सीबॉर्न एक पुस्तकालय है जो डेटा की कल्पना करने में मदद करता है। यह अनुकूलित थीम और एक उच्च-स्तरीय इंटरफ़ेस के साथ आता है।
जब प्रतिगमन मॉडल बनाया जा रहा है, तो बहुसंकेतन की जाँच की जाती है। ऐसा इसलिए है क्योंकि हमें निरंतर चर के सभी विभिन्न संयोजनों के बीच मौजूद सहसंबंध को समझने की आवश्यकता है। यदि चरों के बीच बहुसंरेखण मौजूद है, तो हमें यह सुनिश्चित करना होगा कि इसे डेटा से हटा दिया जाए। यह वह जगह है जहाँ कार्य 'रेगपॉट' और 'इम्प्लाट' चलन में आते हैं। वे रैखिक प्रतिगमन में चर के बीच एक रैखिक संबंध की कल्पना करने में मदद करते हैं।
'रेगप्लॉट' फ़ंक्शन विभिन्न स्वरूपों में चर 'x' और 'y' के लिए मान स्वीकार करता है, और इसमें numpy arrays, पांडा श्रृंखला ऑब्जेक्ट, चर के संदर्भ या पांडा डेटाफ़्रेम से मान शामिल हैं।
दूसरी ओर, फ़ंक्शन 'इम्प्लाट' के लिए उपयोगकर्ता को डेटा के लिए एक विशिष्ट पैरामीटर पास करने की आवश्यकता होती है, और चर 'x' और 'y' के मानों को स्ट्रिंग्स की आवश्यकता होती है। इस प्रकार के डेटा प्रारूप को लॉन्ग-फॉर्म डेटा के रूप में जाना जाता है। यहाँ उदाहरण है -
उदाहरण
import seaborn as sb
from matplotlib import pyplot as plt
my_df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = my_df)
sb.lmplot(x = "total_bill", y = "tip", data = my_df)
plt.show() आउटपुट
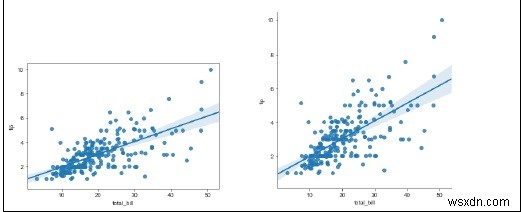
स्पष्टीकरण
- आवश्यक पैकेज आयात किए जाते हैं।
- इनपुट डेटा 'टिप्स' है जो सीबॉर्न लाइब्रेरी से लोड किया गया है।
- यह डेटा डेटाफ़्रेम में संग्रहीत किया जाता है।
- 'load_dataset' फ़ंक्शन का उपयोग आईरिस डेटा को लोड करने के लिए किया जाता है।
- यह डेटा 'regplot' फ़ंक्शन का उपयोग करके विज़ुअलाइज़ किया जाता है।
- इस डेटा को 'इम्प्लाट' फ़ंक्शन का उपयोग करके विज़ुअलाइज़ किया जाता है।
- यहां, डेटाफ्रेम पैरामीटर के रूप में दिया गया है।
- साथ ही, x और y मान निर्दिष्ट हैं।
- यह डेटा कंसोल पर प्रदर्शित होता है।