Tensorflow एक मशीन लर्निंग फ्रेमवर्क है जो Google द्वारा प्रदान किया जाता है। यह एक ओपन-सोर्स फ्रेमवर्क है जिसका उपयोग पायथन के संयोजन में एल्गोरिदम, गहन शिक्षण अनुप्रयोगों और बहुत कुछ को लागू करने के लिए किया जाता है। इसका उपयोग अनुसंधान और उत्पादन उद्देश्यों के लिए किया जाता है। इसमें अनुकूलन तकनीकें हैं जो जटिल गणितीय कार्यों को शीघ्रता से करने में मदद करती हैं।
कोड की निम्न पंक्ति का उपयोग करके विंडोज़ पर 'टेंसरफ़्लो' पैकेज स्थापित किया जा सकता है -
pip install tensorflow
केरस को प्रोजेक्ट ONEIROS (ओपन एंडेड न्यूरो-इलेक्ट्रॉनिक इंटेलिजेंट रोबोट ऑपरेटिंग सिस्टम) के लिए अनुसंधान के एक भाग के रूप में विकसित किया गया था। केरस एक डीप लर्निंग एपीआई है, जिसे पायथन में लिखा गया है। यह एक उच्च-स्तरीय एपीआई है जिसमें एक उत्पादक इंटरफ़ेस है जो मशीन सीखने की समस्याओं को हल करने में मदद करता है।
यह अत्यधिक स्केलेबल है, और क्रॉस प्लेटफॉर्म क्षमताओं के साथ आता है। इसका मतलब है कि केरस को टीपीयू या जीपीयू के क्लस्टर पर चलाया जा सकता है। केरस मॉडल को वेब ब्राउज़र या मोबाइल फोन में भी चलाने के लिए निर्यात किया जा सकता है।
केरस पहले से ही Tensorflow पैकेज में मौजूद है। इसे कोड की नीचे दी गई लाइन का उपयोग करके एक्सेस किया जा सकता है।
import tensorflow from tensorflow import keras
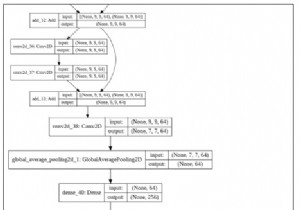
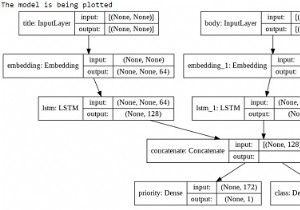
केरस कार्यात्मक एपीआई ऐसे मॉडल बनाने में मदद करता है जो अनुक्रमिक एपीआई का उपयोग करके बनाए गए मॉडल की तुलना में अधिक लचीले होते हैं। कार्यात्मक एपीआई उन मॉडलों के साथ काम कर सकता है जिनमें गैर-रेखीय टोपोलॉजी है, परतों को साझा कर सकते हैं और कई इनपुट और आउटपुट के साथ काम कर सकते हैं। एक गहन शिक्षण मॉडल आमतौर पर एक निर्देशित चक्रीय ग्राफ (DAG) होता है जिसमें कई परतें होती हैं। कार्यात्मक एपीआई परतों का ग्राफ बनाने में मदद करता है।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है। निम्नलिखित कोड स्निपेट है -
उदाहरण
print("Load the MNIST data")
print("Split data into training and test data")
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print("Reshape the data for better training")
x_train = x_train.reshape(60000, 784).astype("float32") / 255
x_test = x_test.reshape(10000, 784).astype("float32") / 255
print("Compile the model")
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.RMSprop(),
metrics=["accuracy"],
)
print("Fit the data to the model")
history = model.fit(x_train, y_train, batch_size=64, epochs=2, validation_split=0.2)
test_scores = model.evaluate(x_test, y_test, verbose=2)
print("The loss associated with model:", test_scores[0])
print("The accuracy of the model:", test_scores[1]) कोड क्रेडिट - https://www.tensorflow.org/guide/keras/functional
आउटपुट
Load the MNIST data Split data into training and test data Reshape the data for better training Compile the model Fit the data to the model Epoch 1/2 750/750 [==============================] - 3s 3ms/step - loss: 0.5768 - accuracy: 0.8394 - val_loss: 0.2015 - val_accuracy: 0.9405 Epoch 2/2 750/750 [==============================] - 2s 3ms/step - loss: 0.1720 - accuracy: 0.9495 - val_loss: 0.1462 - val_accuracy: 0.9580 313/313 - 0s - loss: 0.1433 - accuracy: 0.9584 The loss associated with model: 0.14328785240650177 The accuracy of the model: 0.9584000110626221
स्पष्टीकरण
-
इनपुट डेटा (MNIST डेटा) को परिवेश में लोड किया जाता है।
-
डेटा को प्रशिक्षण और परीक्षण सेट में विभाजित किया गया है।
-
डेटा को फिर से आकार दिया जाता है ताकि इसकी सटीकता बेहतर हो जाए।
-
मॉडल बनाया और संकलित किया गया है।
-
यह तब प्रशिक्षण डेटा के लिए उपयुक्त है।
-
प्रशिक्षण से जुड़ी सटीकता और हानि कंसोल पर प्रदर्शित होती है।