विधि 1 - केंद्रीय प्रवृत्ति और परिवर्तनशीलता की गणना
<पी>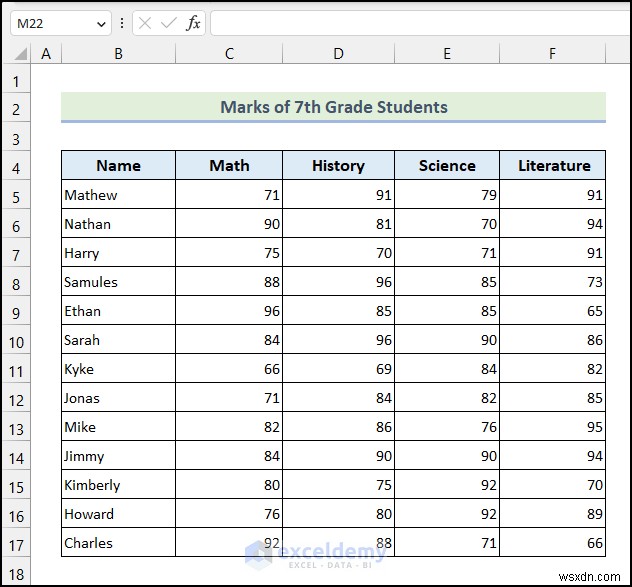 <पी> 7वीं कक्षा के छात्रों के उपरोक्त डेटासेट अंक गणित के आधार पर दिए गए हैं , इतिहास , विज्ञान , और साहित्य विषय.
<पी> 7वीं कक्षा के छात्रों के उपरोक्त डेटासेट अंक गणित के आधार पर दिए गए हैं , इतिहास , विज्ञान , और साहित्य विषय. 1.1 औसत फ़ंक्शन का उपयोग करना
<पी>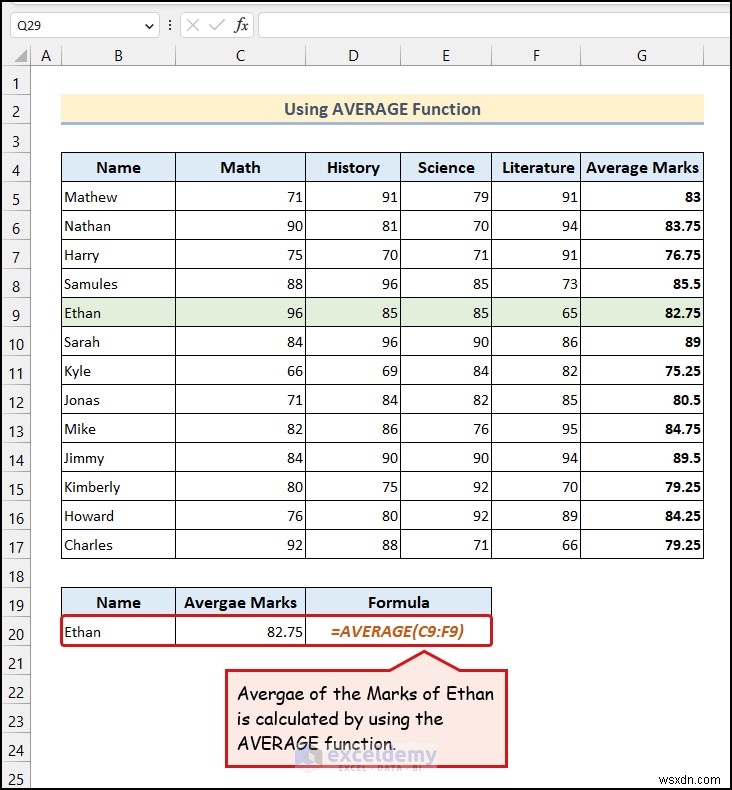 <पी> आप औसत अंक देखें एथन के लिए सेल C20 में . <पी> यहां, हमने AVERAGE फ़ंक्शन का उपयोग किया है , जो डेटासेट का अंकगणितीय माध्य लौटाता है।
<पी> आप औसत अंक देखें एथन के लिए सेल C20 में . <पी> यहां, हमने AVERAGE फ़ंक्शन का उपयोग किया है , जो डेटासेट का अंकगणितीय माध्य लौटाता है। - सेल C20 में निम्नलिखित सूत्र दर्ज करें:
1.2 AVERAGEIF और AVERAGEIFS फ़ंक्शंस को नियोजित करना
<पी>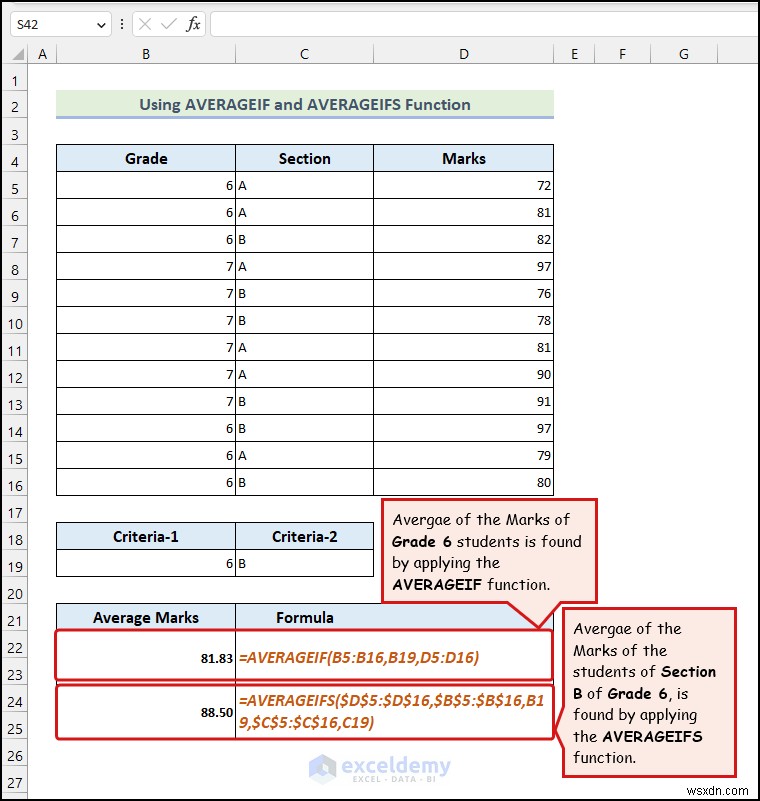 <पी> उपरोक्त डेटासेट AVERAGEIF के विविध उपयोगों को दर्शाता है और औसत कार्य. <पी> आप कक्षा 6 के विद्यार्थियों द्वारा प्राप्त अंकों का औसत ज्ञात करना चाहते हैं। ऐसा करने के लिए,
<पी> उपरोक्त डेटासेट AVERAGEIF के विविध उपयोगों को दर्शाता है और औसत कार्य. <पी> आप कक्षा 6 के विद्यार्थियों द्वारा प्राप्त अंकों का औसत ज्ञात करना चाहते हैं। ऐसा करने के लिए, - सेल B22: में निम्नलिखित सूत्र दर्ज करें
=AVERAGEIF(B5:B16,B19,D5:D16) <पी> यहां, सेल B19 उन मानदंडों को इंगित करता है जिनके आधार पर हम औसत अंक पाएंगे .
<पी> आइए एक और स्थिति मान लें जहां हम औसत अंक खोजना चाहते हैं छात्रों की संख्यादो मानदंडों के आधार पर:उनका ग्रेड और अनुभाग .
- सेल C24 में निम्न सूत्र दर्ज करें :
=AVERAGEIFS($D$5:$D$16,$B$5:$B$16,B19,$C$5:$C$16,C19) <पी> यहां, सेल की रेंज $D$5:$D$16 है चिह्न की कोशिकाओं को इंगित करता है स्तंभ, कक्षों की श्रेणी $B$5:$B$16 ग्रेड की कोशिकाओं को संदर्भित करता है स्तंभ, और कक्षों की श्रेणी $C$5:$C$16 अनुभाग की कोशिकाओं को इंगित करता है स्तंभ. कोशिकाएं बी19 और C19 दो मानदंडों का प्रतिनिधित्व करते हैं . 1.3 हरमीन और जियोमीन कार्यों का उपयोग
<पी> मान लीजिए कि हमारे पास डेटा के रूप में छह नंबर हैं। संख्याएँ 1,2,3,4,5 और 6 हैं। तब हमारा हार्मोनिक माध्य मान इस प्रकार होगा। <पी>Harmonic Mean = 11+1/2+1/3+1/4+1/5+1/66 = 2.4489 <पी> जियोमीन फ़ंक्शन ज्यामितीय माध्य की गणना करता है चयनित डेटासेट का. ज्यामितीय माध्य की गणना nवाँ मूल ढूंढकर की जाती है गुणा करने के बादन किसी डेटासेट का मान. यहाँ,न किसी डेटासेट में मानों की कुल संख्या है। उदाहरण के लिए, मान लें कि हमारे पास 5 है हमारे डेटासेट के रूप में संख्याएँ। ये 1, 2, 3, 4, और 5 हैं। तो,ज्यामितीय माध्य होगा, <पी> Geometric Mean = 51*2*3*4*5 = 2.6051. <पी> 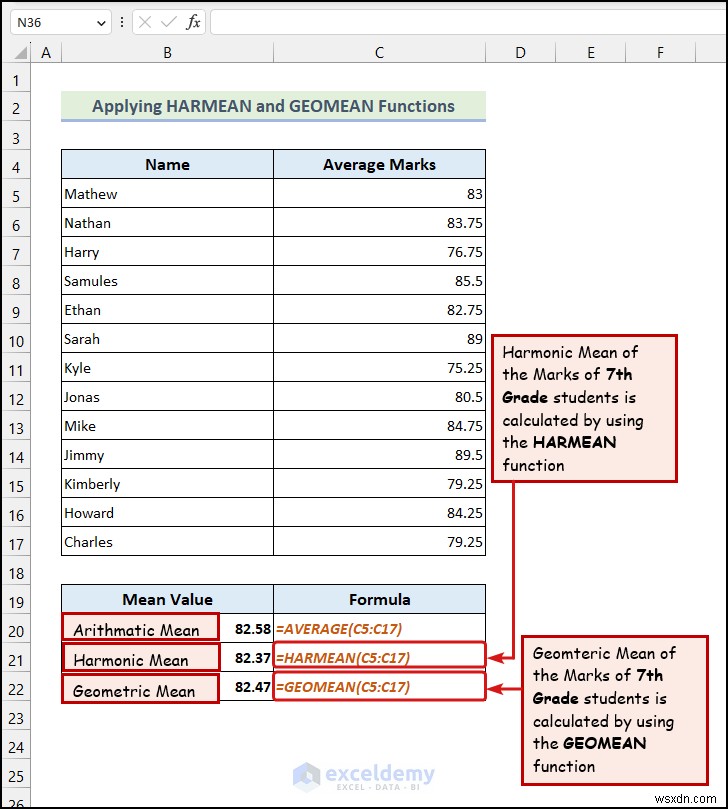 <पी> उपरोक्त छवि HARMEAN दोनों का उपयोग करने का एक व्यावहारिक उदाहरण दर्शाती है और GEOMEAN कार्य.
<पी> उपरोक्त छवि HARMEAN दोनों का उपयोग करने का एक व्यावहारिक उदाहरण दर्शाती है और GEOMEAN कार्य. - B21 में हार्मोनिक माध्य की गणना करने का सूत्र सेल है:
<पी> एक बात स्पष्ट है:इस मामले में, हार्मोनिक माध्य का मान, औसत अंकों के औसत मान से कम है। अंकगणितीय माध्य 82.58 है , लेकिन हार्मोनिक माध्य82.37है . इसका मतलब है कि यह औसत अंक के बड़े मूल्य के मूल्य को सीमित करता है .
- ज्यामितीय माध्य ज्ञात करने के मामले में, हमने सेल C22 में निम्नलिखित सूत्र का उपयोग किया है:
1.4 मानकीकृत फ़ंक्शन लागू करना
<पी> कदम : <पी>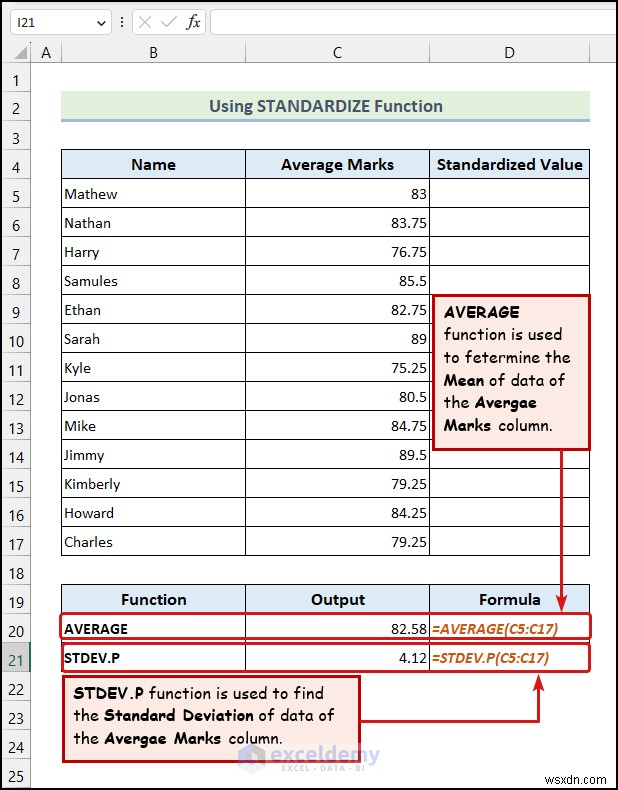
- Cमाध्य और मानक विचलन की गणना करें डेटासेट का.
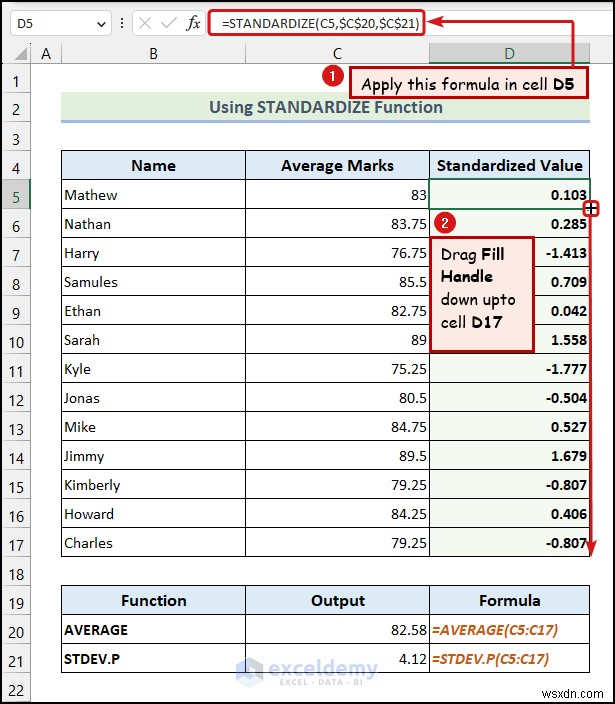
- सेल D5: में निम्नलिखित सूत्र दर्ज करें
=STANDARDIZE(C5,$C$20,$C$21) <पी> यहां, सेल C5 औसत अंकको दर्शाता है मैथ्यू का , सेल $C$20 माध्य मान को इंगित करता है , और सेल $C$21 STDEV.P (मानक विचलन) को संदर्भित करता है मूल्य.
<पी> आप MODE.SNGL का उपयोग कर सकते हैं , मध्यस्थ , VAR.S , VAR.P , STDEV.S , और STDEV.P एक्सेल में डेटा का आगे सांख्यिकीय विश्लेषण करने का कार्य करता है।
विधि 2 - सापेक्ष स्थिति की गणना
<पी> मान लीजिए कि 5वाँ दोनों हैं और छठा -रैंकिंग मान समान हैं। उस स्थिति में, RANK.EQ फ़ंक्शन रैंक 5 लौटाएगा दोनों मानों के लिए, और अगला रैंक मान रैंक 7 होगा . यहां, हमारे पास कुल अंक हैं सातवें का ग्रेड के छात्र हमारे डेटासेट के रूप में। <पी>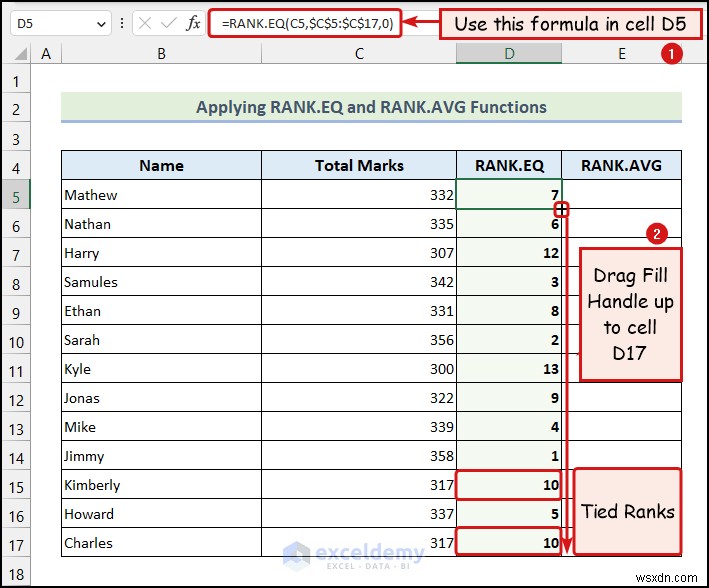 <पी> यहां आप देख सकते हैं कि 10 और 11वाँ मूल्यों को बांध दिया गया. तो, RANK.EQ फ़ंक्शन ने रैंक 10 लौटाई दोनों मूल्यों के लिए.
<पी> यहां आप देख सकते हैं कि 10 और 11वाँ मूल्यों को बांध दिया गया. तो, RANK.EQ फ़ंक्शन ने रैंक 10 लौटाई दोनों मूल्यों के लिए. - हमने सेल D5 में निम्नलिखित सूत्र लागू किया है .
=RANK.EQ(C5,$C$5:$C$17,0) <पी> यहां, सेल C5 कुल मार्क्स की पहली सेल को संदर्भित करता है स्तंभ, और कक्षों की श्रेणी $C$5:$C$17 कुल चिह्न की कोशिकाओं का प्रतिनिधित्व करता है स्तंभ.
<पी>
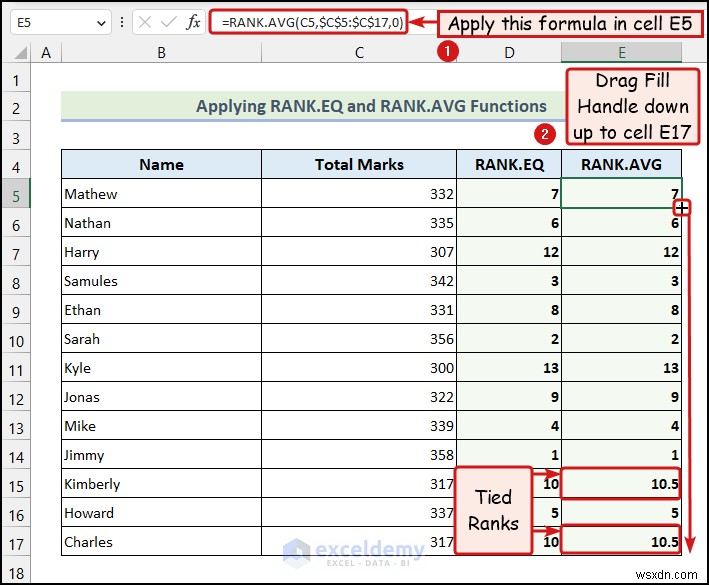 <पी> यहां, 10वां और 11वां मान बंधा हुआ था, इसलिए RANK.AVG फ़ंक्शन ने औसतन 10.5 लौटाया दोनों मूल्यों के लिए. <पी> रैंक.एवीजी फ़ंक्शन किसी डेटासेट की सापेक्ष रैंक भी लौटाता है। लेकिन, संबंधों के मामले में, यह एक औसत रैंक लौटाएगा बंधे मूल्यों के लिए. उदाहरण के लिए, मान लीजिए चौथा और 5वीं रैंक के मान बंधे हुए हैं। तो, RANK.AVG फ़ंक्शन 4.5 की रैंक लौटाएगा दोनों मूल्यों के लिए. अगले मान की रैंक 6 होगी . अब, आइए RANK.AVG का उपयोग करने के लिए नीचे दिए गए निर्देशों का उपयोग करें डेटा का सांख्यिकीय विश्लेषण करने के लिए एक्सेल में कार्य करें।
<पी> यहां, 10वां और 11वां मान बंधा हुआ था, इसलिए RANK.AVG फ़ंक्शन ने औसतन 10.5 लौटाया दोनों मूल्यों के लिए. <पी> रैंक.एवीजी फ़ंक्शन किसी डेटासेट की सापेक्ष रैंक भी लौटाता है। लेकिन, संबंधों के मामले में, यह एक औसत रैंक लौटाएगा बंधे मूल्यों के लिए. उदाहरण के लिए, मान लीजिए चौथा और 5वीं रैंक के मान बंधे हुए हैं। तो, RANK.AVG फ़ंक्शन 4.5 की रैंक लौटाएगा दोनों मूल्यों के लिए. अगले मान की रैंक 6 होगी . अब, आइए RANK.AVG का उपयोग करने के लिए नीचे दिए गए निर्देशों का उपयोग करें डेटा का सांख्यिकीय विश्लेषण करने के लिए एक्सेल में कार्य करें। - हमने सेल E5: में निम्नलिखित सूत्र का उपयोग किया है
=RANK.AVG(C5,$C$5:$C$17,0) <पी> इसके अलावा, आप PERCENTRANK.INC का भी उपयोग कर सकते हैं , PERCENTRANK.EXC , PERCENTILE.INC , PERCENTILE.EXC , QUARTILE.INC और QUARTILE.EXC फ़ंक्शन Excel में डेटा की सापेक्ष स्थिति की गणना करने के लिए।
विधि 3 - सहसंबंध और प्रतिगमन का निर्धारण
3.1 SLOPE, INTERCEPT, और STYEX फ़ंक्शंस का उपयोग करना
<पी> STYEX फ़ंक्शन हमें Y मान की मानक त्रुटि देता है दिए गए X मान के लिए . हम इसका उपयोग Y मान की भविष्यवाणी करने के लिए कर सकते हैं एक X मान से . <पी>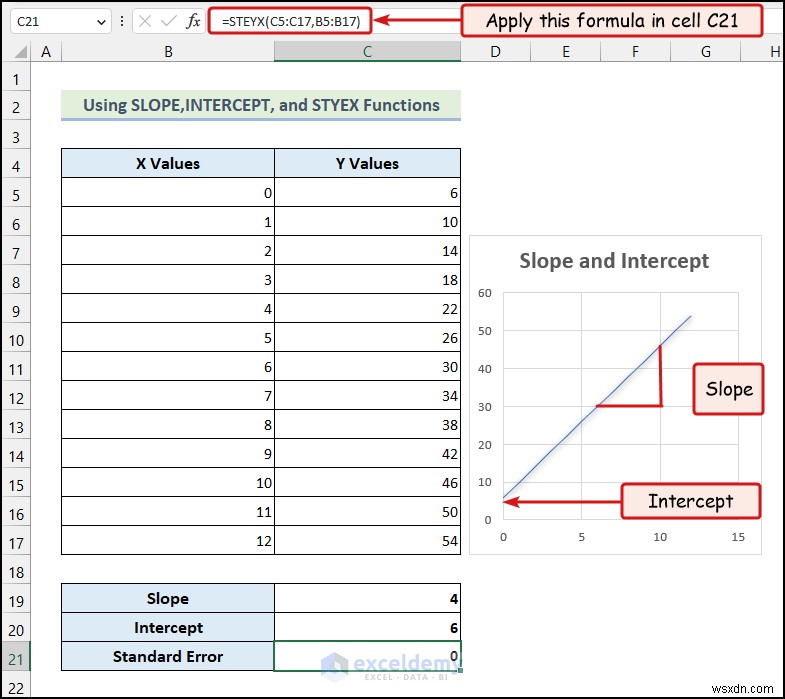 <पी> कदम :
<पी> कदम : - सेल C21: में नीचे दिया गया फॉर्मूला दर्ज करें
- ENTER दबाएँ .
3.2 कोरल फ़ंक्शन लागू करना
<पी>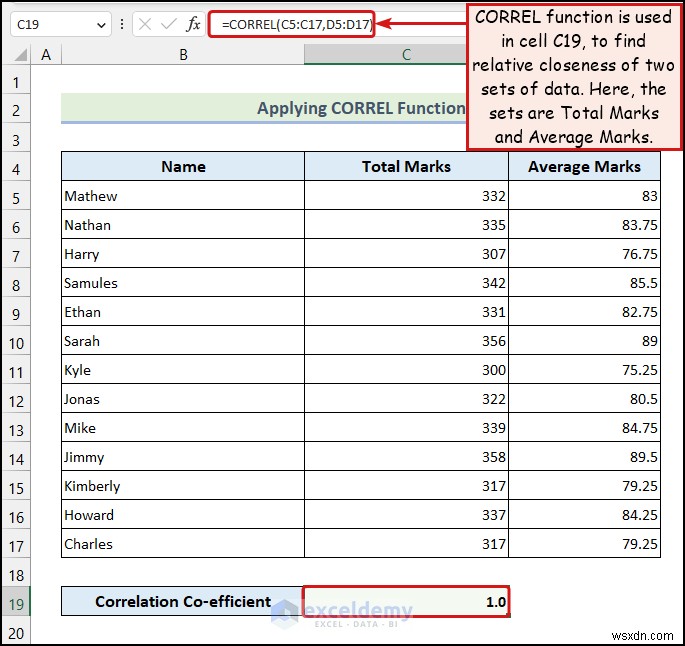 <पी> CORREL फ़ंक्शन हमें यह पता लगाने में मदद मिलती है कि डेटा के दो सेट कितने निकट से संबंधित हैं।
<पी> CORREL फ़ंक्शन हमें यह पता लगाने में मदद मिलती है कि डेटा के दो सेट कितने निकट से संबंधित हैं। - हमने C19 में निम्नलिखित सूत्र का उपयोग किया है सेल:
4. सांख्यिकीय विश्लेषण के लिए ऐरे फ़ंक्शंस लागू करना
<पी>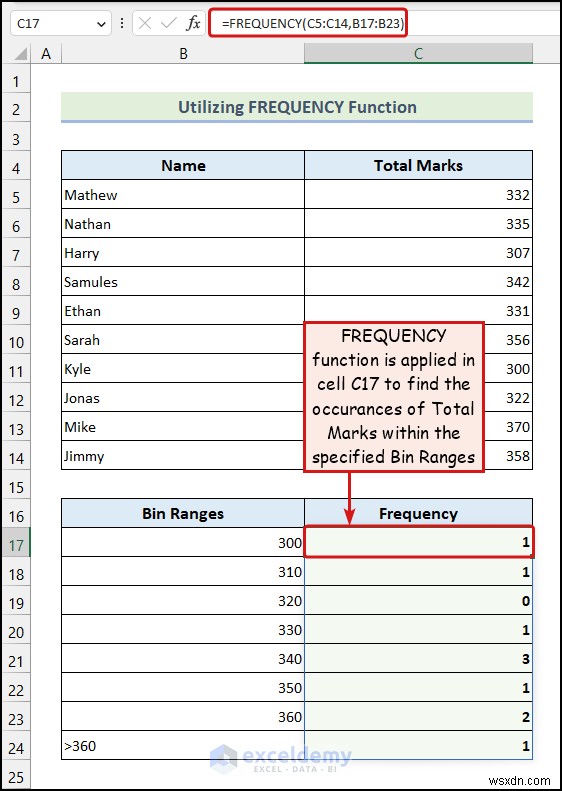 <पी> यहां, हमारे पास प्रत्येक बिन रेंज के विरुद्ध आवृत्तियां हैं जैसा कि निम्नलिखित चित्र में दिखाया गया है। हमने फ़्रीक्वेंसी फ़ंक्शन का उपयोग किया है , एक्सेल में डेटा का सांख्यिकीय रूप से विश्लेषण करने के लिए सबसे अधिक उपयोग किए जाने वाले ऐरे फ़ंक्शंस में से एक।
<पी> यहां, हमारे पास प्रत्येक बिन रेंज के विरुद्ध आवृत्तियां हैं जैसा कि निम्नलिखित चित्र में दिखाया गया है। हमने फ़्रीक्वेंसी फ़ंक्शन का उपयोग किया है , एक्सेल में डेटा का सांख्यिकीय रूप से विश्लेषण करने के लिए सबसे अधिक उपयोग किए जाने वाले ऐरे फ़ंक्शंस में से एक। - सेल C17 में निम्न सूत्र दर्ज करें :
=FREQUENCY(C5:C14,B17:B23) <पी> यहां, रेंज B17:B23 है प्रथमसातका प्रतिनिधित्व करता है बिन रेंज की कोशिकाएँ स्तंभ.
<पी> आप MODE.MULT फ़ंक्शन का उपयोग कर सकते हैं , LINEST फ़ंक्शन , ट्रेंड फ़ंक्शन , और ग्रोथ फ़ंक्शन एक्सेल में डेटा का सांख्यिकीय विश्लेषण करने के लिए। <पी> नोट: यदि आप Excel के पुराने संस्करण का उपयोग कर रहे हैं, तो आपको CTRL + SHIFT + ENTER दबाने की आवश्यकता हो सकती है सरणी सूत्रों का उपयोग करने के लिए. जैसा कि हम एक्सेल 365 का उपयोग करते हैं, बस ENTER दबाते हैं हमारे लिए करेंगे.
विधि 5 - मूविंग औसत की गणना करने के लिए डेटा विश्लेषण टूलपैक का उपयोग
<पी>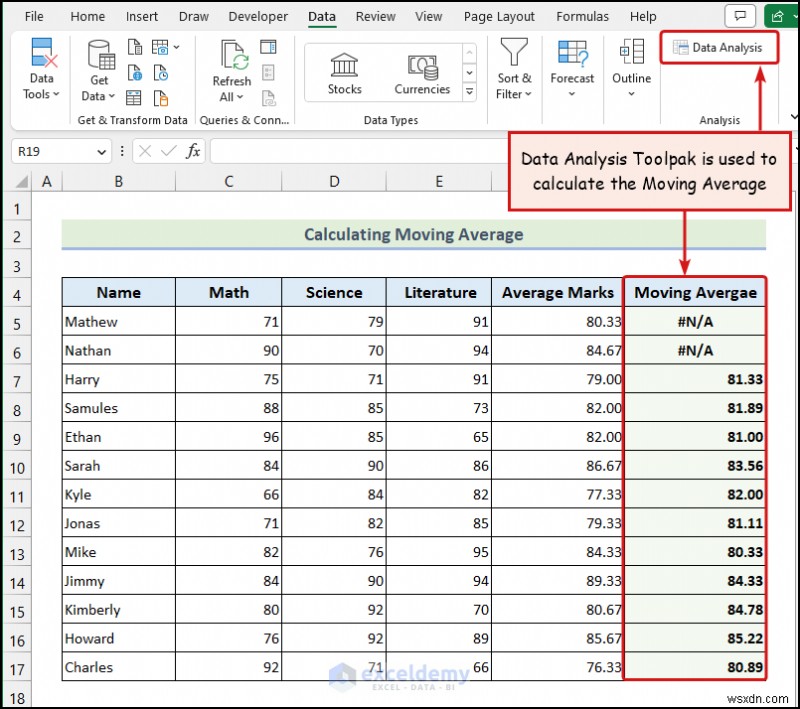 <पी> उपरोक्त छवि मूविंग एवरेज का प्रतिनिधित्व करती है हमारे डेटासेट का। डेटा विश्लेषण टूलपैक विकल्प Excel रिबन में नहीं है डिफ़ॉल्ट रूप से. आपको इस सुविधा को मैन्युअल रूप से सक्रिय करना होगा. आप डेटा विश्लेषण टूलपैक को सक्रिय करने और इसके विभिन्न उपयोगों के बारे में जानने के लिए इस लेख का अनुसरण कर सकते हैं . <पी>
<पी> उपरोक्त छवि मूविंग एवरेज का प्रतिनिधित्व करती है हमारे डेटासेट का। डेटा विश्लेषण टूलपैक विकल्प Excel रिबन में नहीं है डिफ़ॉल्ट रूप से. आपको इस सुविधा को मैन्युअल रूप से सक्रिय करना होगा. आप डेटा विश्लेषण टूलपैक को सक्रिय करने और इसके विभिन्न उपयोगों के बारे में जानने के लिए इस लेख का अनुसरण कर सकते हैं . <पी> 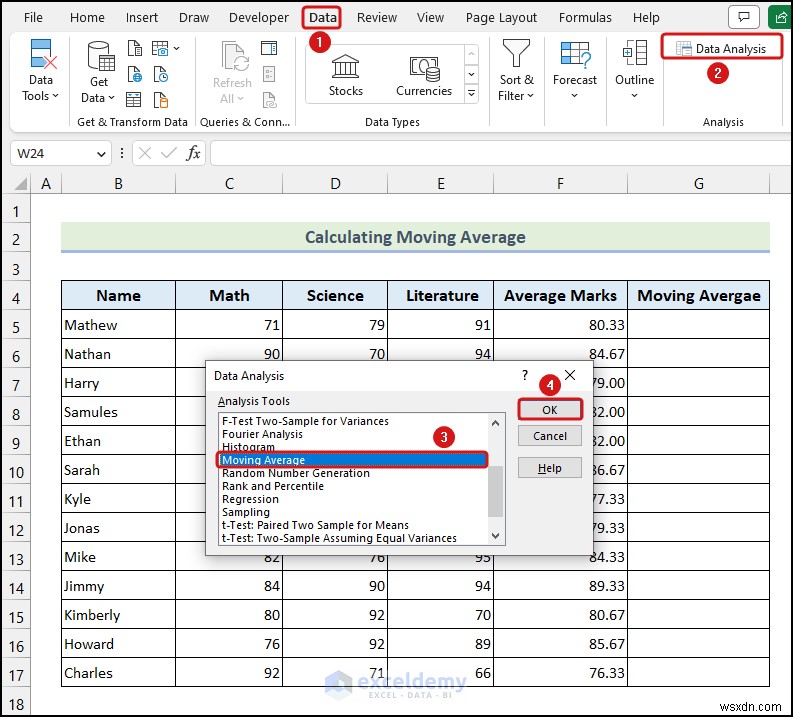
- डेटा पर जाएं रिबन से टैब>>डेटा विश्लेषण चुनें विश्लेषण से विकल्प समूह.
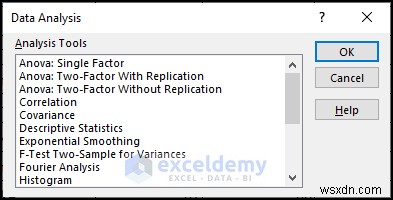
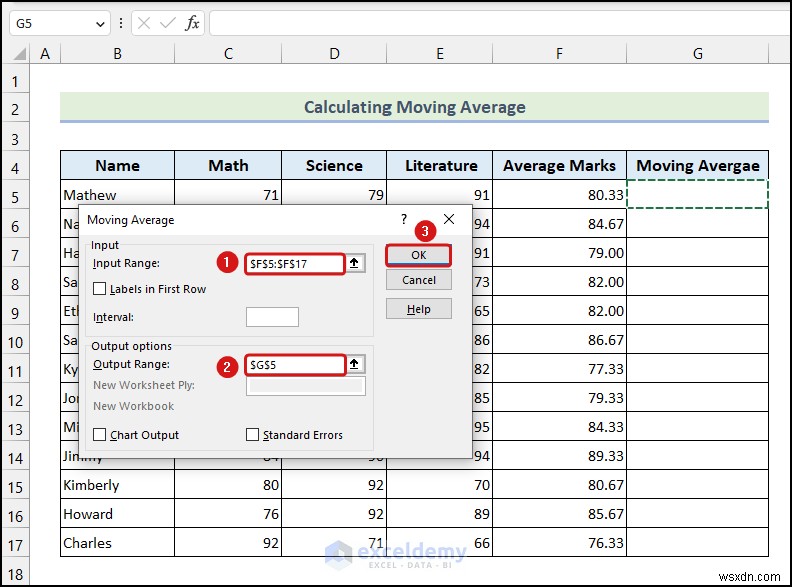 <पी> डेटा विश्लेषण डायलॉग बॉक्स आपकी वर्कशीट पर दिखाई देगा, जैसा कि ऊपर की छवि में दिखाया गया है।
<पी> डेटा विश्लेषण डायलॉग बॉक्स आपकी वर्कशीट पर दिखाई देगा, जैसा कि ऊपर की छवि में दिखाया गया है। - इनपुट रेंज पर जाएं औसत अंक की कोशिकाओं का चयन करने के लिए फ़ील्ड कॉलम>> आउटपुट रेंज पर क्लिक करें फ़ील्ड और सेल G5 चुनें>>ठीकपर क्लिक करें .
एक्सेल में कुछ सामान्य डेटा विश्लेषण उपकरण
- अनोवा:एकल कारक → यह दो या दो से अधिक अवलोकनों के लिए विचरण का विश्लेषण करता है।
- एनोवा:प्रतिकृति के साथ दो कारक → चर के स्तरों के प्रत्येक संयोजन के लिए, यह दो स्वतंत्र चर और विभिन्न अवलोकनों के साथ भिन्नता का विश्लेषण बनाता है।
- एनोवा:प्रतिकृति के बिना दो कारक → चर के स्तरों के प्रत्येक संयोजन के लिए, यह दो स्वतंत्र चर और एक एकल अवलोकन के साथ भिन्नता का विश्लेषण बनाता है।
- सहसंबंध → जब लोगों के नमूने पर दो से अधिक माप होते हैं, तो माप की प्रत्येक संभावित जोड़ी के लिए सहसंबंध गुणांक के एक मैट्रिक्स की गणना की जाती है।
- सहप्रसरण → जब लोगों के नमूने पर दो से अधिक माप होते हैं, तो माप के प्रत्येक संभावित जोड़े के लिए सहप्रसरण गुणांक के एक मैट्रिक्स की गणना की जाती है।
- वर्णनात्मक सांख्यिकी → यह कोशिकाओं की एक परिभाषित सीमा के भीतर केंद्रीय प्रवृत्ति, परिवर्तनशीलता और मूल्यों के अन्य गुणों का सारांश देते हुए एक रिपोर्ट तैयार करता है।
- एक्सपोनेंशियल स्मूथिंग → यह पिछले मूल्यों और पिछली भविष्यवाणियों के अनुक्रम का उपयोग करके अनुक्रम के अगले मूल्य की भविष्यवाणी करता है।
- विभिन्नताओं के लिए एफ-टेस्ट दो-नमूना → यह एफ-टेस्ट करके दो भिन्नताओं की तुलना करता है।
- हिस्टोग्राम → यह चयनित सेल रेंज के भीतर मूल्यों के आवृत्ति वितरण का एक सारणीबद्ध चित्रण बनाता है।
- यादृच्छिक संख्या सृजन → सात संभावित वितरणों में से एक के आधार पर, यादृच्छिक संख्याओं की एक विशिष्ट मात्रा उत्पन्न करता है।
- रैंक और प्रतिशत → यह एक तालिका बनाता है जो प्रत्येक मान को उसके क्रमसूचक और प्रतिशतक रैंक के साथ मूल्यों के एक सेट में प्रदर्शित करता है।
- प्रतिगमन → यह डेटा के एक सेट पर लागू रैखिक प्रतिगमन आंकड़ों की एक रिपोर्ट बनाता है जिसमें एक आश्रित चर और एक या अधिक स्वतंत्र चर शामिल होते हैं।
- नमूना → यह निर्दिष्ट सीमा में कोशिकाओं से मूल्यों का एक नमूना उत्पन्न करता है।
याद रखने योग्य बातें
- एक्सेल में कोई भी डेटा विश्लेषण करने से पहले, आपको अपने डेटा प्रकार के बारे में स्पष्ट होना चाहिए, जैसे, निरंतर या श्रेणीबद्ध।
- इसके बाद, आपको टी-टेस्ट, एनोवा, रिग्रेशन और सहसंबंध जैसे सांख्यिकीय विश्लेषण उपकरणों की समृद्ध सूची में से चयन करना होगा।
- एक बार जब आप अपना विश्लेषण कर लें, तो अपने परिणामों की सार्थक व्याख्या करना महत्वपूर्ण है। इसका मतलब यह समझना है कि संख्याओं का क्या मतलब है और वे आपके शोध प्रश्न से कैसे संबंधित हैं।
- अंत में, त्रुटियों की जांच करके अपने परिणामों को मान्य करना और यह सुनिश्चित करना महत्वपूर्ण है कि आपका विश्लेषण मजबूत है। इसमें आउटलेर्स की जांच करना, धारणाओं का परीक्षण करना और संवेदनशीलता विश्लेषण करना शामिल है।
अभ्यास अनुभाग
<पी> एक्सेल वर्कबुक में , हमने एक अभ्यास अनुभाग प्रदान किया है वर्कशीट के दाईं ओर। <पी> अभ्यास कार्यपुस्तिका के प्रत्येक कार्यपत्रक में एक नमूना अभ्यास अनुभाग प्रदान किया गया है। <पी> <पी> अभ्यास कार्यपुस्तिका डाउनलोड करें <पी> निम्नलिखित कार्यपुस्तिका डाउनलोड करें और अभ्यास करें। समाधान के साथ निःशुल्क उन्नत एक्सेल अभ्यास प्राप्त करें!
<पी> अभ्यास कार्यपुस्तिका डाउनलोड करें <पी> निम्नलिखित कार्यपुस्तिका डाउनलोड करें और अभ्यास करें। समाधान के साथ निःशुल्क उन्नत एक्सेल अभ्यास प्राप्त करें!