स्क्रैपी स्पाइडर
स्क्रेपी स्पाइडर एक ऐसा वर्ग है जो वेबसाइट के लिंक का अनुसरण करने और वेबपेजों से जानकारी निकालने की सुविधा प्रदान करता है।
यह मुख्य वर्ग है जिससे अन्य मकड़ियों को विरासत में मिलना चाहिए।
स्क्रैपिंगहब
स्क्रैपिंगहब स्क्रेपी स्पाइडर चलाने के लिए एक ओपन सोर्स एप्लिकेशन है। स्क्रैपिंगहब वेब सामग्री को कुछ उपयोगी डेटा या जानकारी में बदल देता है। यह हमें जटिल वेबपृष्ठों के लिए भी, वेबपृष्ठों से डेटा निकालने की अनुमति देता है।
हम स्क्रैपिंगहब का उपयोग क्लाउड पर स्क्रैपी स्पाइडर को तैनात करने और इसे निष्पादित करने के लिए करने जा रहे हैं।
स्क्रैपिंगहब पर मकड़ियों को तैनात करने के चरण -
चरण1 -
एक स्क्रैपी प्रोजेक्ट बनाएं -
स्क्रैपी स्थापित करने के बाद, बस अपने टर्मिनल में निम्न कमांड चलाएँ -
$scrapy startproject <project_name>
अपनी निर्देशिका को अपने नए प्रोजेक्ट (project_name) में बदलें।
चरण 2 -
अपनी लक्षित वेबसाइट के लिए एक स्क्रैपी स्पाइडर लिखें, आइए एक सामान्य वेबसाइट "quotes.toscrape.com" लें।
नीचे मेरी बहुत ही सरल स्क्रैपी स्पाइडर है -
कोड -
#import scrapy library
import scrapy
class AllSpider(scrapy.Spider):
crawled = set()
#Spider name
name = 'all'
#starting url
start_urls = ['http://www.tutorialspoint.com/']
def __init__(self):
self.links = []
def parse(self, response):
self.links.append(response.url)
for href in response.css('a::attr(href)'):
yield response.follow(href, self.parse) चरण 3 -
अपना स्पाइडर चलाएं और आउटपुट को अपनी लिंक्स.जेसन फ़ाइल में सहेजें -
उपरोक्त कोड को निष्पादित करने के बाद, आप सभी लिंक्स को स्क्रैप कर पाएंगे और उसे लिंक्स.जेसन फ़ाइल के अंदर सहेज सकेंगे। यह एक लंबी प्रक्रिया नहीं हो सकती है, लेकिन इसे लगातार चौबीसों घंटे चलाने के लिए (24/7) हमें इस मकड़ी को स्क्रैपिंगहब पर तैनात करने की आवश्यकता है।
चरण 4 -
स्क्रैपिंगहब पर खाता बनाना
उसके लिए, आपको बस अपने जीमेल खाते या जीथब का उपयोग करके स्क्रैपिंगहब लॉगिन पेज पर लॉग इन करना होगा। यह डैशबोर्ड पर रीडायरेक्ट करेगा।
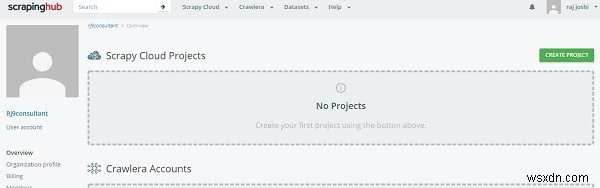
अब क्रिएट प्रोजेक्ट पर क्लिक करें और प्रोजेक्ट के नाम का उल्लेख करें। अब हम कमांड लाइन (सीएलआई) या जीथब के माध्यम से अपने प्रोजेक्ट को क्लाउड में जोड़ सकते हैं। आगे हम अपना कोड shub CLI के माध्यम से परिनियोजित करने जा रहे हैं, पहले shub इंस्टॉल करें
$pip install shub
शुब स्थापित करने के बाद, खाता बनाने पर उत्पन्न एपीआई कुंजी का उपयोग करके शुब खाते में लॉगिन करें (https://app.scrapinghub.com/account/apikey से अपनी एपीआई कुंजी दर्ज करें)।
$shub login
यदि आपकी एपीआई कुंजी ठीक है, तो आप अभी लॉग इन हैं। अब हमें इसे परिनियोजित आईडी का उपयोग करके परिनियोजित करने की आवश्यकता है, जिसे आप "अपना कोड परिनियोजित करें" खंड (6 अंकों की संख्या) के कमांड लाइन अनुभाग पर देखते हैं।
$ shub deploy deploy_id
यह कमांड लाइन से है, अब स्पाइडर डैशबोर्ड सेक्शन पर वापस जाएं, उपयोगकर्ता तैयार स्पाइडर देख सकता है। बस स्पाइडर नेम और रन बटन पर क्लिक करें। बस अब आप अपने डैशबोर्ड में अपने स्पाइडर को देख सकते हैं, कुछ इस तरह -
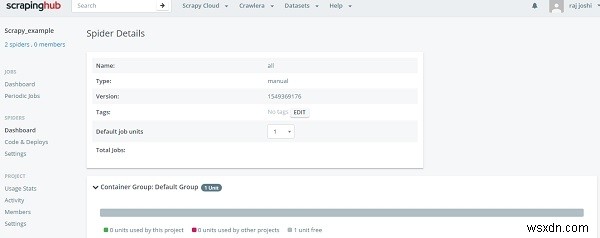
यह हमें एक क्लिक के माध्यम से चल रही प्रगति दिखाएगा और आपको अपनी स्थानीय मशीन को 24/7 चलाने की आवश्यकता नहीं है।