मूल रूप से 17 जून, 2020 को Onica.com/blog पर प्रकाशित हुआ
उद्योगों के ढेर सारे संगठन संचालन और सफलता के लिए महत्वपूर्ण अन्य कार्यों के लिए डेटा एनालिटिक्स का उपयोग करना चाहते हैं। हालांकि, जैसे-जैसे डेटा की मात्रा बढ़ती है, प्रबंधन और मूल्य-निष्कर्षण तेजी से जटिल होते जा सकते हैं।
अमेज़ॅन रेडशिफ्ट
Amazon® Redshift® Amazon Web Services® (AWS) की एक शक्तिशाली डेटा वेयरहाउस सेवा है जो डेटा प्रबंधन और विश्लेषण को सरल बनाती है। आइए Amazon Redshift पर एक नज़र डालें और डेटा क्वेरी प्रदर्शन को अनुकूलित करने के लिए आप कुछ सर्वोत्तम अभ्यासों को लागू कर सकते हैं।
डेटा लेक बनाम डेटा वेयरहाउस
Amazon Redshift में खुदाई करने से पहले, डेटा झीलों और गोदामों के बीच के अंतरों को जानना महत्वपूर्ण है। अमेज़ॅन एस 3 की तरह एक डेटा लेक, एक केंद्रीकृत डेटा रिपोजिटरी है जो डेटा को बदलने के बिना किसी भी पैमाने पर और कई स्रोतों से संरचित और असंरचित डेटा संग्रहीत करता है। दूसरी तरफ, डेटा वेयरहाउस डेटा को एक समेकित राज्य में स्टोर करते हैं जो चल रहे विश्लेषण करने के लिए अनुकूलित होता है और विश्लेषण के लिए आवश्यक डेटा केवल डेटा झीलों से लोड करें।
Amazon Redshift डेटा एनालिटिक्स के लिए स्टोरेज को एक स्तर आगे ले जाता है, डेटा लेक और वेयरहाउस के गुणों को "लेक हाउस" दृष्टिकोण में मिलाता है। यह लागत प्रभावी रहते हुए बड़ी एक्साबाइट-स्केल डेटा झीलों की क्वेरी करने की अनुमति देता है, डेटा अतिरेक को कम करता है, और रखरखाव ओवरहेड और परिचालन लागत को कम करता है।
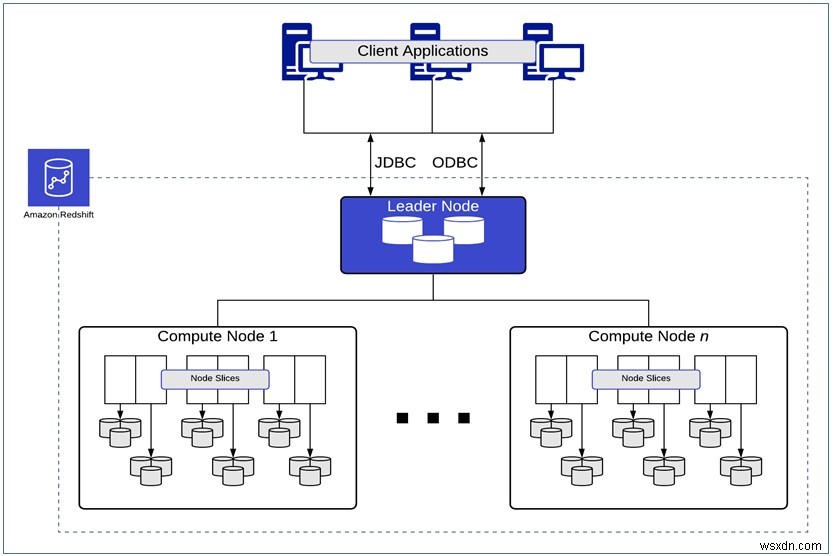
अमेज़ॅन रेडशिफ्ट आर्किटेक्चर
बड़े डेटा सेट पर जटिल प्रश्नों को तेजी से संसाधित करने के लिए, अमेज़ॅन रेडशिफ्ट आर्किटेक्चर बड़े पैमाने पर समानांतर प्रसंस्करण (एमपीपी) का समर्थन करता है जो समवर्ती प्रसंस्करण के लिए कई कंप्यूट नोड्स में नौकरी वितरित करता है।
इन नोड्स को समूहों में बांटा गया है, और प्रत्येक क्लस्टर में तीन प्रकार के नोड होते हैं:
-
लीडर नोड :ये कनेक्शन प्रबंधित करते हैं, SQL समापन बिंदु के रूप में कार्य करते हैं, और समानांतर SQL संसाधन का समन्वय करते हैं।
-
गणना नोड्स :स्लाइस . से बना है , ये एक स्तंभ प्रारूप में और 1 एमबी अपरिवर्तनीय ब्लॉकों में संग्रहीत डेटा पर समानांतर में क्वेरी निष्पादित करते हैं। Amazon Redshift क्लस्टर में 1 से 128 कंप्यूट नोड्स हो सकते हैं, जिन्हें स्लाइस में विभाजित किया जाता है जिसमें टेबल डेटा होता है और स्थानीय प्रोसेसिंग ज़ोन के रूप में कार्य करता है।
-
अमेज़ॅन रेडशिफ्ट स्पेक्ट्रम नोड्स :ये Amazon S3 डेटा लेक के विरुद्ध क्वेरी निष्पादित करते हैं।
क्वेरी प्रदर्शन को ऑप्टिमाइज़ करना
क्लस्टर में डेटा के भौतिक लेआउट को अपने क्वेरी पैटर्न के अनुरूप लाकर, आप इष्टतम क्वेरीिंग प्रदर्शन निकाल सकते हैं। यदि Amazon Redshift बेहतर प्रदर्शन नहीं कर रहा है, तो कार्यभार प्रबंधन को पुन:कॉन्फ़िगर करने पर विचार करें।
कार्यभार प्रबंधन (WLM) को फिर से कॉन्फ़िगर करें
अक्सर इसकी डिफ़ॉल्ट सेटिंग में छोड़ दिया जाता है, WLM को ट्यून करने से प्रदर्शन में सुधार हो सकता है। आप इस कार्य को स्वचालित कर सकते हैं या इसे मैन्युअल रूप से कर सकते हैं। स्वचालित होने पर, Amazon Redshift क्लस्टर-संसाधन उपयोग के आधार पर मेमोरी उपयोग और समवर्ती का प्रबंधन करता है। यह आपको आठ प्राथमिकता-निर्दिष्ट क्यू सेट करने की अनुमति देता है। जब मैन्युअल रूप से किया जाता है, तो आप समवर्ती प्रश्नों की संख्या, स्मृति आवंटन और लक्ष्यों को समायोजित कर सकते हैं।
आप निम्न WLM कॉन्फ़िगरेशन पैरामीटर के माध्यम से क्वेरी प्रदर्शन को अनुकूलित भी कर सकते हैं:
-
क्वेरी मॉनिटरिंग नियम आपको महंगी या भगोड़ा क्वेरी प्रबंधित करने में मदद करते हैं।
-
लघु क्वेरी त्वरण क्वेरी निष्पादन समय की भविष्यवाणी करने के लिए मशीन लर्निंग एल्गोरिदम का उपयोग करके लंबे समय तक चलने वाली क्वेरी पर शॉर्ट-रनिंग क्वेरी को प्राथमिकता देने में आपकी सहायता करता है।
-
समवर्ती स्केलिंग समवर्ती पठन प्रश्नों को गति देने के लिए आपको सेकंड में कई क्षणिक क्लस्टर जोड़ने में मदद करता है।
WLM सर्वोत्तम अभ्यास
कुछ WLM ट्यूनिंग सर्वोत्तम प्रथाओं में शामिल हैं:
- विभिन्न प्रकार के वर्कलोड के लिए अलग-अलग WLM क्वेरी बनाना।
- मुख्य क्लस्टर के लिए अधिकतम कुल संगामिति को अधिकतम थ्रूपुट के लिए 15 या उससे कम तक सीमित करना।
- समवर्ती स्केलिंग सक्षम करना।
- कतार में संसाधनों की संख्या को कम करना।
डेटा वितरण परिशोधित करना
निम्नलिखित वितरण शैलियों के आधार पर, तालिका की पंक्तियों को AmazonRedshift द्वारा नोड स्लाइस में स्वचालित रूप से वितरित किया जाता है:
AUTO:ALL से शुरू होता है और टेबल के बढ़ने पर EVEN पर स्विच हो जाता है।ALL:प्रत्येक कंप्यूट नोड के पहले स्लाइस पर रखी गई छोटी, बार-बार जुड़ने वाली, और बार-बार संशोधित तालिकाओं से मिलकर बनता है।EVEN:बड़े, स्टैंडअलोन फैक्ट टेबल से मिलकर बनता है जो स्लाइस में राउंड-रॉबिन वितरण में अक्सर शामिल या एकत्रित नहीं होते हैं।KEY:बार-बार जुड़ने वाली तथ्य तालिका या बड़ी आयाम तालिकाएँ शामिल होती हैं। इस शैली में, एक स्तंभ मान हैश किया जाता है, और उसी हैश मान को उसी स्लाइस पर रखा जाता है।
सही वितरण पैटर्न का उपयोग JOIN के प्रदर्शन को अधिकतम कर सकता है , GROUP BY , और INSERT INTO SELECT संचालन।
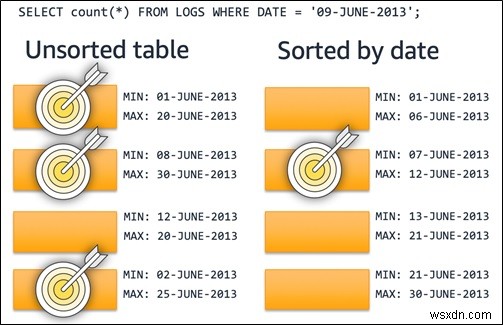
डेटा सॉर्टिंग परिशोधित करना
सॉर्ट कुंजियाँ डिस्क पर डेटा के भौतिक क्रम को परिभाषित करती हैं। WHERE . में उपयोग किए जाने वाले तालिका कॉलम क्लॉज प्रेडिकेट्स सॉर्ट कीज़ के लिए एक अच्छा विकल्प है और आमतौर पर दिनांक या समय से संबंधित कॉलम का उपयोग करते हैं। डेटा के प्रत्येक ब्लॉक के लिए वैल्यू एक्सट्रीम को परिभाषित करने के लिए मेमोरी में संग्रहीत और स्वचालित रूप से जेनरेट किए गए ज़ोन मैप्स का उपयोग करें। प्रभावी ढंग से सॉर्ट कीज़ और ज़ोन मैप्स का एक साथ उपयोग करने से आपको मदद मिल सकती है स्कैन को ब्लॉक की न्यूनतम आवश्यक संख्या तक सीमित रखें।
निम्न आरेख दिखाता है कि कैसे तालिका छँटाई समय-आधारित प्रश्नों के लिए लक्ष्यों को स्कैन करने पर केंद्रित है, जिससे क्वेरी प्रदर्शन में सुधार होता है।
सर्वोत्तम क्वेरी प्रदर्शन सर्वोत्तम अभ्यास
पहले बताए गए Amazon Redshift परिवर्तनों का उपयोग करने से क्वेरी प्रदर्शन में सुधार हो सकता है और लागत और संसाधन दक्षता में सुधार हो सकता है। यहां कुछ और सर्वोत्तम अभ्यास दिए गए हैं जिन्हें आप आगे के प्रदर्शन में सुधार के लिए लागू कर सकते हैं:
SORTका उपयोग करें कॉलम पर कुंजियाँ जो अक्सरWHERE. में उपयोग की जाती हैं क्लॉज फिल्टर।DISTKEYका उपयोग करें उन स्तंभों पर जिनका उपयोग अक्सरJOIN. में किया जाता है भविष्यवाणी करता है।- पहले सॉर्ट-कुंजी कॉलम को छोड़कर सभी स्तंभों को संपीड़ित करें।
- डेटा झील में डेटा का विभाजन क्वेरी फ़िल्टर जैसे पहुंच पैटर्न . के आधार पर किया जाता है ।
कुछ और सर्वोत्तम प्रथाओं का पता लगाने के लिए, अमेज़ॅन रेडशिफ्ट परिवर्तनों में गहराई से गोता लगाएँ, और गहन क्वेरी विश्लेषण का एक उदाहरण देखें, AWS पार्टनर नेटवर्क (APN) ब्लॉग पढ़ें।
यदि आप एक डेटा यात्रा शुरू कर रहे हैं और अपने डेटा प्लेटफ़ॉर्म को तेज़ी से, मज़बूती से और लागत प्रभावी ढंग से विकसित करने के लिए AWS सेवाओं का लाभ उठाना चाहते हैं, तो आज ही हमारी डेटा इंजीनियरिंग और एनालिटिक्स टीम से संपर्क करें।
ओनिका सेवाओं के बारे में अधिक जानें।
कोई टिप्पणी करने या प्रश्न पूछने के लिए प्रतिक्रिया टैब का उपयोग करें। आप विक्रय चैट . पर भी क्लिक कर सकते हैं अभी चैट करने और बातचीत शुरू करने के लिए।