मशीन लर्निंग डेटा से मॉडल बनाने और पहले कभी नहीं देखे गए डेटा पर सामान्यीकरण करने से संबंधित है। मशीन लर्निंग मॉडल को इनपुट के रूप में प्रदान किया गया डेटा ऐसा होना चाहिए कि इसे सिस्टम द्वारा ठीक से समझा जाए, ताकि यह डेटा की व्याख्या कर सके और परिणाम उत्पन्न कर सके।
सीबॉर्न एक पुस्तकालय है जो डेटा की कल्पना करने में मदद करता है। यह अनुकूलित थीम और एक उच्च-स्तरीय इंटरफ़ेस के साथ आता है। यह इंटरफ़ेस डेटा के प्रकार को अनुकूलित और नियंत्रित करने में मदद करता है और जब कुछ फ़िल्टर लागू होते हैं तो यह कैसे व्यवहार करता है।
सीबॉर्न लाइब्रेरी में 'set_Style ()' नामक एक इंटरफ़ेस होता है जो विभिन्न शैलियों के साथ काम करने में मदद करता है। उपरोक्त फ़ंक्शन का उपयोग करके प्लॉट की थीम सेट की जा सकती है।
आइए पायथन में सीबॉर्न का उपयोग करके एक साधारण डेटासेट की कल्पना करने का प्रयास करें -
उदाहरण
import numpy as np
from matplotlib import pyplot as plt
def sine_plot(flip=1):
x = np.linspace(0, 9, 50)
for i in range(1, 7):
plt.plot(x, np.sin(x + i * .68) * (6 - i) * flip)
import seaborn as sb
sb.set_style("whitegrid")
print("The data is being plotted ")
sine_plot()
plt.show() आउटपुट
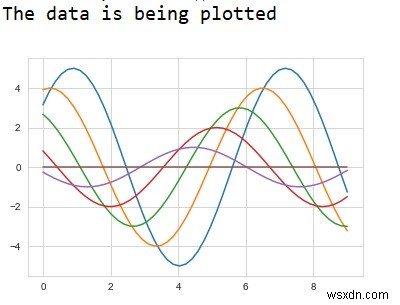
स्पष्टीकरण
- आवश्यक पैकेज आयात किए जाते हैं।
- इनपुट डेटा 'sine_plot' नाम के उपयोगकर्ता परिभाषित फ़ंक्शन का उपयोग करके उत्पन्न किया जाता है।
- सेट_स्टाइल फ़ंक्शन का उपयोग प्लॉट के प्रकार को सेट करने के लिए किया जाता है।
- इस डेटा को सीबॉर्न लाइब्रेरी का उपयोग करके प्लॉट करने के लिए निर्दिष्ट किया गया है
- यह दृश्य डेटा कंसोल पर प्रदर्शित होता है।