सॉफ्टवेयर विकसित करना चुनौतीपूर्ण हो सकता है, लेकिन इसे बनाए रखना कहीं अधिक चुनौतीपूर्ण है। रखरखाव में सॉफ्टवेयर पैच और सर्वर रखरखाव शामिल है। इस पोस्ट में, हम सर्वर प्रबंधन और रखरखाव पर ध्यान देंगे।
परंपरागत रूप से, सर्वर ऑन-प्रिमाइसेस थे, जिसका अर्थ है भौतिक हार्डवेयर खरीदना और बनाए रखना। क्लाउड कंप्यूटिंग के साथ, इन सर्वरों को अब भौतिक रूप से स्वामित्व की आवश्यकता नहीं है। 2006 में, जब Amazon ने AWS की शुरुआत की और अपनी EC2 सेवा की शुरुआत की, आधुनिक क्लाउड कंप्यूटिंग का युग शुरू हुआ। इस प्रकार की सेवा के साथ, हमें अब भौतिक सर्वर बनाए रखने या भौतिक हार्डवेयर को अपग्रेड करने की आवश्यकता नहीं है। इससे बहुत सारी समस्याएं हल हो गईं, लेकिन सर्वर रखरखाव और संसाधन प्रबंधन अभी भी हमारे ऊपर है। इन विकासों को अगले स्तर पर ले जाते हुए, अब हमारे पास सर्वर रहित तकनीक है।
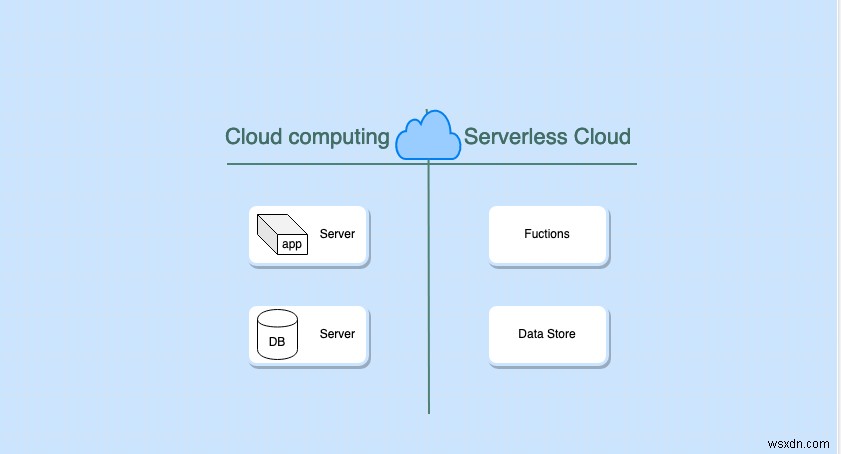
सर्वर रहित तकनीक क्या है?
सर्वर रहित तकनीक क्लाउड प्रदाता को सर्वरों के प्रबंधन और प्रावधान के कार्य को ऑफलोड करने में मदद करती है। इस पोस्ट में, हम AWS पर चर्चा करेंगे।
सर्वर रहित शब्द का अर्थ यह नहीं है कि सर्वर बिल्कुल भी नहीं है। एक सर्वर है, लेकिन यह पूरी तरह से क्लाउड प्रदाता द्वारा प्रबंधित किया जाता है। एक मायने में सर्वर रहित तकनीक के उपयोगकर्ताओं के लिए सर्वर दिखाई नहीं दे रहा है। सर्वर हमें सीधे दिखाई नहीं देते हैं, और उन्हें प्रबंधित करने का कार्य क्लाउड प्रदाता द्वारा स्वचालित किया जाता है। यहां कुछ विशेषताएं दी गई हैं जो इसे सर्वर रहित बनाती हैं:
- कोई परिचालन प्रबंधन नहीं - उच्च उपलब्धता के लिए सर्वर को पैच करने या उन्हें प्रबंधित करने की कोई आवश्यकता नहीं है;
- आवश्यकतानुसार पैमाना - केवल कुछ उपयोगकर्ताओं को सेवा देने से लेकर लाखों उपयोगकर्ताओं को सेवा प्रदान करने तक;
- जाने पर भुगतान करें - लागत उपयोग के आधार पर प्रबंधित की जाती है।
सर्वर रहित तकनीक को निम्नानुसार वर्गीकृत किया जा सकता है:
- गणना करें (जैसे, लैम्ब्डा और फ़ार्गेट)
- संग्रहण (जैसे, S3)
- डेटा स्टोर (जैसे, डायनेमोडीबी और ऑरोरा)
- एकीकरण (जैसे, एपीआई गेटवे, एसएनएस, और एसक्यूएस)
- एनालिटिक्स (जैसे, किनेसिस और एथेना)
सर्वर रहित तकनीक का उपयोग क्यों करें?
लागत
सर्वर रहित तकनीक का उपयोग करने के मुख्य लाभों में से एक है भुगतान करें। जब ट्रैफ़िक की मात्रा में अप्रत्याशित परिवर्तन होता है, तो आपको उपयोग पैटर्न के आधार पर सर्वर को ऊपर या नीचे स्केल करने की आवश्यकता होती है, लेकिन स्व-प्रबंधित ऑटोस्केलिंग के साथ स्केलिंग कठिन और अक्षम हो सकती है। सर्वर रहित कंप्यूटिंग, जैसे कि AWS लैम्ब्डा, आसानी से लागत बचाने में मदद कर सकता है क्योंकि निष्क्रिय समय के दौरान भुगतान करने की कोई आवश्यकता नहीं है।
डेवलपर उत्पादकता
चूंकि सर्वर रहित कंप्यूटिंग क्लाउड प्रदाता द्वारा प्रदान की जाने वाली पूरी तरह से प्रबंधित सेवाओं को संदर्भित करता है, इसलिए डेवलपर्स को सर्वर का प्रावधान करने या सर्वर एप्लिकेशन विकसित करने की कोई आवश्यकता नहीं है। डेवलपर्स सर्वर को प्रबंधित करने की आवश्यकता के बिना तुरंत कोडिंग शुरू कर सकते हैं। यह दृष्टिकोण सर्वर को पैच करने या ऑटोस्केलिंग के प्रबंधन की आवश्यकता को भी दूर करता है। इस पूरे समय को बचाने से डेवलपर्स की उत्पादकता बढ़ाने में मदद मिलती है।
लोच
सर्वर रहित कंप्यूटिंग अत्यधिक लोचदार है और उपयोग के आधार पर ऊपर या नीचे स्केल कर सकती है। उपयोगकर्ताओं में एक स्पाइक को आसानी से नियंत्रित किया जा सकता है। यह एक बड़ा फायदा हो सकता है और डेवलपर्स के लिए बहुत समय बचाने में मदद करता है।
उच्च उपलब्धता
जब कंप्यूटिंग सर्वर रहित होती है और क्लाउड प्रदाता द्वारा प्रबंधित की जाती है और सर्वर के पास उच्च अपटाइम होता है, तो विफलताओं को स्वचालित रूप से नियंत्रित किया जाता है। इस प्रकार के मुद्दों के प्रबंधन के लिए विशेष कौशल की आवश्यकता होती है। सर्वर रहित दृष्टिकोण के साथ, ऑप्स और डेवलपर्स का काम एक ही व्यक्ति द्वारा किया जा सकता है।
रूबी में सर्वर रहित कार्यक्षमता को कैसे कार्यान्वित करें
AWS के अनुसार, रूबी AWS में सबसे अधिक उपयोग की जाने वाली भाषाओं में से एक है। लैम्ब्डा ने नवंबर 2018 में रूबी का समर्थन करना शुरू किया। हम केवल एडब्ल्यूएस द्वारा प्रदान की गई सर्वर रहित तकनीकों का उपयोग करके रूबी में एक वेब एपीआई का निर्माण करेंगे।
AWS में सर्वर रहित इंफ़्रा बनाने के लिए, हम बस AWS कंसोल में लॉग इन कर सकते हैं और उन्हें बनाना शुरू कर सकते हैं। हालांकि, हम कुछ ऐसा विकसित करना चाहते हैं जो आसानी से परीक्षण योग्य हो और आपदा वसूली की सुविधा प्रदान करे। हम सर्वर रहित फीचर को कोड के रूप में लिखेंगे। ऐसा करने के लिए, AWS सर्वर रहित एप्लिकेशन मॉडल (SAM) प्रदान करता है। एसएएम एक ढांचा है जिसका उपयोग एडब्ल्यूएस में सर्वर रहित अनुप्रयोगों के निर्माण के लिए किया जाता है। यह लैम्ब्डा, डेटाबेस और एपीआई को डिजाइन करने के लिए वाईएएमएल-आधारित सिंटैक्स प्रदान करता है। AWS SAM एप्लिकेशन को AWS SAM-CLI का उपयोग करके बनाया जा सकता है, जिसे इस लिंक के माध्यम से डाउनलोड किया जा सकता है।
एडब्ल्यूएस सैम सीएलआई एडब्ल्यूएस क्लाउडफॉर्मेशन के शीर्ष पर बनाया गया है। यदि आप CoudFormation के साथ IaC लिखने से परिचित हैं, तो यह बहुत आसान होगा। वैकल्पिक रूप से, आप सर्वर रहित ढांचे का भी उपयोग कर सकते हैं। इस पोस्ट में, मैं AWS SAM का उपयोग करूँगा।
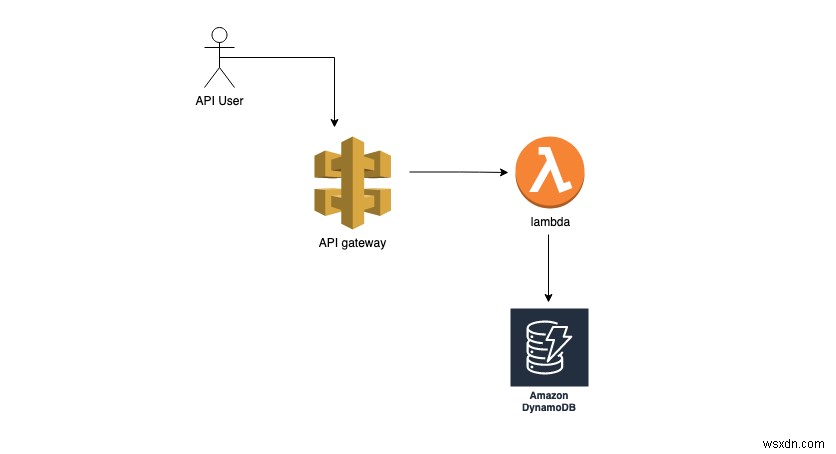
सैम सीएलआई का उपयोग करने से पहले, सुनिश्चित करें कि आपके पास निम्नलिखित हैं:
- एडब्ल्यूएस प्रोफ़ाइल सेटअप
- डॉकर स्थापित
- सैम सीएलआई स्थापित
हम एक सर्वर रहित एप्लिकेशन विकसित करेंगे। हम अपने एप्लिकेशन में कुछ सर्वर रहित इंफ्रा, जैसे डायनेमोडीबी और लैम्ब्डा बनाकर शुरू करेंगे। आइए डेटाबेस से शुरू करें:
डायनेमोडीबी
DynamoDB एक सर्वर रहित AWS-प्रबंधित डेटाबेस सेवा है। चूंकि यह सर्वर रहित है, यह बहुत तेज़ और सेटअप करने में आसान है। DynamoDB बनाने के लिए, हम SAM टेम्पलेट को इस प्रकार परिभाषित करते हैं:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
UsersTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
TableName: users
एसएएम सीएलआई और उपरोक्त टेम्पलेट के साथ, हम एक बुनियादी डायनेमोडीबी तालिका बना सकते हैं। सबसे पहले, हमें अपने सर्वर रहित ऐप के लिए एक पैकेज बनाने की आवश्यकता है। इसके लिए हम निम्न कमांड चलाते हैं। यह पैकेज का निर्माण करेगा और इसे s3 पर धकेल देगा। सुनिश्चित करें कि आपने serverless-users-bucket . नाम से s3 बकेट बनाया है कमांड चलाने से पहले:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
s3 अब हमारे सर्वर रहित ऐप के लिए टेम्पलेट और कोड का स्रोत बन गया है, जिसके बारे में हम बात करेंगे जब हम इसके लिए लैम्ब्डा फ़ंक्शन बनाते हैं।
अब हम इस टेम्पलेट को DynamoDB बनाने के लिए परिनियोजित कर सकते हैं:
$ sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
इसके साथ, हमारे पास डायनेमोडीबी सेटअप है। इसके बाद, हम एक लैम्ब्डा बनाएंगे, जहां इस तालिका का उपयोग किया जाएगा।
लैम्ब्डा
लैम्ब्डा एडब्ल्यूएस द्वारा प्रदान की जाने वाली एक सर्वर रहित कंप्यूटिंग सेवा है। इसका उपयोग वास्तविक सर्वर प्रबंधन की आवश्यकता के बिना आवश्यकतानुसार कोड निष्पादित करने के लिए किया जा सकता है, जहां कोड निष्पादित होता है। लैम्ब्डा का उपयोग Async प्रक्रियाओं, REST API या किसी अनुसूचित कार्य को चलाने के लिए किया जा सकता है। हमें बस एक हैंडलर फंक्शन लिखना है और फ़ंक्शन को AWS लैम्ब्डा पर पुश करें। लैम्ब्डा घटनाओं . के आधार पर कार्य निष्पादित करने का कार्य करेगा . किसी ईवेंट को विभिन्न स्रोतों से ट्रिगर किया जा सकता है, जैसे कि API गेटवे, SQS, या S3; इसे किसी अन्य कोडबेस द्वारा भी ट्रिगर किया जा सकता है। ट्रिगर होने पर, यह लैम्ब्डा फ़ंक्शन ईवेंट और संदर्भ पैरामीटर प्राप्त करता है। इन पैरामीटर के मान ट्रिगर के स्रोत के आधार पर भिन्न होते हैं। हम इन घटनाओं को हैंडलर को पास करके लैम्ब्डा फ़ंक्शन को मैन्युअल रूप से या प्रोग्रामेटिक रूप से ट्रिगर कर सकते हैं। एक हैंडलर दो तर्क लेता है:
ईवेंट - ईवेंट आमतौर पर ट्रिगर के स्रोत से पारित कुंजी-मान हैश होते हैं। इन मानों को स्वचालित रूप से पारित किया जाता है जब वे विभिन्न स्रोतों, जैसे एसक्यूएस, किनेसिस, या एपीआई गेटवे द्वारा ट्रिगर किए जाते हैं। मैन्युअल रूप से ट्रिगर करते समय, हम यहां ईवेंट पास कर सकते हैं। घटना में लैम्ब्डा फ़ंक्शन हैंडलर के लिए इनपुट डेटा है। उदाहरण के लिए, एक एपीआई गेटवे में, अनुरोध निकाय इस घटना के अंदर समाहित है।
संदर्भ - संदर्भ हैंडलर फ़ंक्शन में दूसरा तर्क है। इसमें विशिष्ट विवरण शामिल हैं, जिसमें ट्रिगर का स्रोत, लैम्ब्डा फ़ंक्शन का नाम, संस्करण, अनुरोध-आईडी, और बहुत कुछ शामिल हैं।
हैंडलर का आउटपुट लैम्ब्डा फ़ंक्शन को ट्रिगर करने वाली सेवा को वापस भेज दिया जाता है। लैम्ब्डा फंक्शन का आउटपुट हैंडलर फंक्शन का रिटर्न वैल्यू होता है।
AWS लैम्ब्डा सात अलग-अलग भाषाओं का समर्थन करता है जिसमें आप रूबी सहित कोड कर सकते हैं। यहाँ, हम DynamoDB से कनेक्ट करने के लिए AWS Ruby-sdk का उपयोग करेंगे।
कोड लिखने से पहले, आइए हम एक सैम टेम्पलेट का उपयोग करके लैम्ब्डा के लिए एक इन्फ्रा बनाएं:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: "Serverless users app"
Resources:
CreateUserFunction:
Type: AWS::Serverless::Function
Properties:
Handler: users.create
Runtime: ruby2.7
Policies:
- DynamoDBWritePolicy:
TableName: !Ref UsersTable
Environment:
Variables:
USERS_TABLE: !Ref UsersTable
हैंडलर में, हम Handler: <filename>.<method_name> के रूप में निष्पादित किए जाने वाले फ़ंक्शन का संदर्भ लिखते हैं। ।
किसी नीति के लिए सर्वर रहित नीति टेम्पलेट का संदर्भ लें जिसे आप लैम्ब्डा से उसके द्वारा उपयोग किए जाने वाले संसाधन के आधार पर संलग्न कर सकते हैं। चूँकि हमारा लैम्ब्डा फंक्शन DynamoDB को लिखता है, हमने DynamoDBWritePolicy का उपयोग किया है नीति अनुभाग में।
हम लैम्ब्डा फ़ंक्शन को env वेरिएबल USERS_TABLE भी प्रदान कर रहे हैं ताकि यह निर्दिष्ट डेटाबेस को अनुरोध भेज सके।
तो, लैम्ब्डा इंफ्रा के लिए हमें यही चाहिए। अब, DynamoDB में एक उपयोगकर्ता बनाने के लिए कोड लिखते हैं, जिसे लैम्ब्डा फ़ंक्शन निष्पादित करेगा।
Gemfile में AWS रिकॉर्ड जोड़ें:
# Gemfile
source 'https://rubygems.org' do
gem 'aws-record', '~> 2'
end
DynamoDB में इनपुट लिखने के लिए कोड जोड़ें:
# users.rb
require 'aws-record'
class UsersTable
include Aws::Record
set_table_name ENV['USERS_TABLE']
string_attr :id, hash_key: true
string_attr :body
end
def create(event:,context:)
body = event["body"]
id = SecureRandom.uuid
user = UsersTable.new(id: id, body: body)
user.save!
user.to_h
end
यह बहुत तेज़ और आसान है। AWS aws-record प्रदान करता है DynamoDB तक पहुँचने के लिए रत्न, जो बहुत हद तक रेल के activerecord . के समान है ।
इसके बाद, निर्भरताएँ स्थापित करने के लिए निम्न कमांड चलाएँ।
नोट:सुनिश्चित करें कि आपके पास लैम्ब्डा में परिभाषित रूबी का वही संस्करण है। यहां उदाहरण के लिए, आपको अपनी मशीन पर Ruby2.7 इंस्टॉल करना होगा।
# install dependencies
$ bundle install
$ bundle install --deployment
परिवर्तनों को पैकेज करें:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
परिनियोजित करें:
sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
इस कोड के साथ, अब हमारे पास लैम्ब्डा चल रहा है, जो डेटाबेस में इनपुट लिख सकता है। हम लैम्ब्डा के सामने एक एपीआई गेटवे जोड़ सकते हैं ताकि हम इसे HTTP कॉल के माध्यम से एक्सेस कर सकें। एक एपीआई गेटवे बहुत सी एपीआई प्रबंधन कार्यक्षमता प्रदान करता है, जैसे कि दर सीमित करना और प्रमाणीकरण। हालांकि, यह उपयोग के आधार पर महंगा हो सकता है। एपीआई प्रबंधन के बिना केवल एक HTTP एपीआई का उपयोग करने का एक सस्ता विकल्प है। उपयोग के मामले के आधार पर, आप सबसे उपयुक्त एक चुन सकते हैं।
AWS लैम्ब्डा की कुछ सीमाएँ हैं। उनमें से कुछ को संशोधित किया जा सकता है, लेकिन अन्य को ठीक कर दिया गया है:
- स्मृति - डिफ़ॉल्ट रूप से, एक लैम्ब्डा में इसके निष्पादन समय के दौरान 128 एमबी मेमोरी होती है। इसे 64 एमबी की वृद्धि में 3,008 एमबी तक बढ़ाया जा सकता है।
- समय समाप्त - लैम्ब्डा फ़ंक्शन में कोड निष्पादित करने की समय सीमा होती है। डिफ़ॉल्ट सीमा 3 सेकंड है। इसे 900 सेकंड तक बढ़ाया जा सकता है।
- संग्रहण - लैम्ब्डा एक
/tmpप्रदान करता है भंडारण के लिए निर्देशिका। इस संग्रहण की सीमा 512 एमबी है। - अनुरोध और प्रतिक्रिया आकार - सिंक्रोनस ट्रिगर के लिए 6 एमबी तक और एसिंक्रोनस ट्रिगर के लिए 256 एमबी तक।
- पर्यावरण चर - 4KB तक
चूंकि लैम्ब्डा में इनमें से कुछ सीमाएं हैं, इसलिए कोड लिखना बेहतर है जो इन सीमाओं के भीतर फिट बैठता है। यदि वे ऐसा नहीं करते हैं, तो हम कोड को विभाजित कर सकते हैं ताकि एक लैम्ब्डा दूसरे को ट्रिगर करे। एडब्ल्यूएस द्वारा प्रदान किया गया एक चरण फ़ंक्शन भी है, जिसका उपयोग कई लैम्ब्डा कार्यों को अनुक्रमित करने के लिए किया जा सकता है।
हम सर्वर रहित ऐप्लिकेशन का स्थानीय स्तर पर परीक्षण कैसे कर सकते हैं?
सर्वर रहित अनुप्रयोगों के लिए, हमारे पास एक विक्रेता होना चाहिए जो प्रबंधित सर्वर रहित सेवाएं प्रदान करता हो। हम अपने आवेदन का परीक्षण करने के लिए एडब्ल्यूएस पर निर्भर हैं। आवेदन का परीक्षण करने के लिए, एडब्ल्यूएस द्वारा प्रदान किए गए कुछ स्थानीय विकल्प हैं। कुछ ओपन-सोर्स टूल जो AWS सर्वर रहित तकनीकों के साथ संगत हैं, उनका उपयोग स्थानीय स्तर पर एप्लिकेशन का परीक्षण करने के लिए भी किया जा सकता है।
आइए हम अपने लैम्ब्डा फ़ंक्शन और डायनेमोडीबी का परीक्षण करें। ऐसा करने के लिए, हमें इन्हें स्थानीय रूप से चलाने की आवश्यकता है।
सबसे पहले, एक डॉकर नेटवर्क बनाएं। नेटवर्क लैम्ब्डा फंक्शन और डायनेमोडीबी के बीच संचार में मदद करेगा।
$ docker network create lambda-local --docker-network lambda-local
DynamoDB लोकल AWS द्वारा प्रदान किया गया DynamoDB का एक स्थानीय संस्करण है, जिसका उपयोग हम स्थानीय स्तर पर इसका परीक्षण करने के लिए कर सकते हैं। निम्नलिखित डॉकर छवि चलाकर डायनेमोडीबी लोकल चलाएँ:
$ docker run -p 8000:8000 --network lambda-local --name dynamodb amazon/dynamodb-local
user.rb . में निम्न पंक्ति जोड़ें फ़ाइल। यह लैम्ब्डा को स्थानीय DynamoDB से जोड़ेगा:
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://dynamodb:8000'
)
UsersTable.configure_client(client: local_client)
एक input.json जोड़ें फ़ाइल, जिसमें लैम्ब्डा के लिए इनपुट शामिल है:
{
"name": "Milap Neupane",
"location": "Global"
}
लैम्ब्डा को निष्पादित करने से पहले, हमें टेबल को स्थानीय डायनेमोडीबी में जोड़ना होगा। ऐसा करने के लिए, हम aws-migrate द्वारा प्रदान की गई माइग्रेशन कार्यक्षमता का उपयोग करेंगे। आइए एक फ़ाइल माइग्रेट करें.आरबी बनाएं और निम्नलिखित माइग्रेशन जोड़ें:
require 'aws-record'
require './users.rb'
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://localhost:8000'
)
migration = Aws::Record::TableMigration.new(UsersTable, client: local_client)
migration.create!(
provisioned_throughput: {
read_capacity_units: 5,
write_capacity_units: 5
}
)
migration.wait_until_available
अंत में, निम्न कमांड का उपयोग करके लैम्ब्डा को स्थानीय रूप से निष्पादित करें:
$ sam local invoke "CreateUserFunction" -t sam.yaml \
-e input.json \
--docker-network lambda-local
यह उपयोगकर्ता का डेटा DynamoDB तालिका में बनाएगा।
स्थानीय रूप से एडब्ल्यूएस स्टैक चलाने के लिए लोकलस्टैक जैसे विकल्प हैं।
सर्वर रहित कंप्यूटिंग का उपयोग कब किया जाना चाहिए
सर्वर रहित कंप्यूटिंग का उपयोग करने का निर्णय लेते समय, हमें इसके लाभों और कमियों दोनों के बारे में पता होना चाहिए। निम्नलिखित विशेषताओं के आधार पर, हम तय कर सकते हैं कि सर्वर रहित दृष्टिकोण का उपयोग कब करना है:
लागत
- जब एप्लिकेशन में निष्क्रिय समय और असंगत ट्रैफ़िक होता है, तो लैम्बडास अच्छे होते हैं क्योंकि वे लागत कम करने में मदद करते हैं।
- जब एप्लिकेशन में लगातार ट्रैफ़िक वॉल्यूम होता है, तो AWS लैम्ब्डा का उपयोग करना महंगा हो सकता है।
प्रदर्शन
- यदि एप्लिकेशन प्रदर्शन के प्रति संवेदनशील नहीं है, तो AWS लैम्ब्डा का उपयोग करना एक अच्छा विकल्प है।
- लैम्बडास के पास एक ठंडा बूट समय होता है, जो ठंडे बूट के दौरान धीमी प्रतिक्रिया समय का कारण बन सकता है।
बैकग्राउंड प्रोसेसिंग
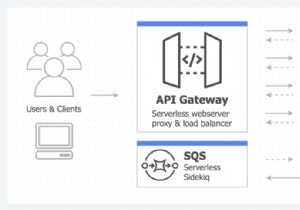
- बैकग्राउंड प्रोसेसिंग के लिए लैम्ब्डा एक अच्छा विकल्प है। कुछ ओपन-सोर्स टूल, जैसे कि साइडकीक, में सर्वर स्केलिंग और रखरखाव ओवरहेड होता है। हम सर्वर रखरखाव की परेशानी के बिना पृष्ठभूमि नौकरियों को संसाधित करने के लिए एडब्ल्यूएस लैम्ब्डा और एडब्ल्यूएस एसक्यूएस कतार को जोड़ सकते हैं।
समवर्ती प्रसंस्करण
- जैसा कि हम जानते हैं, रूबी में समरूपता कुछ ऐसा नहीं है जिसे हम आसानी से कर सकते हैं। लैम्ब्डा के साथ, हम प्रोग्रामिंग भाषा समर्थन की आवश्यकता के बिना समवर्ती प्राप्त कर सकते हैं। लैम्ब्डा को समवर्ती रूप से निष्पादित किया जा सकता है और प्रदर्शन को बेहतर बनाने में मदद करता है।
आवधिक या एक बार की स्क्रिप्ट चलाना
- हम रूबी कोड को निष्पादित करने के लिए क्रॉन जॉब्स का उपयोग करते हैं, लेकिन क्रॉन जॉब्स के लिए सर्वर रखरखाव बड़े पैमाने पर अनुप्रयोगों के लिए मुश्किल हो सकता है। इवेंट-आधारित लैम्ब्डा का उपयोग करने से एप्लिकेशन को स्केल करने में मदद मिलती है।
सर्वर रहित अनुप्रयोगों में लैम्ब्डा कार्यों के लिए ये कुछ उपयोग के मामले हैं। हमें सर्वर रहित सब कुछ बनाने की ज़रूरत नहीं है; हम उपरोक्त निर्दिष्ट उपयोग के मामलों के लिए एक हाइब्रिड मॉडल बना सकते हैं। यह एप्लिकेशन को स्केल करने में मदद करता है और डेवलपर्स की उत्पादकता बढ़ाता है। सर्वर रहित प्रौद्योगिकियां विकसित हो रही हैं और बेहतर हो रही हैं। अन्य सर्वर रहित तकनीकें हैं, जैसे AWS Fatgate और Google CloudRun, जिनमें AWS लैम्ब्डा की सीमाएँ नहीं हैं।