lower precedence value of 5 ।
After #parse_expr_recursively returns an AST::Number node, we set it as the right-hand size of * and, finally, return our complete AST::BinaryOperator node. At this point, we have, basically, finished parsing our Stoffle program. We still have to parse some terminator tokens, but this is straightforward and not very interesting. At the end, we will have an AST::Program instance at @ast with expressions that could be visually represented as the tree we saw at the beginning of this post and in the introduction to the second section of the post:
Wrapping Up
In this post, we covered the principal aspects of Stoffle's parser. If you understand the bits we explored here, you shouldn't have much trouble understanding other parser methods we were not able to cover, such as parsing conditionals and loops. I encourage you to explore the source code of the parser by yourself and tweak the implementation if you are feeling more adventurous! The implementation is accompanied by a comprehensive test suite, so don't be afraid to try things out and mess up with the parser.
In subsequent posts in this series, we will finally breathe life into our little monster by implementing the last bit we are missing:the tree-walk interpreter. I can't wait to be there with you as we run our first Stoffle program!