क्रॉलर विकसित करने के लिए सबसे अच्छे ढांचे में से एक स्क्रैपी है। स्क्रैपी एक लोकप्रिय वेब स्क्रैपिंग और क्रॉलिंग फ्रेमवर्क है जो स्क्रैपिंग वेबसाइटों को आसान बनाने के लिए उच्च-स्तरीय कार्यक्षमता का उपयोग करता है।
इंस्टॉलेशन
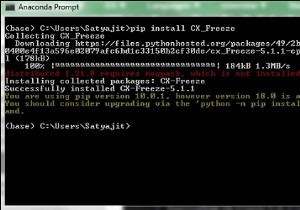
खिड़कियों में स्क्रैपी स्थापित करना आसान है:हम या तो पाइप या कोंडा का उपयोग कर सकते हैं (यदि आपके पास एनाकोंडा है)। स्क्रेपी अजगर 2 और 3 दोनों संस्करणों पर चलता है।
pip install Scrapy
या
conda install –c conda-forge scrapy
यदि स्क्रेपी सही तरीके से स्थापित है, तो एक स्क्रैपी कमांड अब टर्मिनल में उपलब्ध होगी -
C:\Users\rajesh>scrapy Scrapy 1.6.0 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command.
प्रोजेक्ट शुरू करना
अब जब स्क्रेपी स्थापित हो गया है, तो हम स्टार्टप्रोजेक्ट . चला सकते हैं हमारी पहली स्क्रैपी परियोजना के लिए डिफ़ॉल्ट संरचना उत्पन्न करने के लिए आदेश।
ऐसा करने के लिए, टर्मिनल खोलें और उस निर्देशिका में नेविगेट करें जहां आप अपने स्क्रैपी प्रोजेक्ट को स्टोर करना चाहते हैं, और फिर स्क्रैपी स्टार्टप्रोजेक्ट <प्रोजेक्ट का नाम> चलाएं। . नीचे मैं परियोजना के नाम के लिए scrapy_example का उपयोग कर रहा हूँ -
C:\Users\rajesh>scrapy startproject scrapy_example New Scrapy project 'scrapy_example', using template directory 'c:\python\python361\lib\site-packages\scrapy\templates\project', created in: C:\Users\rajesh\scrapy_example You can start your first spider with: cd scrapy_example scrapy genspider example example.com C:\Users\rajesh>cd scrapy_example C:\Users\rajesh\scrapy_example>tree /F Folder PATH listing Volume serial number is 8CD6-8D39 C:. │ scrapy.cfg │ └───scrapy_example │ items.py │ middlewares.py │ pipelines.py │ settings.py │ __init__.py │ ├───spiders │ │ __init__.py │ │ │ └───__pycache__ └───__pycache__
दूसरा तरीका यह है कि हम स्क्रैपी शेल चलाते हैं और वेब स्क्रैपिंग करते हैं, जैसे नीचे -
In [18]: fetch ("https://www.wsj.com/india")
019-02-04 22:38:53 [scrapy.core.engine] DEBUG: Crawled (200) " rel="nofollow noopener noreferrer" target="_blank">https://www.wsj.com/india> (referer: None) स्क्रैपी क्रॉलर एक "प्रतिक्रिया" ऑब्जेक्ट लौटाएगा जिसमें डाउनलोड की गई जानकारी होगी। आइए देखें कि हमारे उपरोक्त क्रॉलर में क्या है -
In [19]: view(response) Out[19]: True
और आपके डिफ़ॉल्ट ब्राउज़र में, वेब लिंक खुल जाएगा और आपको कुछ इस तरह दिखाई देगा -

बढ़िया, यह कुछ हद तक हमारे वेब पेज जैसा दिखता है, इसलिए क्रॉलर ने पूरे वेब पेज को सफलतापूर्वक डाउनलोड कर लिया है।
अब देखते हैं कि हमारे क्रॉलर में क्या है -
In [22]: print(response.text) <!DOCTYPE html> <html data-region = "asia,india" data-protocol = "https" data-reactid = ".2316x0ul96e" data-react-checksum = "851122071"> <head data-reactid = ".2316x0ul96e.0"> <title data-reactid = ".2316x0ul96e.0.0">The Wall Street Journal & Breaking News, Business, Financial and Economic News, World News and Video</title> <meta http-equiv = "X-UA-Compatible" content = "IE = edge" data-reactid = ".2316x0ul96e.0.1"/> <meta http-equiv = "Content-Type" content = "text/html; charset = UTF-8" data-reactid = ".2316x0ul96e.0.2"/> <meta name = "viewport" content = "initial-scale = 1.0001, minimum-scale = 1.0001, maximum-scale = 1.0001, user-scalable = no" data-reactid = ".2316x0ul96e.0.3"/> <meta name = "description" content = "WSJ online coverage of breaking news and current headlines from the US and around the world. Top stories, photos, videos, detailed analysis and in-depth reporting." data-reactid = ".2316x0ul96e.0.4"/> <meta name = "keywords" content = "News, breaking news, latest news, US news, headlines, world news, business, finances, politics, WSJ, WSJ news, WSJ.com, Wall Street Journal" data-reactid = ".2316x0ul96e.0.5"/> <meta name = "page.site" content = "wsj" data-reactid = ".2316x0ul96e.0.7"/> <meta name = "page.site.product" content = "WSJ" data-reactid = ".2316x0ul96e.0.8"/> <meta name = "stack.name" content = "dj01:vir:prod-sections" data-reactid = ".2316x0ul96e.0.9"/> <meta name = "referrer" content = "always" data-reactid = ".2316x0ul96e.0.a"/> <link rel = "canonical" href = "https://www.wsj.com/india/" data-reactid = ".2316x0ul96e.0.b"/> <meta nameproperty = "og:url" content = "https://www.wsj.com/india/" data-reactid = ".2316x0ul96e.0.c:$0"/> <meta nameproperty = "og:title" content = "The Wall Street Journal & Breaking News, Business, Financial and Economic News, World News and Video" data-reactid = ".2316x0ul96e.0.c:$1"/> <meta nameproperty = "og:description" content = "WSJ online coverage of breaking news and current headlines from the US and around the world. Top stories, photos, videos, detailed analysis and in-depth reporting." data-reactid = ".2316x0ul96e.0.c:$2"/> <meta nameproperty = "og:type" content = "website" data-reactid = ".2316x0ul96e.0.c:$3"/> <meta nameproperty = "og:site_name" content = "The Wall Street Journal" data-reactid = ".2316x0ul96e.0.c:$4"/> <meta nameproperty = "og:image" content = "https://s.wsj.net/img/meta/wsj-social-share.png" data-reactid = ".2316x0ul96e.0.c:$5"/> <meta name = "twitter:site" content = "@wsj" data-reactid = ".2316x0ul96e.0.c:$6"/> <meta name = "twitter:app:name:iphone" content = "The Wall Street Journal" data-reactid = ".2316x0ul96e.0.c:$7"/> <meta name = "twitter:app:name:googleplay" content = "The Wall Street Journal" data-reactid = " "/> …& so much more:
आइए इस वेबपेज से कुछ महत्वपूर्ण जानकारी निकालने का प्रयास करें -
वेबपृष्ठ का सटीक शीर्षक -
स्क्रेपी सीएसएस चयनकर्ताओं जैसे क्लास, आईडी आदि के आधार पर एचटीएमएल से जानकारी निकालने के तरीके प्रदान करता है। किसी भी वेबपेज शीर्षक के शीर्षक के लिए सीएसएस चयनकर्ता को खोजने के लिए, बस राइट क्लिक करें और नीचे की तरह निरीक्षण पर क्लिक करें:
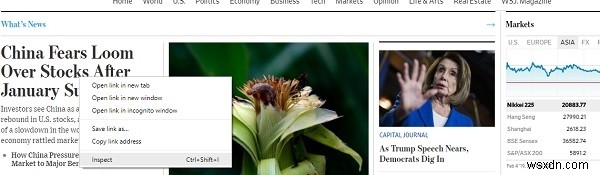
यह आपकी ब्राउज़र विंडो में डेवलपर टूल खोलेगा -
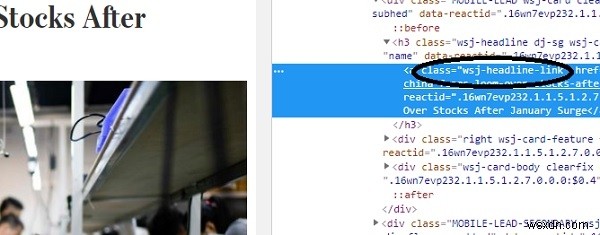
जैसा कि देखा जा सकता है, सीएसएस वर्ग "wsj-headline-link" शीर्षक वाले सभी एंकर () टैग पर लागू होता है। इस जानकारी के साथ, हम प्रतिक्रिया ऑब्जेक्ट में शेष सामग्री से सभी शीर्षक खोजने का प्रयास करेंगे -
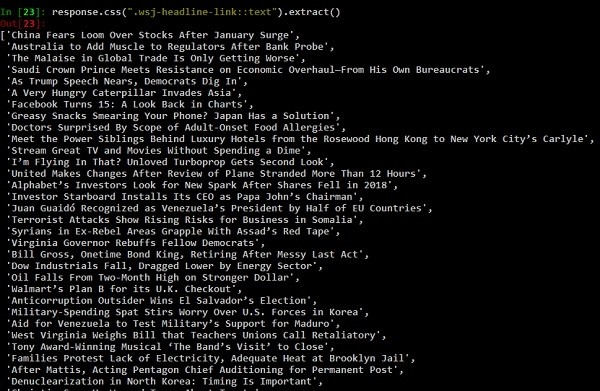
response.css() वह फ़ंक्शन है जो इसे पास किए गए css चयनकर्ता के आधार पर सामग्री निकालेगा (जैसे ऊपर एंकर टैग)। आइए हमारे response.css फ़ंक्शन के कुछ और उदाहरण देखें।
In [24]: response.css(".wsj-headline-link::text").extract_first()
Out[24]: 'China Fears Loom Over Stocks After January Surge' और
In [25]: response.css(".wsj-headline-link").extract_first()
Out[25]: '<a class="wsj-headline-link" href = "https://www.wsj.com/articles/china-fears-loom-over-stocks-after-january-surge-11549276200" data-reactid=".2316x0ul96e.1.1.5.1.0.3.3.0.0.0:$0.1.0">China Fears Loom Over Stocks After January Surge</a>' वेबपेज से सभी लिंक प्राप्त करने के लिए -
links = response.css('a::attr(href)').extract() आउटपुट
['https://www.google.com/intl/en_us/chrome/browser/desktop/index.html', 'https://support.apple.com/downloads/', 'https://www.mozilla.org/en-US/firefox/new/', 'https://windows.microsoft.com/en-us/internet-explorer/download-ie', 'https://www.barrons.com', 'http://bigcharts.marketwatch.com', 'https://www.wsj.com/public/page/wsj-x-marketing.html', 'https://www.dowjones.com/', 'https://global.factiva.com/factivalogin/login.asp?productname=global', 'https://www.fnlondon.com/', 'https://www.mansionglobal.com/', 'https://www.marketwatch.com', 'https://newsplus.wsj.com', 'https://privatemarkets.dowjones.com', 'https://djlogin.dowjones.com/login.asp?productname=rnc', 'https://www.wsj.com/conferences', 'https://www.wsj.com/pro/centralbanking', 'https://www.wsj.com/video/', 'https://www.wsj.com', 'http://www.bigdecisions.com/', 'https://www.businessspectator.com.au/', 'https://www.checkout51.com/?utm_source=wsj&utm_medium=digitalhousead&utm_campaign=wsjspotlight', 'https://www.harpercollins.com/', 'https://housing.com/', 'https://www.makaan.com/', 'https://nypost.com/', 'https://www.newsamerica.com/', 'https://www.proptiger.com', 'https://www.rea-group.com/', …… ……
wsj (वॉल स्ट्रीट जर्नल) वेबपेज से टिप्पणियों की गिनती प्राप्त करने के लिए -
In [38]: response.css(".wsj-comment-count::text").extract()
Out[38]: ['71', '59'] ऊपर सिर्फ स्क्रैपी के माध्यम से वेब-स्क्रैपिंग का परिचय है, हम स्क्रैपी के साथ और भी बहुत कुछ कर सकते हैं।