फूल डेटासेट को 'image_dataset_from_directory' की मदद से केरस प्रीप्रोसेसिंग एपीआई का उपयोग करके प्रशिक्षण और सत्यापन सेट में विभाजित किया जा सकता है, जो सत्यापन सेट के लिए प्रतिशत विभाजन के लिए कहता है।
और पढ़ें: TensorFlow क्या है और Keras कैसे तंत्रिका नेटवर्क बनाने के लिए TensorFlow के साथ काम करता है?
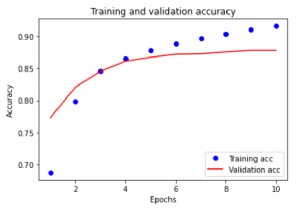
एक इमेज क्लासिफायरियर एक केरस का उपयोग करके बनाया जाता है। अनुक्रमिक मॉडल, और डेटा को preprocessing.image_dataset_from_directory का उपयोग करके लोड किया जाता है। . डेटा कुशलता से डिस्क से लोड होता है। ओवरफिटिंग की पहचान की जाती है और इसे कम करने के लिए तकनीकों को लागू किया जाता है। इन तकनीकों में डेटा वृद्धि, और ड्रॉपआउट शामिल हैं। 3700 फूलों के चित्र हैं। इस डेटासेट में 5 उप निर्देशिकाएं हैं, और प्रति वर्ग एक उप निर्देशिका है। वे हैं:डेज़ी, सिंहपर्णी, गुलाब, सूरजमुखी और ट्यूलिप।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है।
batch_size = 32
img_height = 180
img_width = 180
print("The data is being split into training and validation set")
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size) कोड क्रेडिट:https://www.tensorflow.org/tutorials/images/classification
आउटपुट
The data is being split into training and validation set Found 3670 files belonging to 5 classes. Using 2936 files for training.
स्पष्टीकरण
- इन छवियों को image_dataset_from_directory उपयोगिता का उपयोग करके डिस्क से लोड किया जाता है।
- यह डिस्क पर छवियों की निर्देशिका से tf.data.Dataset पर जाएगा।
- डेटा डाउनलोड हो जाने के बाद, लोडर के लिए कुछ पैरामीटर निर्धारित किए जाते हैं।
- डेटा को प्रशिक्षण और सत्यापन सेट में विभाजित किया गया है।