Tensorflow एक मशीन लर्निंग फ्रेमवर्क है जो Google द्वारा प्रदान किया जाता है। यह एक ओपन-सोर्स फ्रेमवर्क है जिसका उपयोग पायथन के संयोजन में एल्गोरिदम, गहन शिक्षण अनुप्रयोगों और बहुत कुछ को लागू करने के लिए किया जाता है। इसका उपयोग अनुसंधान और उत्पादन उद्देश्यों के लिए किया जाता है।
'आईएमडीबी' डेटासेट में 50 हजार से अधिक फिल्मों की समीक्षाएं हैं। यह डेटासेट आमतौर पर प्राकृतिक भाषा प्रसंस्करण से जुड़े कार्यों के लिए उपयोग किया जाता है।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है।
एक प्लॉट बनाने के लिए कोड स्निपेट निम्नलिखित है जो IMDB डेटासेट में समय के संबंध में सटीकता और हानि की कल्पना करता है -
उदाहरण
history_dict = history.history
history_dict.keys()
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, 'ro', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss with respect to time')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show() कोड क्रेडिट - https://www.tensorflow.org/tutorials/keras/text_classification
आउटपुट
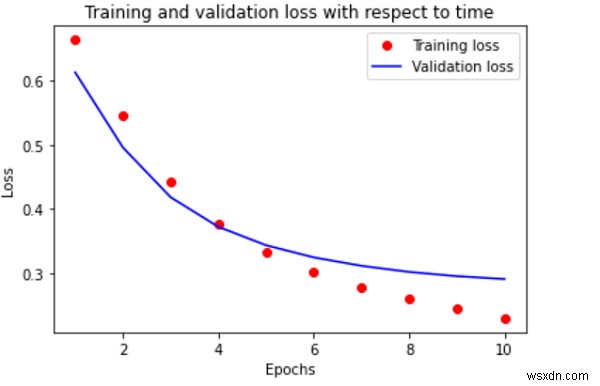
स्पष्टीकरण
-
एक बार जब डेटा मॉडल के अनुकूल हो जाता है, तो वास्तविक मूल्यों और अनुमानित मूल्यों की तुलना करने की आवश्यकता होती है।
-
ऐसा करने का सबसे अच्छा तरीका विज़ुअलाइज़ेशन है।
-
इसलिए, समय के संबंध में प्रशिक्षण और सत्यापन के दौरान हुई हानि की साजिश के लिए 'मैटप्लोटलिब' पुस्तकालय का उपयोग किया जाता है।
-
यह मॉडल को फिट करने के लिए डेटा को प्रशिक्षित करने के लिए उठाए गए कदमों (या युगों) की संख्या पर आधारित है।