Gephi और Sigma.js के साथ एक नेटवर्क विज़ुअलाइज़ेशन ट्यूटोरियल
आज हम जो बना रहे हैं उसका पूर्वावलोकन यहां दिया गया है:प्रोग्रामिंग भाषाएं ग्राफ को प्रभावित करती हैं। अतीत और वर्तमान में 250 से अधिक प्रोग्रामिंग भाषाओं के बीच "डिज़ाइन प्रभाव" संबंधों का पता लगाने के लिए लिंक देखें!
आपकी बारी!
आज की हाइपर-कनेक्टेड दुनिया में, नेटवर्क आधुनिक जीवन का एक सर्वव्यापी पहलू है।
मेरे दिन की अब तक की शुरुआत लें — मैंने लंदन के परिवहन नेटवर्क . का उपयोग किया है शहर में यात्रा करने के लिए। फिर मैं एक शाखा . में गया मेरी पसंदीदा कॉफ़ी शॉप में से और अपने वाई-फ़ाई नेटवर्क . से कनेक्ट करने के लिए मेरे Chromebook का उपयोग किया . इसके बाद, मैंने विभिन्न सोशल नेटवर्किंग . में लॉग इन किया जिन साइटों पर मैं अक्सर आता हूं।
यह कोई रहस्य नहीं है कि पिछले कुछ दशकों की कुछ सबसे प्रभावशाली कंपनियों ने अपनी सफलता का श्रेय नेटवर्क की ताकत को दिया है।
फेसबुक, ट्विटर, इंस्टाग्राम, लिंक्डइन और अन्य सोशल मीडिया प्लेटफॉर्म सोशल नेटवर्क की छोटी दुनिया की संपत्तियों पर भरोसा करते हैं। इससे वे अपने उपयोगकर्ताओं को एक दूसरे (और विज्ञापनदाताओं) से प्रभावी ढंग से जोड़ सकते हैं।
Google अपनी वर्तमान सफलता का अधिकांश भाग खोज इंजन बाजार पर उनके प्रारंभिक प्रभुत्व के कारण देता है - जो उनके पेज रैंक नेटवर्क एल्गोरिथम की सहायता से प्रासंगिक परिणाम लौटाने की उनकी क्षमता के माध्यम से आंशिक रूप से सक्षम है।
अमेज़ॅन का कुशल वितरण नेटवर्क उन्हें कुछ प्रमुख शहरों में उसी दिन डिलीवरी की पेशकश करने की अनुमति देता है।
आर्टिफिशियल इंटेलिजेंस और मशीन लर्निंग जैसे क्षेत्रों में भी नेटवर्क बहुत महत्वपूर्ण हैं। तंत्रिका नेटवर्क अनुसंधान का एक बहुत सक्रिय क्षेत्र है। कई फीचर डिटेक्शन एल्गोरिदम, जो कंप्यूटर विज़न में आवश्यक हैं, छवियों के विभिन्न भागों को मॉडल करने के लिए नेटवर्क का उपयोग करने पर बहुत अधिक निर्भर करते हैं।
नेटवर्क मॉडल के संदर्भ में वैज्ञानिक घटनाओं की एक विस्तृत श्रृंखला को भी समझा जा सकता है। इसमें क्वांटम यांत्रिकी, जैव रासायनिक रास्ते और पारिस्थितिक और सामाजिक-आर्थिक प्रणालियाँ शामिल हैं।
उनके निर्विवाद महत्व को देखते हुए, हम नेटवर्क और उनकी संपत्तियों को बेहतर ढंग से कैसे समझ सकते हैं?
नेटवर्क के गणितीय अध्ययन को "ग्राफ सिद्धांत" के रूप में जाना जाता है, और यह गणित की अधिक सुलभ शाखाओं में से एक है। इस लेख का उद्देश्य थोड़ा पूर्व ज्ञान या अनुभव मानते हुए एक परिचय प्रदान करना है।
हम एक नेटवर्क विज़ुअलाइज़ेशन को एक साथ रखने के लिए पायथन 3.x और गेफी नामक कुछ भयानक ओपन-सोर्स सॉफ़्टवेयर का उपयोग करेंगे कि कैसे अतीत और वर्तमान प्रोग्रामिंग भाषाओं की एक श्रृंखला प्रभाव से जुड़ी हुई है।
लेकिन पहले...
नेटवर्क वास्तव में क्या है?
ऊपर वर्णित उदाहरण हमें कुछ सुराग देते हैं। परिवहन नेटवर्क गंतव्यों . से बने होते हैं मार्गों . द्वारा जुड़ा हुआ है . सामाजिक नेटवर्क व्यक्तियों . से बने होते हैं , उनके रिश्तों . के माध्यम से जुड़े हुए हैं एक दूसरे से। Google के खोज इंजन एल्गोरिदम विभिन्न वेबपृष्ठों . के "रैंक" का मूल्यांकन करते हैं किन पृष्ठों को देखकर लिंक दूसरों के लिए।
अधिक सामान्यतः, नेटवर्क कोई भी प्रणाली है जिसे नोड्स . के रूप में वर्णित किया जा सकता है और किनारों , या बोलचाल की भाषा में, "बिंदु और रेखा"।
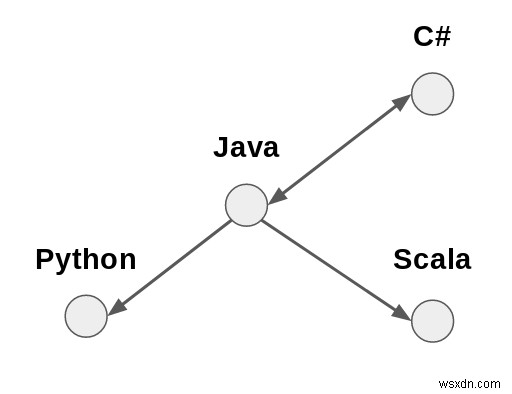
कुछ प्रणालियों को इस तरह से आसानी से सारगर्भित किया जाता है। सामाजिक नेटवर्क शायद सबसे स्पष्ट उदाहरण हैं। कंप्यूटर फाइल सिस्टम एक और हैं - फ़ोल्डर और फाइलें उनके "पैरेंट" और "चाइल्ड" संबंधों से जुड़ी हुई हैं।
लेकिन नेटवर्क की वास्तविक शक्ति इस तथ्य से आती है कि नेटवर्क के संदर्भ में कई, कई प्रणालियों को सारगर्भित और मॉडल किया जा सकता है, भले ही यह स्पष्ट न हो कि कैसे।
नेटवर्क का प्रतिनिधित्व करना
गणितीय रूप से नेटवर्क का विश्लेषण और वर्णन करने के लिए हमें पेन-एंड-पेपर स्केच से थोड़ा आगे जाने की आवश्यकता है। हम बिंदुओं और रेखाओं की तस्वीरों को उन संख्याओं में कैसे बदल सकते हैं जिन्हें हम क्रंच कर सकते हैं?
एक समाधान आसन्नता मैट्रिक्स . तैयार करना है हमारे नेटवर्क का प्रतिनिधित्व करने के लिए।
मैट्रिसेस उन अवधारणाओं में से एक हैं जो आपको थोड़ा डराने वाली लग सकती हैं यदि आप उनसे परिचित नहीं हैं, लेकिन डरें नहीं। उन्हें संख्याओं के ग्रिड के रूप में सोचें जिनका उपयोग एक साथ कई गणना करने के लिए किया जा सकता है। यहां एक उदाहरण नीचे दिया गया है:
Python Java Scala C#
Python 0 1 0 0
Java 0 0 0 1
Scala 0 1 0 0
C# 0 1 0 0इस मैट्रिक्स में, प्रत्येक पंक्ति और स्तंभ का प्रतिच्छेदन या तो 0 या 1 है, जो इस बात पर निर्भर करता है कि संबंधित भाषाएं जुड़ी हुई हैं या नहीं। आप इसे ऊपर दिए गए उदाहरण से देख सकते हैं!
अधिकांश उद्देश्यों के लिए, आसन्न मैट्रिक्स गणितीय रूप से नेटवर्क का प्रतिनिधित्व करने का एक अच्छा तरीका है। हालांकि, कम्प्यूटेशनल दृष्टिकोण से, यह कभी-कभी थोड़ा बोझिल हो सकता है।
उदाहरण के लिए, नोड्स की अपेक्षाकृत मामूली संख्या (मान लीजिए 1000) के साथ, मैट्रिक्स में बहुत अधिक संख्या में तत्व होंगे (जैसे, 1000² =1,000,000)।
कई वास्तविक-विश्व प्रणालियाँ विरल नेटवर्क उत्पन्न करती हैं . इन नेटवर्कों में, अधिकांश नोड्स अन्य सभी के केवल एक छोटे अनुपात से जुड़ते हैं।
यदि हम कंप्यूटर मेमोरी में एक आसन्न मैट्रिक्स के रूप में एक 1000-नोड विरल नेटवर्क का प्रतिनिधित्व करते हैं, तो हमारे पास रैम में संग्रहीत डेटा के 1,000,000 बाइट्स होंगे। अधिकांश शून्य होंगे। इसके बारे में जाने का एक अधिक कुशल तरीका होना चाहिए।
एक वैकल्पिक तरीका किनारे वाली सूचियों . के साथ काम करना है बजाय। ये वही हैं जो वे कहते हैं कि वे हैं। वे केवल एक सूची हैं कि कौन से नोड जोड़े एक दूसरे से जुड़ते हैं।
उदाहरण के लिए, उपरोक्त प्रोग्रामिंग भाषा नेटवर्क को इस प्रकार दर्शाया जा सकता है:
Java, Python
Java, Scala
Java, C#
C#, Javaबड़े नेटवर्क के लिए, यह उनका प्रतिनिधित्व करने का एक अधिक कम्प्यूटेशनल रूप से कुशल साधन है। किनारे सूची (और इसके विपरीत) से आसन्नता मैट्रिक्स उत्पन्न करना निश्चित रूप से संभव है। ऐसा नहीं है कि हमें एक या दूसरे को चुनना है।
नेटवर्क का प्रतिनिधित्व करने का एक अन्य माध्यम आसन्न सूचियां हैं। यह प्रत्येक नोड को सूचीबद्ध करता है जिसके बाद नोड्स इसे लिंक करते हैं। उदाहरण के लिए:
Java: Python, Scala, C#
C#: Javaडेटा एकत्र करना, कनेक्शन बनाना
कोई भी नेटवर्क मॉडल और विज़ुअलाइज़ेशन केवल उतना ही अच्छा होगा जितना कि इसे बनाने के लिए उपयोग किया गया डेटा। इसका मतलब है, साथ ही यह सुनिश्चित करने के साथ कि डेटा सटीक और पूर्ण दोनों है, हमें नोड्स के बीच किनारों का अनुमान लगाने के साधन को उचित ठहराने की भी आवश्यकता है।
कई मायनों में, यह द . है महत्वपूर्ण कदम। नेटवर्क के बारे में किया गया कोई भी बाद का विश्लेषण और निष्कर्ष "लिंकेज मानदंड" को सही ठहराने में सक्षम होने पर निर्भर करता है।
उदाहरण के लिए, सामाजिक नेटवर्क विश्लेषण में, आप लोगों को इस आधार पर लिंक कर सकते हैं कि वे सोशल मीडिया पर एक दूसरे का अनुसरण करते हैं या नहीं। आणविक जीव विज्ञान में, आप जीन को उनकी सह-अभिव्यक्ति के आधार पर जोड़ सकते हैं।
अक्सर, नोड्स को जोड़ने के लिए उपयोग की जाने वाली विधि वजन . की अनुमति देगी किनारों को सौंपा जाना, "ताकत" का माप देना।
उदाहरण के लिए, ऑनलाइन रिटेल के संदर्भ में, आप उत्पादों को इस आधार पर लिंक कर सकते हैं कि वे कितनी बार एक साथ खरीदे जाते हैं। जिन उत्पादों को अक्सर एक साथ खरीदा जाता है, वे उच्च भारित बढ़त . से जुड़े होंगे उन उत्पादों की तुलना में जिन्हें केवल कभी-कभी एक साथ खरीदा जाता है। उत्पाद जो संयोग से अपेक्षा से अधिक बार एक साथ खरीदे जाते हैं, वे बिल्कुल भी लिंक नहीं होंगे।
जैसा कि आप कल्पना कर सकते हैं, नोड्स को एक दूसरे से जोड़ने के तरीके उतने ही परिष्कृत हो सकते हैं जितने आप चाहते हैं।
हालाँकि, इस ट्यूटोरियल के लिए हम प्रोग्रामिंग भाषाओं को जोड़ने के एक सरल माध्यम का उपयोग करेंगे। हम विकिपीडिया की सटीकता पर भरोसा करेंगे।
हमारे उद्देश्यों के लिए, यह ठीक होना चाहिए। विकिपीडिया की सफलता इस बात का प्रमाण है कि वह कुछ सही कर रहा होगा। ओपन-सोर्स, सहयोगी पद्धति जिसके द्वारा लेख लिखे जाते हैं, कुछ हद तक निष्पक्षता सुनिश्चित करनी चाहिए।
साथ ही, इसकी अपेक्षाकृत सुसंगत पृष्ठ संरचना इसे वेब-स्क्रैपिंग तकनीकों को आज़माने के लिए एक सुविधाजनक खेल का मैदान बनाती है।
एक और बोनस व्यापक, अच्छी तरह से प्रलेखित विकिपीडिया एपीआई है, जो सूचना पुनर्प्राप्ति को अभी भी आसान बनाता है। आइए शुरू करें।
चरण 1 — Gephi इंस्टॉल करना
गेफी लिनक्स, मैक और विंडोज पर उपलब्ध है। आप इसे यहां डाउनलोड कर सकते हैं।
इस परियोजना के लिए, मैं लुबंटू का उपयोग कर रहा था। यदि आप उबंटू/डेबियन पर हैं, तो आप नीचे दिए गए चरणों का पालन करके गेफी को चालू और चालू कर सकते हैं। अन्यथा, स्थापना प्रक्रिया बहुत कुछ वैसी ही होगी जैसी आप परिचित हैं।
अपने सिस्टम के लिए Gephi का नवीनतम संस्करण डाउनलोड करें (लिखने के समय यह v.0.9.1 था)। जब यह तैयार हो जाए, तो आपको फ़ाइलें निकालने की आवश्यकता होगी।
cd Downloads
tar -xvzf gephi-0.9.1-linux.tar.gz
cd gephi-0.9.1/bin./gephiआपको जावा जेआरई के अपने संस्करण की जांच करने की आवश्यकता हो सकती है। Gephi को हाल के संस्करण की आवश्यकता है। लुबंटू के अपने अपेक्षाकृत नए इंस्टॉलेशन पर, मैंने बस डिफ़ॉल्ट-जेआर स्थापित किया, और सब कुछ वहीं से काम किया।
apt install default-jre
./gephiआगे बढ़ने के लिए तैयार होने से पहले एक और कदम है। ग्राफ़ को वेब पर निर्यात करने के लिए, आप Gephi के लिए Sigma.js प्लगइन का उपयोग कर सकते हैं।
Gephi के मेनू बार से, "टूल्स" विकल्प चुनें, और "प्लगइन्स" चुनें।
"उपलब्ध प्लगइन्स" टैब पर क्लिक करें और "सिग्माएक्सपोर्टर" चुनें (मैंने JSON एक्सपोर्टर भी स्थापित किया है, क्योंकि यह एक और उपयोगी प्लगइन है)।
"इंस्टॉल करें" बटन को हिट करें और आप प्रक्रिया के माध्यम से चले जाएंगे। काम पूरा हो जाने पर आपको Gephi को फिर से शुरू करना होगा।
चरण 2 — पायथन लिपि लिखना
यह ट्यूटोरियल जीवन को आसान बनाने के लिए Python 3.x, और कुछ मॉड्यूल का उपयोग करेगा। पाइप मॉड्यूल इंस्टॉलर का उपयोग करके, निम्न कमांड चलाएँ:
pip3 install wikipedia
अब, एक नई निर्देशिका में, script.py . जैसी कुछ नाम की फ़ाइल बनाएं , और इसे अपने पसंदीदा कोड संपादक/आईडीई में खोलें। नीचे मुख्य तर्क की रूपरेखा दी गई है:
- सबसे पहले, आपको शामिल करने के लिए प्रोग्रामिंग भाषाओं की एक सूची की आवश्यकता होगी।
- अगला, उस सूची को देखें और संबंधित विकिपीडिया लेख के HTML को पुनः प्राप्त करें।
- इसमें से उन प्रोग्रामिंग भाषाओं की सूची निकालें, जिन पर प्रत्येक भाषा का प्रभाव पड़ा है। यह एक रफ एंड रेडी लिंकेज मानदंड होगा।
- जब आप इसमें हों, तो प्रत्येक भाषा के बारे में कुछ मेटाडेटा प्राप्त करना अच्छा होगा।
- आखिरकार, आप अपने द्वारा एकत्र किए गए सभी डेटा को एक .csv फ़ाइल में लिखना चाहेंगे
पूरी स्क्रिप्ट इस सार में मिल सकती है।
कुछ मॉड्यूल आयात करें
script.py . में , कुछ मॉड्यूल आयात करके शुरू करें जो चीजों को आसान बना देगा:
import csv
import wikipedia
import urllib.request
from bs4 import BeautifulSoup as BS
import reठीक - शामिल करने के लिए नोड्स की सूची बनाकर शुरू करें। यह वह जगह है जहाँ विकिपीडिया मॉड्यूल काम आता है। यह विकिपीडिया एपीआई तक पहुँचने को बेहद आसान बनाता है।
निम्नलिखित कोड जोड़ें:
pageTitle = "List of programming languages"
nodes = list(wikipedia.page(pageTitle).links)
print(nodes)यदि आप इस स्क्रिप्ट को सहेजते और चलाते हैं, तो आप देखेंगे कि यह "प्रोग्रामिंग भाषाओं की सूची" विकिपीडिया लेख के सभी लिंक को प्रिंट करता है। बढ़िया!
हालांकि, किसी भी स्वचालित रूप से एकत्र किए गए डेटा का मैन्युअल रूप से निरीक्षण करना हमेशा समझदारी भरा होता है। एक त्वरित नज़र से पता चलेगा कि, कई वास्तविक प्रोग्रामिंग भाषाओं के साथ, स्क्रिप्ट ने कुछ अतिरिक्त लिंक भी लिए हैं।
उदाहरण के लिए, आपको वहां "मार्कअप भाषाओं की सूची", "प्रोग्रामिंग भाषाओं की तुलना" और अन्य दिखाई दे सकते हैं।
हालांकि Gephi आपको उन नोड्स को हटाने देता है जिन्हें आप शामिल नहीं करना चाहते हैं, लेकिन आगे बढ़ने से पहले डेटा को "साफ़" करने में कोई दिक्कत नहीं होगी। यदि कुछ भी हो, तो इससे बाद में समय की बचत होगी।
removeList = [
"List of",
"Lists of",
"Timeline",
"Comparison of",
"History of",
"Esoteric programming language"
]
nodes = [i for i in nodes if not any(r in i for r in removeList)]ये लाइनें डेटा से हटाए जाने वाले सबस्ट्रिंग की सूची को परिभाषित करती हैं। स्क्रिप्ट तब डेटा के माध्यम से जाती है, किसी भी अवांछित सबस्ट्रिंग वाले किसी भी तत्व को हटा देती है।
पायथन में, इसके लिए कोड की केवल एक पंक्ति की आवश्यकता होती है!
कुछ सहायक कार्य
अब आप एक किनारे की सूची बनाने के लिए विकिपीडिया को स्क्रैप करना शुरू कर सकते हैं (और कोई मेटाडेटा एकत्र कर सकते हैं)। इसे आसान बनाने के लिए, पहले कुछ कार्यों को परिभाषित करें।
HTML हथियाना
पहला फ़ंक्शन प्रत्येक भाषा के विकिपीडिया पृष्ठ के लिए HTML को पकड़ने के लिए सुंदर सूप मॉड्यूल का उपयोग करता है।
base = "https://en.wikipedia.org/wiki/"
def getSoup(n):
try:
with urllib.request.urlopen(base+n) as response:
soup = BS(response.read(),'html.parser')
table = soup.find_all("table",class_="infobox vevent")[0] return table
except:
pass
यह फ़ंक्शन “https://en.wikipedia.org/wiki/” + “programming language” पर पेज के लिए HTML को होल्ड करने के लिए urllib.request मॉड्यूल का उपयोग करता है ।
इसके बाद इसे BeautifulSoup में भेज दिया जाता है, जो HTML को एक ऐसी वस्तु में पढ़ता है और पार्स करता है जिसका उपयोग हम जानकारी खोजने के लिए कर सकते हैं।
इसके बाद, find_all() . का उपयोग करें जिस HTML तत्व में आप रुचि रखते हैं उसे निकालने का तरीका।
यहां, यह प्रत्येक प्रोग्रामिंग भाषा लेख के शीर्ष पर सारांश तालिका होगी। इन्हें कैसे पहचाना जा सकता है?
प्रोग्रामिंग भाषा के किसी एक पेज पर जाना सबसे आसान तरीका है। यहां, आप रुचि के तत्वों का निरीक्षण करने के लिए बस ब्राउज़र के डेवलपर टूल का उपयोग कर सकते हैं।
सारांश तालिका में HTML टैग है <tab le> और CSS classes "in फोबॉक्स" and "v इवेंट", ताकि आप एचटीएमएल में टेबल की पहचान करने के लिए इनका इस्तेमाल कर सकें।
इसे तर्कों के साथ निर्दिष्ट करें:
"table"औरclass_="infobox vevent"
find_all() मानदंडों से मेल खाने वाले सभी तत्वों की एक सूची देता है। वास्तव में उस तत्व को निर्दिष्ट करने के लिए जिसमें आप रुचि रखते हैं, अनुक्रमणिका जोड़ें [0] . यदि फ़ंक्शन सफल होता है, तो यह table लौटाता है वस्तु। अन्यथा, यह None returns लौटाता है ।
किसी भी स्वचालित डेटा संग्रह प्रक्रिया के साथ, अपवादों को अच्छी तरह से संभालना हमेशा महत्वपूर्ण होता है। यदि नहीं, तो सबसे अच्छी स्थिति में स्क्रिप्ट क्रैश हो जाती है और आपको फिर से शुरू करने की आवश्यकता होगी।
सबसे खराब स्थिति में, आप विसंगतियों और त्रुटियों से भरे डेटा सेट के साथ समाप्त होंगे। यह डाउन द लाइन के साथ काम करने के लिए एक बुरा सपना बना देगा।
मेटाडेटा पुनर्प्राप्त करें
अगला फ़ंक्शन table . का उपयोग करता है कुछ मेटाडेटा देखने के लिए ऑब्जेक्ट। यहां, यह उस वर्ष के लिए तालिका खोजता है जिस वर्ष पहली बार भाषा दिखाई दी थी।
def getYear(t):
try:
t = t.get_text()
year = t[t.find("appear"):t.find("appear")+30]
year = re.match(r'.*([1-3][0-9]{3})',year).group(1)
return int(year)
except:
return "Could not determine"
यह छोटा फ़ंक्शन table लेता है ऑब्जेक्ट को इसके तर्क के रूप में, और BeautifulSoup के get_text() . का उपयोग करता है एक स्ट्रिंग बनाने के लिए कार्य करता है।
अगला कदम year . नामक सबस्ट्रिंग बनाना है . "appear" . शब्द की पहली उपस्थिति के बाद इसमें 30 वर्ण लगते हैं . इस स्ट्रिंग में वह वर्ष होना चाहिए जिस वर्ष भाषा पहली बार दिखाई दी थी।
केवल वर्ष निकालने के लिए, रेगुलर एक्सप्रेशन . का उपयोग करें (re . के सौजन्य से मॉड्यूल) किसी भी वर्ण से मेल खाने के लिए जो 1 और 3 के बीच के अंक से शुरू होता है, और उसके बाद तीन अंक होते हैं।
re.match(r'.*([1-3][0-9]{3})',year)
यदि यह सफल होता है, तो फ़ंक्शन year लौटाता है एक पूर्णांक के रूप में। अन्यथा, यह एक उदास दिखने वाला "निर्धारित नहीं कर सका" लौटाता है। आप आगे मेटाडेटा - जैसे प्रतिमान, डिज़ाइनर या टाइपिंग अनुशासन को परिमार्जन करना चाह सकते हैं।
लिंक एकत्रित करना
आपके लिए एक और फ़ंक्शन — इस बार, आप table . में फ़ीड करेंगे किसी दी गई भाषा के लिए ऑब्जेक्ट, और उम्मीद है कि अन्य प्रोग्रामिंग भाषाओं की एक सूची प्राप्त करें।
def getLinks(t):
try:
table_rows = t.find_all("tr")
for i in range(0,len(table_rows)-1):
try:
if table_rows[i].get_text() == "\nInfluenced\n":
out = []
for j in table_rows[i+1].find_all("a"):
try:
out.append(j['title'])
except:
continue
return out
except:
continue
return
except:
returnवाह, उस सभी घोंसले को देखो ... वास्तव में यहाँ क्या चल रहा है?
यह फ़ंक्शन इस तथ्य का उपयोग करता है कि table वस्तुओं की एक सुसंगत संरचना होती है। तालिका में जानकारी पंक्तियों में संग्रहीत है (प्रासंगिक HTML टैग < . है ट्र>)। इन पंक्तियों में से एक में `टेक्स्ट "\nInfluenced\n" . होगा . फ़ंक्शन के पहले भाग में पता चलता है कि यह कौन सी पंक्ति है।
एक बार यह पंक्ति मिल जाने के बाद, आप निश्चित रूप से अगले के बारे में सुनिश्चित हो सकते हैं पंक्ति में वर्तमान भाषा से प्रभावित प्रत्येक प्रोग्रामिंग भाषा के लिंक होते हैं। find_all("a") . का उपयोग करके ये लिंक खोजें — जहां तर्क "a" HTML टैग से मेल खाती है <a> ।
प्रत्येक लिंक के लिए j , इसका ["title"] संलग्न करें out . नामक सूची की विशेषता . ["title"] . में रुचि लेने का कारण विशेषता इसलिए है क्योंकि यह बिल्कुल . से मेल खाएगा nodes . में संगृहीत भाषा का नाम ।
उदाहरण के लिए, Java को nodes . में स्टोर किया जाता है "Java (programming language)" . के रूप में , इसलिए आपको पूरे डेटा सेट में इस सटीक नाम का उपयोग करने की आवश्यकता है।
सफल होने पर, getLinks() प्रोग्रामिंग भाषाओं की एक सूची देता है। किसी भी स्तर पर कुछ गलत होने की स्थिति में, शेष फ़ंक्शन अपवाद हैंडलिंग से संबंधित है।
डेटा एकत्र करना
अंत में, आप लगभग वापस बैठने के लिए तैयार हैं और स्क्रिप्ट को अपना काम करने दें। यह डेटा एकत्र करेगा और इसे दो सूची वस्तुओं में संग्रहीत करेगा।
edgeList = [["Source,Target"]]
meta = [["Id","Year"]]
अब एक लूप लिखें जो पहले परिभाषित कार्यों को nodes . में प्रत्येक आइटम पर लागू करेगा , और आउटपुट को edgeList . में स्टोर करें और meta ।
for n in nodes:
try:
temp = getSoup(n)
except:
continue
try:
influenced = getLinks(temp)
for link in influenced:
if link in nodes:
edgeList.append([n+","+link])
print([n+","+link])
except:
continue
year = getYear(temp)
meta.append([n,year])
यह फ़ंक्शन प्रत्येक भाषा को nodes . में लेता है और सारांश तालिका को इसके विकिपीडिया पृष्ठ से पुनः प्राप्त करने का प्रयास करता है।
फिर, यह उन सभी भाषाओं को पुनः प्राप्त करता है जिन्हें तालिका सूचीबद्ध करती है क्योंकि वे प्रश्न में भाषा से प्रभावित हैं।
प्रत्येक भाषा के लिए जो nodes . में भी दिखाई देती है सूची, एक तत्व को edgeList . में जोड़ें ["source,target"] . के रूप में . इस तरह, आप Gephi में फ़ीड करने के लिए एक किनारे की सूची तैयार करेंगे।
डिबगिंग उद्देश्यों के लिए, edgeList . में जोड़े गए प्रत्येक तत्व को प्रिंट करें - बस यह सुनिश्चित करने के लिए कि सब कुछ ठीक उसी तरह काम कर रहा है जैसा उसे करना चाहिए। यदि आप अतिरिक्त गहनता से काम कर रहे थे, तो आप except . में प्रिंट स्टेटमेंट जोड़ सकते हैं खंड, भी।
इसके बाद, भाषा का नाम और वर्ष प्राप्त करें, और इन्हें meta . में जोड़ें सूची।
CSV में लिखना
एक बार लूप चलने के बाद, अंतिम चरण edgeList . की सामग्री को लिखना है और meta अल्पविराम से अलग मूल्य (सीएसवी) फाइलों के लिए। यह आसानी से csv . के साथ किया जाता है मॉड्यूल पहले आयात किया गया।
with open("edge_list.csv","w") as f:
wr = csv.writer(f)
for e in edgeList:
wr.writerow(e)
with open("metadata.csv","w") as f2:
wr = csv.writer(f2)
for m in meta:
wr.writerow(m)पूर्ण! स्क्रिप्ट को सहेजें, और टर्मिनल रन से:
$ python3 script.py
आपको प्रत्येक स्रोत-लक्ष्य जोड़ी को प्रिंट करते हुए स्क्रिप्ट को देखना चाहिए क्योंकि यह किनारे की सूची बनाता है। सुनिश्चित करें कि आपका इंटरनेट कनेक्शन स्थिर है, और जब तक स्क्रिप्ट अपना जादू चलाती है तब तक बैठ जाएं।
चरण 3 — Gephi के साथ ग्राफ़ निर्माण
उम्मीद है कि आपने गेफी को पहले स्थापित और चालू कर दिया है। अब आप एक नया प्रोजेक्ट बना सकते हैं और एक निर्देशित ग्राफ़ बनाने के लिए एकत्रित डेटा का उपयोग कर सकते हैं। यह दिखाएगा कि विभिन्न प्रोग्रामिंग भाषाओं ने एक दूसरे को कैसे प्रभावित किया है!
Gephi में एक नया प्रोजेक्ट बनाकर प्रारंभ करें, और "डेटा प्रयोगशाला" दृश्य पर स्विच करें। यह Gephi में डेटा को संभालने के लिए एक स्प्रेडशीट जैसा इंटरफ़ेस प्रदान करता है। करने वाली पहली चीज़ एज लिस्ट को इम्पोर्ट करना है।
- “आयात स्प्रेडशीट” पर क्लिक करें।
edge_list.csvचुनें पायथन लिपि द्वारा उत्पन्न फ़ाइल। सुनिश्चित करें कि Gephi अल्पविराम को विभाजक के रूप में उपयोग करना जानता है।- सूची प्रकार से "एज लिस्ट" चुनें।
- “अगला” पर क्लिक करें और जांचें कि आप स्रोत और लक्ष्य दोनों कॉलम स्ट्रिंग के रूप में आयात कर रहे हैं।
इसे डेटा लैब को नोड्स की सूची के साथ अपडेट करना चाहिए। अब, आयात करें metadata.csv फ़ाइल। इस बार, सूची प्रकार से "नोड्स सूची" चुनना सुनिश्चित करें।
"पूर्वावलोकन" टैब पर स्विच करें, और देखें कि नेटवर्क कैसा दिखता है।
आह... यह थोड़ा सा है... मोनोक्रोम। और गन्दा। स्पेगेटी की प्लेट की तरह। आइए इसे ठीक करें।
इसे सुंदर बनाना
प्रेजेंटेशन पर काम करने के लिए आप हर तरह के तरीके अपना सकते हैं, और यहीं पर थोड़ी सी रचनात्मक स्वतंत्रता आती है। नेटवर्क विज़ुअलाइज़ेशन के साथ, तीन बातों का ध्यान रखना आवश्यक है:
- पोजिशनिंग कई एल्गोरिदम हैं जो नेटवर्क के लिए लेआउट पैटर्न उत्पन्न कर सकते हैं। एक लोकप्रिय विकल्प फ्रूचटरमैन-रींगोल्ड एल्गोरिथम है, जो गेफी में उपलब्ध है।
- आकार देना ग्राफ़ में नोड्स के आकार का उपयोग कुछ दिलचस्प संपत्ति का प्रतिनिधित्व करने के लिए किया जा सकता है। अक्सर, यह एक केंद्रीयता माप . है . केंद्रीयता को मापने के कई तरीके हैं, लेकिन वे सभी किसी दिए गए नोड के "महत्व" को दर्शाते हैं, इस संदर्भ में कि यह बाकी नेटवर्क से कितनी अच्छी तरह जुड़ा हुआ है।
- रंग नोड की कुछ संपत्ति दिखाने के लिए रंग का उपयोग करना भी संभव है। अक्सर, रंग का प्रयोग समुदाय संरचना . को दर्शाने के लिए किया जाता है . इसे मोटे तौर पर "नोड्स के समूह के रूप में परिभाषित किया गया है जो बाकी ग्राफ की तुलना में एक दूसरे से अधिक जुड़े हुए हैं"। एक सामाजिक नेटवर्क में, यह दोस्ती, परिवार या पेशेवर समूहों को प्रकट कर सकता है। कई एल्गोरिदम हैं जो सामुदायिक संरचना का पता लगा सकते हैं। गेफी अंतर्निहित लौवेन पद्धति के साथ आता है।
ये परिवर्तन करने के लिए, आपको कुछ आँकड़ों की गणना करनी होगी। "अवलोकन" विंडो पर स्विच करें। यहां आपको दाईं ओर एक पैनल दिखाई देगा। इसमें एक "सांख्यिकी" टैब होना चाहिए। इसे खोलें, और आपको कई विकल्प दिखाई देंगे।
Gephi कई अंतर्निहित सांख्यिकीय क्षमताओं के साथ आता है। उनमें से प्रत्येक के लिए, "रन" पर क्लिक करने से एक रिपोर्ट तैयार होगी जो नेटवर्क के बारे में अंतर्दृष्टि प्रकट करेगी।
कुछ उपयोगी जानकारियों में शामिल हैं:
- औसत डिग्री औसत भाषा लगभग चार अन्य लोगों से जुड़ी है। रिपोर्ट एक डिग्री वितरण ग्राफ भी दिखाती है। इससे पता चलता है कि अधिकांश भाषाओं में बहुत कम संबंध होते हैं, जबकि एक छोटे अनुपात में बहुत से संबंध होते हैं। इससे पता चलता है कि यह एक स्केल-फ्री . है नेटवर्क . स्केल-फ्री नेटवर्क और उन्हें उत्पन्न करने वाली प्रक्रियाओं पर बहुत शोध किया गया है।
- व्यास इस नेटवर्क का व्यास 12 है - जिसका अर्थ है कि यह किसी भी दो भाषाओं के बीच कनेक्शन की "सबसे बड़ी" संख्या है। औसत पथ की लंबाई सिर्फ चार से कम है। इसका मतलब है कि औसतन किन्हीं दो भाषाओं को चार किनारों से अलग किया जाता है। ये आंकड़े नेटवर्क के "आकार" का माप देते हैं।
- प्रतिरूपकता यह एक ऐसा स्कोर है जो दिखाता है कि नेटवर्क कितना "विभाजित" है। यहां, प्रतिरूपकता स्कोर लगभग 0.53 है। यह अपेक्षाकृत अधिक है, यह सुझाव देता है कि इस नेटवर्क के भीतर अलग-अलग मॉड्यूल हैं। फिर, यह अंतर्निहित प्रणाली के बारे में कुछ दिलचस्प इंगित करता है। भाषाएं अलग-अलग "प्रभाव समूहों" में आती हैं।
किसी भी तरह, नेटवर्क की उपस्थिति को संशोधित करने के लिए, बाएं पैनल पर जाएं।
"लेआउट" टैब में, आप चुन सकते हैं कि किस लेआउट एल्गोरिदम का उपयोग करना है। "रन" को हिट करें और वास्तविक समय में ग्राफ़ शिफ्ट को देखें! देखें कि आपको कौन सा लेआउट एल्गोरिदम सबसे अच्छा काम करता है।
लेआउट टैब के ऊपर "उपस्थिति" टैब है। यहां, आप नोड और किनारे के रंग, आकार और लेबल के लिए विभिन्न सेटिंग्स के साथ खेल सकते हैं। इन्हें विशेषताओं के आधार पर कॉन्फ़िगर किया जा सकता है (गणना करने के लिए आपको Gephi प्राप्त होने वाले आँकड़ों सहित)।
एक सुझाव के रूप में, आप यह कर सकते हैं:
- नोड्स को उनकी Modularity विशेषता से रंग दें। यह उन्हें उनकी समुदाय सदस्यता के अनुसार रंग देता है।
- नोड्स को उनकी डिग्री के अनुसार आकार दें। बेहतर कनेक्टेड नोड कम कनेक्टेड नोड्स की तुलना में बड़े दिखाई देंगे।
हालांकि, आपको प्रयोग करना चाहिए और एक ऐसा लेआउट बनाना चाहिए जो आपको सबसे अच्छा लगे।
एक बार जब आप अपने ग्राफ़ की उपस्थिति से खुश हो जाते हैं, तो यह अंतिम चरण पर जाने का समय है - वेब पर निर्यात करना!
चरण 4 — Sigma.js
आपने पहले से ही एक नेटवर्क विज़ुअलाइज़ेशन बनाया है जिसे Gephi में खोजा जा सकता है। आप स्क्रीनशॉट लेना चुन सकते हैं, या ग्राफ़ को SVG, PDF या PNG प्रारूप में सहेज सकते हैं।
हालाँकि, यदि आपने पहले Sigma.js प्लगइन स्थापित किया था, तो ग्राफ़ को HTML में निर्यात क्यों न करें? यह एक इंटरैक्टिव विज़ुअलाइज़ेशन बनाएगा जिसे आप ऑनलाइन होस्ट कर सकते हैं, या गिटहब पर अपलोड कर सकते हैं और दूसरों के साथ साझा कर सकते हैं।
ऐसा करने के लिए, Gephi के मेनू बार से “निर्यात> Sigma.js टेम्पलेट…” चुनें।
आवश्यकतानुसार विवरण भरें। यह चुनना सुनिश्चित करें कि आप प्रोजेक्ट को किस निर्देशिका में निर्यात करते हैं। आप शीर्षक, किंवदंती, विवरण, होवर व्यवहार और कई अन्य विवरण बदल सकते हैं। जब आप तैयार हों, तो "ओके" पर क्लिक करें।
अब, यदि आप उस निर्देशिका में नेविगेट करते हैं जिसे आपने प्रोजेक्ट निर्यात किया है, तो आपको एक फ़ोल्डर दिखाई देगा जिसमें Sigma.js द्वारा जेनरेट की गई सभी फ़ाइलें होंगी।
index.htmlखोलें अपने पसंदीदा ब्राउज़र में। टा-दा! आपका नेटवर्क है! यदि आप थोड़ी सी सीएसएस और जावास्क्रिप्ट जानते हैं, तो आप अपनी इच्छानुसार आउटपुट को ट्विक करने के लिए विभिन्न जेनरेट की गई फाइलों में जा सकते हैं।
और इसी के साथ यह ट्यूटोरियल समाप्त होता है!
सारांश
- कई प्रणालियों को नेटवर्क के रूप में मॉडल और विज़ुअलाइज़ किया जा सकता है। ग्राफ सिद्धांत गणित की एक शाखा है जो नेटवर्क संरचनाओं और गुणों को समझने में मदद करने के लिए उपकरण प्रदान करती है।
- आपने प्रोग्रामिंग भाषा प्रभाव ग्राफ बनाने के लिए विकिपीडिया से डेटा को स्क्रैप करने के लिए पायथन का उपयोग किया। लिंकेज मानदंड यह था कि क्या किसी दी गई भाषा को दूसरे के डिजाइन पर प्रभाव के रूप में सूचीबद्ध किया गया था।
- Gephi और Sigma.js ओपन-सोर्स टूल हैं जो आपको नेटवर्क का विश्लेषण और कल्पना करने की अनुमति देते हैं। वे आपको छवि, पीडीएफ या वेब प्रारूपों में नेटवर्क निर्यात करने की अनुमति देते हैं।
पढ़ने के लिए धन्यवाद - मैं आपकी किसी भी टिप्पणी या प्रश्न की प्रतीक्षा कर रहा हूं! ग्राफ सिद्धांत के बारे में अधिक जानने के लिए एक शानदार संसाधन के लिए, अल्बर्ट-लास्ज़लो बाराबसी की इंटरैक्टिव ऑनलाइन पुस्तक देखें।
इस ट्यूटोरियल का पूरा कोड यहां पाया जा सकता है।