मशीन लर्निंग में कई प्रकार के क्लस्टरिंग एल्गोरिदम हैं। इन एल्गोरिदम को पायथन में लागू किया जा सकता है। इस लेख में, आइए हम पायथन का उपयोग करके 'मीन-शिफ्ट' एल्गोरिथम पर चर्चा करें और उसे लागू करें। यह एक क्लस्टरिंग एल्गोरिथम है जिसका उपयोग एक अनुपयोगी शिक्षण पद्धति के रूप में किया जाता है।
इस एल्गोरिथम में कोई अनुमान नहीं लगाया जाता है। इसका तात्पर्य है कि यह एक गैर-पैरामीट्रिक एल्गोरिथम है। यह एल्गोरिथम कुछ समूहों को डेटा बिंदुओं को पुनरावृत्त रूप से असाइन करता है, जो इन डेटा बिंदुओं को डेटा बिंदुओं के उच्चतम घनत्व की ओर स्थानांतरित करके किया जाता है।
डेटा बिंदुओं के इस उच्च घनत्व को क्लस्टर के केंद्रक के रूप में जाना जाता है। मीन शिफ्ट एल्गोरिथम और K मतलब क्लस्टरिंग के बीच अंतर यह है कि पूर्व (K−मीन्स) में क्लस्टर की संख्या को पहले से निर्दिष्ट करने की आवश्यकता होती है।
ऐसा इसलिए है क्योंकि मौजूद डेटा के आधार पर K यानि एल्गोरिथम की मदद से क्लस्टर की संख्या पाई जाती है।
आइए हम मीन-शिफ्ट एल्गोरिथम के चरणों को समझें -
-
डेटा बिंदु स्वयं के एक समूह को असाइन किए जाते हैं।
-
फिर, इन समूहों के केन्द्रक निर्धारित किए जाते हैं।
-
इन केन्द्रक का स्थान क्रमिक रूप से अद्यतन किया जाता है।
-
इसके बाद, प्रक्रिया उच्च घनत्व वाले क्षेत्रों में चली जाती है।
-
एक बार जब केन्द्रक ऐसी स्थिति में पहुँच जाते हैं जहाँ वे आगे नहीं बढ़ सकते, तो प्रक्रिया रुक जाती है।
आइए समझते हैं कि scikit−learn -
. का उपयोग करके इसे पायथन में कैसे लागू किया जा सकता हैउदाहरण
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
from sklearn.datasets.samples_generator import make_blobs
centers = [[3,3,1],[4,5,5],[11,10,10]]
X, _ = make_blobs(n_samples = 950, centers = centers, cluster_std = 0.89)
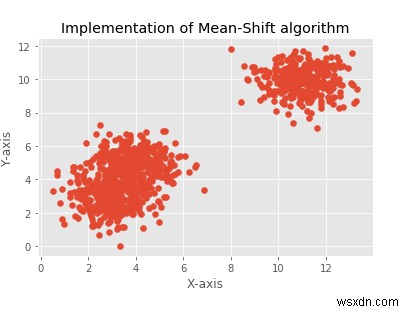
plt.title("Implementation of Mean-Shift algorithm")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.scatter(X[:,0],X[:,1])
plt.show()
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
clusterCent = ms.cluster_centers_
print(clusterCent)
numCluster = len(np.unique(labels))
print("Estimated clusters:", numCluster)
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
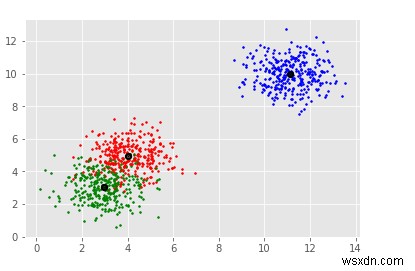
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 3)
plt.scatter(clusterCent[:,0],clusterCent[:,1],
marker=".",color='k', s=20, linewidths = 5, zorder=10)
plt.show() आउटपुट
[[ 3.05250924 3.03734994 1.06159541] [ 3.92913017 4.99956874 4.86668482] [10.99127523 10.02361122 10.00084718]] Estimated clusters: 3
स्पष्टीकरण
-
आवश्यक पैकेज आयात किए जाते हैं और इसका उपनाम उपयोग में आसानी के लिए परिभाषित किया गया है।
-
'जीजीप्लॉट' 'शैली' वर्ग में मौजूद 'उपयोग' फ़ंक्शन के लिए निर्दिष्ट है।
-
डेटा के क्लस्टर बनाने के लिए 'make_blobs' फ़ंक्शन का उपयोग किया जाता है।
-
'X' अक्ष, 'Y' अक्ष और शीर्षक के लिए लेबल प्रदान करने के लिए set_xlabel, set_ylabel और set_title फ़ंक्शन का उपयोग किया जाता है।
-
'मीनशिफ्ट' फ़ंक्शन को कहा जाता है, और एक वेरिएबल को असाइन किया जाता है।
-
डेटा मॉडल के अनुकूल है।
-
क्लस्टर के लेबल और संख्या निर्धारित की गई है।
-
यह डेटा प्लॉट किया जाता है, और मॉडल में फिट होने वाले डेटा के लिए स्कैटर प्लॉट भी प्रदर्शित होता है।
-
यह 'शो' फ़ंक्शन का उपयोग करके कंसोल पर दिखाया जाता है।