सामान्य कमियाँ जिनके कारण RAG सिस्टम उत्पादन में विफल हो जाते हैं
<पी> पुनर्प्राप्ति-संवर्धित पीढ़ी को बाहरी ज्ञान के साथ बड़े भाषा मॉडल को बढ़ाने के लिए माना जाता है। यह डेमो में खूबसूरती से काम कर सकता है:एक छोटा क्यूरेटेड डेटासेट, साफ-सुथरी क्वेरीज़ और एक अप्रतिबंधित विलंबता बजट से ज्ञानवर्धक, जमीनी जवाब मिलते हैं जो उपयोगकर्ताओं को सही लगते हैं। हालाँकि, कई टीमों को लगता है कि एक बार जब वे अपने RAG एप्लिकेशन को उपयोगकर्ताओं के लिए तैनात कर देते हैं, तो प्रदर्शन ख़राब हो जाता है। क्वेरीज़ अस्पष्ट हो जाती हैं, कॉर्पस का विस्तार होता है, पुनर्प्राप्ति गुणवत्ता गिरती है, विलंबता गुब्बारे, और सिस्टम चुपचाप सटीकता में फीकी पड़ने लगती है। इससे भी बदतर, खराब मूल्यांकन तकनीकें छिप जाती हैं जहां सिस्टम वास्तव में विफल होना शुरू हो जाता है जब तक कि उपयोगकर्ता शिकायत नहीं करते। यह आलेख उन कारणों का पता लगाता है कि क्यों कई RAG प्रणालियाँ उत्पादन में विफल हो जाती हैं। हम हालिया शोध और उद्योग दिशानिर्देशों से प्रेरणा लेते हैं। हम विफलता मोड की श्रृंखला में लिंक के रूप में पुनर्प्राप्ति गुणवत्ता, विलंबता ट्रेड-ऑफ, एम्बेडिंग बहाव और मूल्यांकन अंतराल के मुद्दों को फ्रेम करते हैं। एक मजबूत उत्पादन आरएजी प्रणाली बनाने के लिए इस श्रृंखला के प्रत्येक लिंक को ध्यान में रखा जाना चाहिए। मुख्य बातें
- अधिकांश RAG विफलताएं पुनर्प्राप्ति में शुरू होती हैं, पीढ़ी में नहीं। जब सिस्टम अधूरे, अप्रासंगिक, या खराब रैंक वाले साक्ष्य को पुनः प्राप्त करता है, तो एक मजबूत एलएलएम भी कमजोर उत्तर देगा।
- बेहतर पुनर्प्राप्ति के लिए बेहतर इंजीनियरिंग विकल्पों की आवश्यकता होती है। प्रासंगिकता में सुधार और मौन पुनर्प्राप्ति विफलताओं को कम करने के लिए डोमेन-जागरूक चंकिंग, हाइब्रिड पुनर्प्राप्ति और पुनर्रैंकिंग को मुख्य तकनीकों के रूप में प्रस्तुत किया जाता है।
- विलंबता शीघ्र ही उत्पादन में बाधा बन जाती है। बड़े टॉप_के, रीरैंकर्स, लंबे संदर्भ और अतिरिक्त पुनर्प्राप्ति चरणों को जोड़ने से रिकॉल में सुधार हो सकता है, लेकिन यह वास्तविक उपयोगकर्ताओं के लिए सिस्टम को बहुत धीमा भी कर सकता है।
- एम्बेडिंग ड्रिफ्ट चुपचाप समय के साथ प्रदर्शन को ख़राब कर देता है। एम्बेडिंग मॉडल, दस्तावेज़ संग्रह और उपयोगकर्ता शब्दावली में परिवर्तन सभी पुनर्प्राप्ति व्यवहार को बदल सकते हैं, इसलिए संस्करण और अवलोकन आवश्यक हैं।
- केवल अंतिम उत्तर की गुणवत्ता ही मूल्यांकन के लिए पर्याप्त नहीं है। टीमों को अलग-अलग पुनर्प्राप्ति और जेनरेशन मेट्रिक्स, यथार्थवादी परीक्षण सेट, निरंतर निगरानी और सबूत कमजोर या गायब होने पर सिस्टम से दूर रहने की क्षमता की आवश्यकता होती है।
खराब पुनर्प्राप्ति गुणवत्ता के कारण विफलता
<पी> उत्पादन में तैनात किए जाने पर कम पुनर्प्राप्ति गुणवत्ता आरएजी सिस्टम की विफलता के सबसे लगातार कारणों में से एक है। डेवलपर्स अक्सर गलत/खराब उत्तरों के लिए एलएलएम को दोषी ठहराते हैं; हालाँकि, खराबी आमतौर पर पाइपलाइन में पहले होती है। यदि सिस्टम पूर्ण या प्रासंगिक साक्ष्य पुनर्प्राप्त नहीं कर सकता है, या साक्ष्य को खराब तरीके से रैंक करता है, तो सबसे अच्छे मॉडल से भी भरोसेमंद प्रतिक्रिया उत्पन्न होने की संभावना नहीं है। पुनर्प्राप्ति गुणवत्ता को पृष्ठभूमि कदम के बजाय प्रथम श्रेणी इंजीनियरिंग चिंता के रूप में माना जाना चाहिए। अधिकांश विफलताएं एलएलएम द्वारा क्वेरी देखे जाने से पहले होती हैं
<पी> मानक पाइपलाइन उपयोगकर्ता क्वेरी को एम्बेड करती है, एक वेक्टर स्टोर से शीर्ष‑k दस्तावेज़ पुनर्प्राप्त करती है, और उन्हें एलएलएम को भेजती है। उस पाइपलाइन में प्रत्येक तीर विफलता का एक संभावित बिंदु है। <पी> 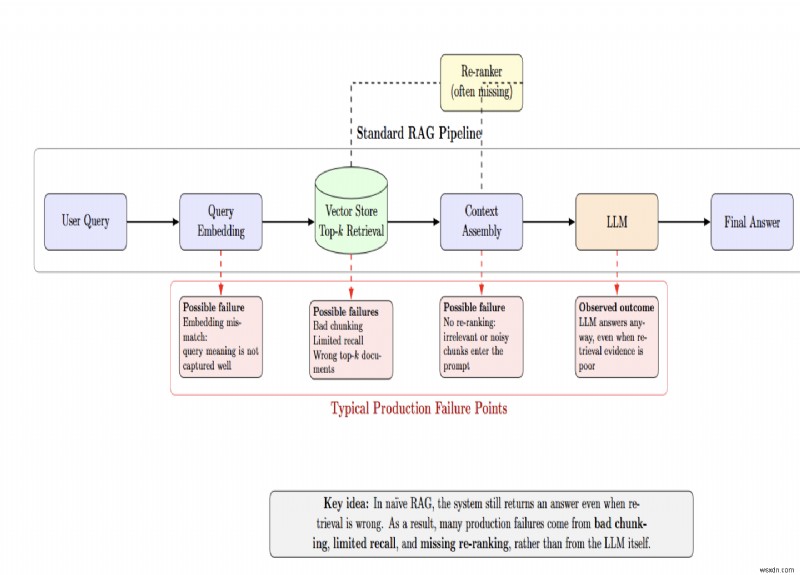 <पी> भोला आरएजी इन विफलताओं को अस्पष्ट कर देता है क्योंकि सिस्टम एक उत्तर प्रदान करता है भले ही पुनर्प्राप्ति गलत थी या नहीं। कई उत्पादन मुद्दे एलएलएम की कमियों के बजाय खराब चंकिंग रणनीतियों, सीमित रिकॉल और लापता री-रैंकिंग से उत्पन्न होते हैं।
<पी> भोला आरएजी इन विफलताओं को अस्पष्ट कर देता है क्योंकि सिस्टम एक उत्तर प्रदान करता है भले ही पुनर्प्राप्ति गलत थी या नहीं। कई उत्पादन मुद्दे एलएलएम की कमियों के बजाय खराब चंकिंग रणनीतियों, सीमित रिकॉल और लापता री-रैंकिंग से उत्पन्न होते हैं। गलतियाँ करने से मौन विफलताएँ उत्पन्न होती हैं
<पी> खंड का आकार सटीकता/रिकॉल को प्रभावित करता है - बड़े खंड कम प्रासंगिकता के साथ अधिक संदर्भ प्रदान करते हैं, जबकि छोटे खंड उच्च सटीकता प्रदान करते हैं लेकिन आसपास की जानकारी खो देते हैं। पदानुक्रमित (अभिभावक-बच्चा) खंडन पूरे अनुभागों को मूल खंड के रूप में संग्रहीत करके और केवल छोटे प्रासंगिक बच्चे खंड को पुनः प्राप्त करके इस व्यापार-बंद को हल करता है। <पी> 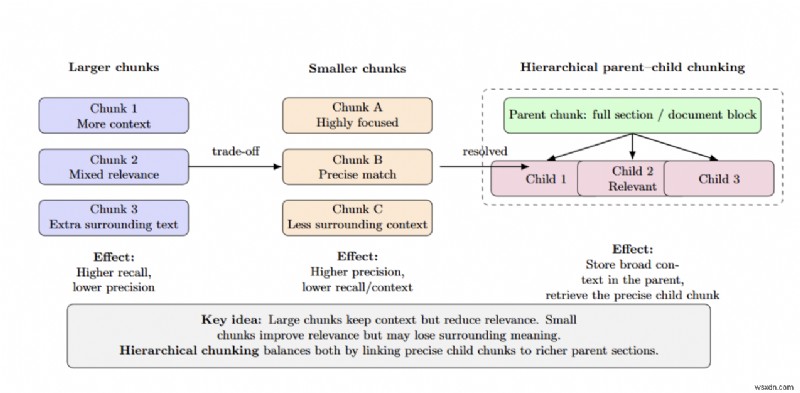 <पी> विश्वविद्यालय प्रेजेंटेशन डेक पर एनवीआईडीआईए के आंतरिक परीक्षण में पाया गया कि पदानुक्रमित चंकिंग निश्चित आकार के खंडों के साथ उत्तर सटीकता को 61% से बढ़ाकर 89% कर देता है। संरचनात्मक सीमाओं का सम्मान करते हुए और जहां संभव हो, डोमेन-जागरूक विभाजन को लागू करते हुए उचित टुकड़े का आकार चुनना महत्वपूर्ण है।
<पी> विश्वविद्यालय प्रेजेंटेशन डेक पर एनवीआईडीआईए के आंतरिक परीक्षण में पाया गया कि पदानुक्रमित चंकिंग निश्चित आकार के खंडों के साथ उत्तर सटीकता को 61% से बढ़ाकर 89% कर देता है। संरचनात्मक सीमाओं का सम्मान करते हुए और जहां संभव हो, डोमेन-जागरूक विभाजन को लागू करते हुए उचित टुकड़े का आकार चुनना महत्वपूर्ण है। हाइब्रिड पुनर्प्राप्ति और पुनः-रैंकिंग
<पी> शुद्ध सघन पुनर्प्राप्ति शब्दार्थ समानता में अच्छी है लेकिन सटीक पहचानकर्ताओं को याद करती है। शुद्ध कीवर्ड खोज सटीक शब्दों के प्रति संवेदनशील है, लेकिन अर्थ संबंधी व्याख्याओं में विफल रहती है। हाइब्रिड पुनर्प्राप्ति सिस्टम सघन (वेक्टर) पुनर्प्राप्ति और विरल (BM25/कीवर्ड) पुनर्प्राप्ति को एक साथ चलाते हैं, फिर उनके परिणामों को पारस्परिक रैंक फ़्यूज़न के साथ जोड़ते हैं। <पी> हाइब्रिड पुनर्प्राप्ति प्रणालियाँ शब्दार्थ समानता संकेतों को शाब्दिक मिलान संकेतों के साथ जोड़कर शब्दावली बेमेल को हल करती हैं। फ़्यूज़न के बाद उम्मीदवार जोड़ों को री-रैंकर (क्रॉस-एनकोडर) के साथ पुनः प्राप्त करने से स्मरण शक्ति में सुधार होता है। अनिवार्य रूप से, पुनर्रैंकर्स पुनर्प्राप्त दस्तावेज़ों को पुन:व्यवस्थित करते हैं ताकि केवल सबसे प्रासंगिक दस्तावेज़ ही इसे उस संदर्भ में बना सकें जिसकी एलएलएम समीक्षा करता है। यह टोकन सीमाएं बचाता है और एलएलएम रिकॉल में सुधार करते हुए संदर्भ भराई से बचाता है। पुनर्प्राप्ति मेट्रिक्स की निगरानी अलग से की जानी चाहिए
<पी> टीमें केवल शुरू से अंत तक उत्तर की गुणवत्ता मापती हैं। पुनर्प्राप्ति में स्वयं मेट्रिक्स हैं जिनका आप उपयोग कर सकते हैं:परिशुद्धता @ के (पुनर्प्राप्त खंडों का कौन सा अंश प्रासंगिक है?), रिकॉल @ के (प्रासंगिक खंडों का कौन सा अंश आपने पुनः प्राप्त किया?), औसत पारस्परिक रैंक (पहला प्रासंगिक खंड कितना ऊंचा था?), और सामान्यीकृत रियायती संचयी लाभ (आपकी समग्र रैंकिंग कितनी अच्छी है?)। <पी>  <पी> यदि आप इन्हें नहीं मापते हैं, तो आपको पता नहीं चलेगा कि विफलताएँ ख़राब पुनर्प्राप्ति या ख़राब जनरेटर के कारण हैं। परीक्षण क्वेरीज़ और सुनहरे डेटासेट आपको ऑफ़लाइन मूल्यांकन करने देंगे। यदि आप इन मेट्रिक्स को वास्तविक प्रश्नों पर ट्रैक करते हैं, तो आप उत्पादन प्रतिगमन को सामने ला सकते हैं।
<पी> यदि आप इन्हें नहीं मापते हैं, तो आपको पता नहीं चलेगा कि विफलताएँ ख़राब पुनर्प्राप्ति या ख़राब जनरेटर के कारण हैं। परीक्षण क्वेरीज़ और सुनहरे डेटासेट आपको ऑफ़लाइन मूल्यांकन करने देंगे। यदि आप इन मेट्रिक्स को वास्तविक प्रश्नों पर ट्रैक करते हैं, तो आप उत्पादन प्रतिगमन को सामने ला सकते हैं। उदाहरणों के साथ पुनर्प्राप्ति विफलता का निदान
<पी> अस्पष्ट प्रश्न और शब्दावली बेमेल अक्सर गलत पुनर्प्राप्ति का कारण बनते हैं। कोई उपयोगकर्ता "वेतन" खोज सकता है जबकि दस्तावेज़ "मुआवजा पैकेज" को संदर्भित करता है। सघन एम्बेडिंग पर्यायवाची को पहचानने में विफल हो सकती है, जबकि हाइब्रिड पुनर्प्राप्ति इसे ठीक करती है। एक अन्य मामला सटीक मिलान के लिए है, जैसे पहचानकर्ता। "SKU‑B4920" या "धारा 4.2.1" के लिए एक क्वेरी को सटीक शाब्दिक मिलान की आवश्यकता है। <पी> 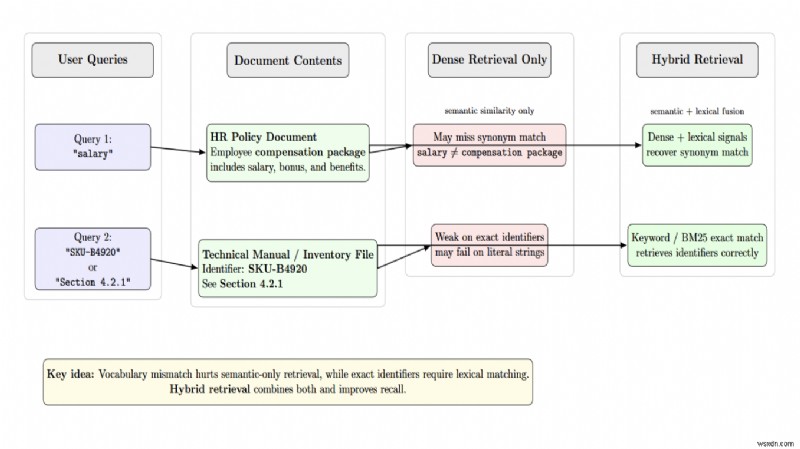 <पी> "बीच में खो जाना" तब होता है जब प्रासंगिक जानकारी एक लंबे दस्तावेज़ में गहराई से दबी होती है। एलएलएम बीच के हिस्सों में टोकन को कम महत्व देगा। <पी>
<पी> "बीच में खो जाना" तब होता है जब प्रासंगिक जानकारी एक लंबे दस्तावेज़ में गहराई से दबी होती है। एलएलएम बीच के हिस्सों में टोकन को कम महत्व देगा। <पी> 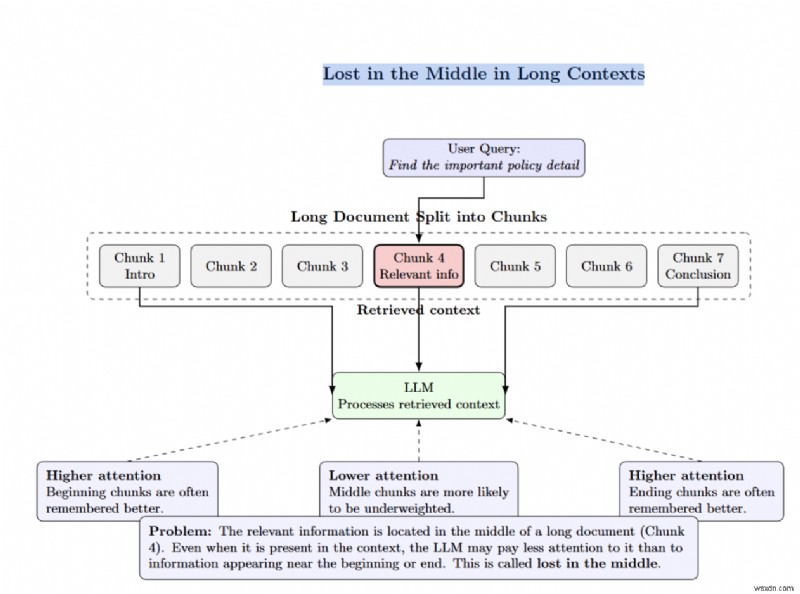 <पी> खंडित कलाकृतियाँ तब उत्पन्न होती हैं जब एक उत्तर को दो भागों में विभाजित किया जाता है, इसलिए किसी भी खंड में पूरा उत्तर नहीं होता है। पदानुक्रमित चंकिंग माता-पिता और बच्चे के नोड्स को जोड़कर इसे कम करने में मदद करती है। <पी>
<पी> खंडित कलाकृतियाँ तब उत्पन्न होती हैं जब एक उत्तर को दो भागों में विभाजित किया जाता है, इसलिए किसी भी खंड में पूरा उत्तर नहीं होता है। पदानुक्रमित चंकिंग माता-पिता और बच्चे के नोड्स को जोड़कर इसे कम करने में मदद करती है। <पी> 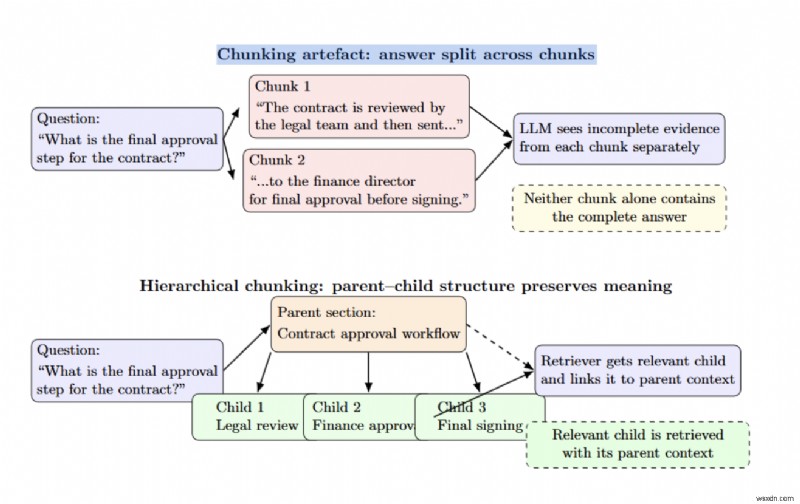
वास्तविक सिस्टम में विलंबता विस्फोट के कारण विफलता
<पी> विलंबता एक मुख्य कारण है कि आरएजी प्रणाली जो डेमो में काम करती है, उत्पादन में संघर्ष करती है। जैसे-जैसे पुनर्प्राप्ति पाइपलाइनें अधिक परिष्कृत होती जाती हैं, प्रतिक्रिया समय तेज़ी से बढ़ सकता है और टीमों को प्रयोज्यता के विरुद्ध उत्तर गुणवत्ता का व्यापार करने के लिए बाध्य किया जा सकता है। पुनर्प्राप्ति-विलंबता व्यापार-बंद
<पी> उत्पादन टीमों को अक्सर पुनर्प्राप्ति गुणवत्ता और उनके विलंबता बजट को संतुलित करना होगा। वह सब कुछ जो प्रतिक्रिया समय बढ़ाता है (top_k के साथ बड़ा होना, हाइब्रिड पुनर्प्राप्ति जोड़ना, पुनर्रैंकिंग करना, या लंबे-संदर्भ मॉडल चलाना) उन बजटों में कटौती करता है। व्यापार-बंद विशेष रूप से कठिन है क्योंकि उपयोगकर्ता प्रतिक्रियाशील उत्तरों की अपेक्षा करते हैं, और उद्यम एकीकरण कठोर विलंबता बजट के साथ आते हैं। हालाँकि, जैसा कि कॉर्नेल और NVIDIA के हालिया काम से पता चलता है, RAG को महत्वपूर्ण विलंबता ओवरहेड का सामना करना पड़ता है। पुनर्प्राप्ति को बहुत बार चलाने से सटीकता बढ़ सकती है, लेकिन अंत-से-अंत विलंबता लगभग 30 सेकंड तक बढ़ जाती है - जो उत्पादन उपयोग के लिए बहुत अधिक है। पीढ़ी आमतौर पर हावी होती है, लेकिन पुनर्प्राप्ति मायने रखती है
<पी> RAGPerf के साथ बेंचमार्किंग से पता चलता है कि पीढ़ी अक्सर टेक्स्ट-केवल RAG पाइपलाइनों का प्रमुख हिस्सा होती है . यदि पुनर्प्राप्ति गुणवत्ता बनाए रखी जाती है, तो एक छोटा एलएलएम चुनने से उत्तर गुणवत्ता का त्याग किए बिना विलंबता को काफी कम किया जा सकता है। मल्टीमॉडल पाइपलाइनों (पीडीएफ और छवि पुनर्प्राप्ति) में रीरैंकिंग और संबंधित क्रॉस-मोडल मॉडल के कारण बड़ी गणना मांगें होती हैं। जब वेक्टर डेटाबेस धीमे होते हैं या समवर्ती लुकअप की अनुमति नहीं देते हैं तो पुनर्प्राप्ति विलंबता बढ़ सकती है। हालाँकि, तेज़ लुकअप के साथ भी, कई RAG कार्यभार के लिए पुनर्रैंकिंग कुल विलंबता पर हावी हो सकती है। विलंबता, लागत और संदर्भ विंडो
<पी> कुछ टीमें टॉप_के को बढ़ाकर या एलएलएम के संदर्भ में अधिक दस्तावेजों को जमा करके रिकॉल को हल करने का प्रयास करती हैं। अध्ययनों से पता चलता है कि इसका विपरीत प्रभाव पड़ता है। आप प्रॉम्प्ट में जितने अधिक दस्तावेज़ जोड़ेंगे, एलएलएम सही जानकारी याद रखने में उतना ही कम सक्षम होगा। पुनर्प्राप्ति पुनर्रैंकिंग कई दस्तावेज़ों को पुनः प्राप्त करके, फिर एलएलएम के लिए केवल सर्वोत्तम दस्तावेज़ों का चयन करके इसका समाधान करती है। लंबी संदर्भ विंडो "बीच में खो जाने" और खगोलीय कम्प्यूटेशनल लागत का कारण बनती हैं। विलंबता का अनुकूलन
<पी> RAG सिस्टम में विलंबता को संबोधित करने के लिए संपूर्ण पाइपलाइन में जानबूझकर ऑर्केस्ट्रेशन की आवश्यकता होती है: फोकस क्षेत्र | क्या करें | यह क्यों मायने रखता है | पुनर्प्राप्ति गुणवत्ता डिफ़ॉल्ट निश्चित विंडो के बजाय डोमेन-जागरूक चंकिंग का उपयोग करें। जहां यह मायने रखता है वहां दस्तावेज़ संरचना को सुरक्षित रखें। सघन और शाब्दिक पुनर्प्राप्ति को मिलाएं। पुनःरैंकिंग जोड़ें. मेटाडेटा का बुद्धिमानी से उपयोग करें। कवरेज और प्रासंगिकता में सुधार करता है, और सिस्टम को उस संदर्भ को पुनः प्राप्त करने में मदद करता है जो जमीनी उत्तरों के लिए अधिक उपयोगी है। विलंबता नियंत्रण हर चरण को मापें। उन कदमों को हटा दें जिनसे सार्थक लाभ न हो। पाइपलाइन को उतना सरल रखें जितना उपयोग का मामला अनुमति देता है। वास्तविक इंटरेक्शन पैटर्न के लिए निर्माण करें। अनावश्यक ओवरहेड को कम करता है और सिस्टम को वास्तविक उत्पादन सेटिंग्स में उत्तरदायी रखता है। बहाव प्रबंधन संस्करण एम्बेडिंग, इंडेक्स, चंकिंग रणनीतियों और अंतर्ग्रहण नीतियों को नियंत्रित करता है। दस्तावेज़ बदलने या मॉडल बदलने पर पुनर्मूल्यांकन करें। इंजीनियर ताजगी स्पष्ट रूप से। समय के साथ सामग्री, मॉडल और क्वेरी पैटर्न विकसित होने पर मौन गुणवत्ता क्षय को रोकता है। मूल्यांकन वास्तविक प्रश्नों के आधार पर सुनहरे डेटासेट बनाए रखता है। पुनर्प्राप्ति मेट्रिक्स को जनरेशन मेट्रिक्स से अलग करें। संदर्भ परिशुद्धता, स्मरण, जमीनीपन और विश्वसनीयता को मापें। केवल अंतिम उत्तर की गुणवत्ता पर निर्भर रहने के बजाय वास्तविक विफलता बिंदु की पहचान करने में मदद करें। निगरानी और अनुरेखण, तैनाती से पहले मूल्यांकन चलाएं और लॉन्च के बाद निगरानी करें। पुनर्प्राप्ति और पीढ़ी परतों में ट्रेसिंग जोड़ें। प्रतिगमन को दृश्यमान बनाता है और टीमों को उत्पादन में विफलताओं का अधिक सटीक निदान करने में मदद करता है। परहेज़ व्यवहार सिस्टम को बताता है कि जब सबूत गायब है, बासी है, या विरोधाभासी है। आत्मविश्वास से भरे लेकिन कमजोर उत्तरों पर अनुशासित ग्राउंडिंग का समर्थन करके विश्वास में सुधार करता है। एंबेडिंग बहाव और ज्ञान परिवर्तन के कारण विफलता
<पी> एंबेडिंग्स पाठ को एक-दूसरे के करीब समान अर्थ वाले उच्च-आयामी वैक्टर के रूप में दर्शाते हैं। टीमें अक्सर अपने दस्तावेज़ों को एक अलग एम्बेडिंग मॉडल के साथ फिर से एम्बेड करती हैं या अपने इंडेक्स को ठीक से संस्करणित किए बिना या प्रासंगिकता परिवर्तनों को बेंचमार्क किए बिना क्वेरी एनकोडर को स्वैप कर देती हैं। नया मॉडल वस्तुनिष्ठ रूप से मजबूत हो सकता है, लेकिन यह पड़ोस की संरचना को अप्रत्याशित तरीकों से बदल सकता है जो रैंकिंग, रिकॉल या यहां तक कि डोमेन-विशिष्ट भाषा को भी प्रभावित कर सकता है। एक मॉडल जो सामान्यीकृत बेंचमार्क पर उत्कृष्टता प्राप्त करता है, वह आपके वास्तविक दुनिया के उद्यम लिंगो के साथ बहुत खराब प्रदर्शन कर सकता है। बहाव के तीन कारण
- मॉडल ड्रिफ्ट. एंबेडिंग मॉडल लगातार अपडेट किए जाते हैं। जब आप किसी एम्बेडिंग मॉडल के संस्करण का उपयोग करके दस्तावेज़ों को अनुक्रमित करते हैं, तो आप उन्हें किसी अन्य मॉडल से एम्बेडिंग के साथ नहीं खोज सकते। कॉर्पस को पुनः अनुक्रमित किए बिना एम्बेडिंग मॉडल को स्विच करने से आपकी पुनर्प्राप्ति प्रभावित होगी।
- कॉर्पस बहाव। जब आप सूचकांक में नए दस्तावेज़ जोड़ते हैं, विशेष रूप से नए प्रकार के दस्तावेज़, तो वेक्टर स्थान बदल जाता है। घने वैक्टरों के नए समूह दिखाई देते हैं। वे घने समूह उन प्रश्नों को खींचना शुरू कर देते हैं जिनका अन्य दस्तावेज़ों से मिलान होना चाहिए। उपयोगकर्ता-जनित या शोर-शराबे वाली सामग्री जोड़ने से समय के साथ पुनर्प्राप्ति गुणवत्ता ख़राब हो जाएगी, भले ही आप एम्बेडिंग मॉडल न बदलें।
- क्वेरी ड्रिफ्ट. उपयोगकर्ताओं की शब्दावली समय के साथ बढ़ती और बदलती रहती है। नए शब्द उपयोग में आते हैं ("दूरस्थ कार्य," "स्थिर मुद्रा," "त्वरित इंजीनियरिंग") और पुरानी शब्दावली ख़त्म हो जाती है। पहले से मौजूद एम्बेडिंग उन शब्दों से मेल नहीं खा सकती जो प्रशिक्षित होने के समय मौजूद नहीं थे। यदि कोई कंपनी अपने किसी उत्पाद का नाम बदल देती है, तो नए नाम की खोज विफल हो जाती है क्योंकि एम्बेडिंग अभी भी पुराने नाम को दर्शाती है।
मीन रेसिप्रोकल रैंक के साथ एंबेडिंग ड्रिफ्ट का पता लगाना
<पी> नीचे एक उदाहरण आरेख है जो दर्शाता है कि सिस्टम परिवर्तन से पहले और बाद में या समय के साथ पुनर्प्राप्ति प्रदर्शन में परिवर्तनों की निगरानी करके एम्बेडिंग बहाव का पता कैसे लगाया जाता है। आरेख पहले बेसलाइन एमआरआर स्कोर की गणना करता है जहां प्रासंगिक दस्तावेज़ रैंकिंग के शीर्ष के पास दिखाई देते हैं। फिर यह वर्तमान एमआरआर स्कोर की गणना करता है जहां प्रासंगिक दस्तावेजों को रैंकिंग में और नीचे स्थान दिया जाता है। सिस्टम तब बेसलाइन एमआरआर और वर्तमान एमआरआर के बीच प्रतिशत गिरावट की गणना करता है। यदि एमआरआर ड्रॉप पूर्व-चयनित सीमा से ऊपर है, तो सिस्टम एम्बेडिंग बहाव के लिए अलर्ट जारी करता है और एम्बेडिंग मॉडल, डेटा वितरण और सूचकांक की समीक्षा करने का सुझाव देता है। अन्यथा, यदि गिरावट सीमा से नीचे है, तो सिस्टम निर्धारित करता है कि पुनर्प्राप्ति प्रणाली स्थिर है और निगरानी जारी रखती है। <पी> 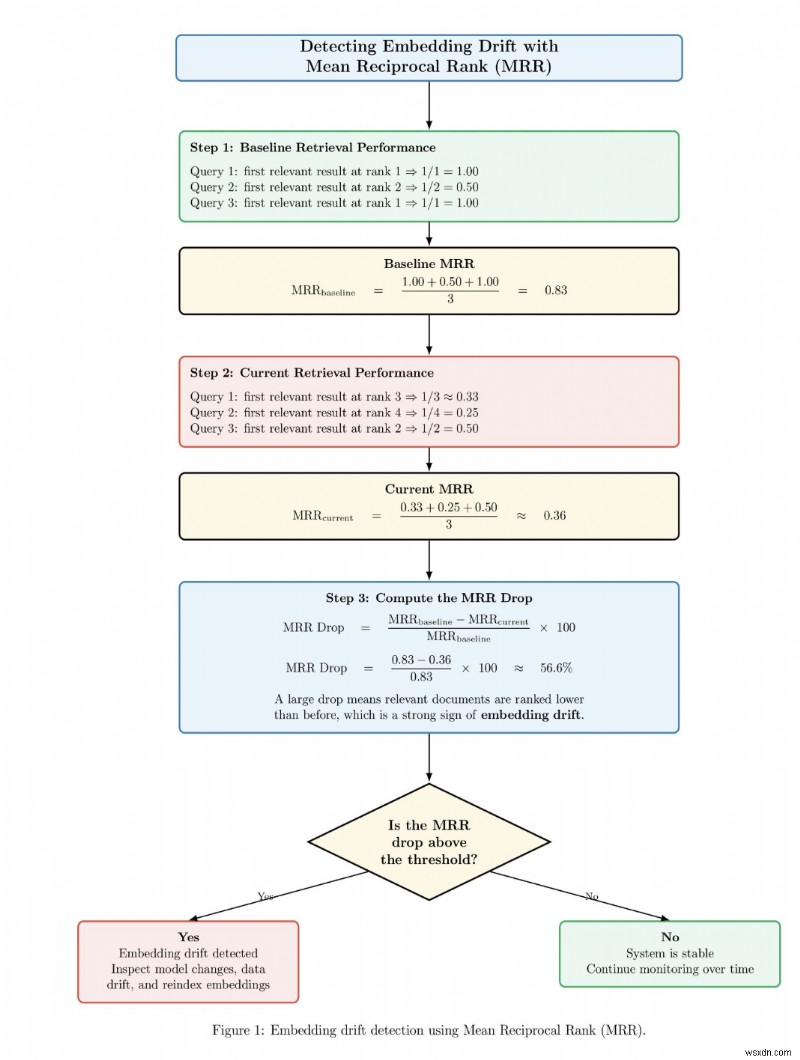 <पी> इस कारण से, उत्पादन आरएजी सिस्टम को स्पष्ट रूप से संस्करणित और अवलोकनीय बनाने की आवश्यकता है। एंबेडिंग्स को संस्करणित किया जाना चाहिए। इंडेक्स बिल्ड का पता लगाया जाना चाहिए। चंकिंग नीति को प्रलेखित और पुनरुत्पादित किया जाना चाहिए। यदि गुणवत्ता ख़राब होने लगती है, तो आपको प्रश्नों का उत्तर देने में सक्षम होना चाहिए जैसे:किस एम्बेडिंग मॉडल ने इस सूचकांक का उत्पादन किया? सामग्री के इस हिस्से को किस नियम के तहत बनाया गया है? यह दस्तावेज़ आखिरी बार सिस्टम में कब पुनः शामिल किया गया था? किस रिट्रीवर और रीरैंकर ने इस अनुरोध को पूरा किया? <पी> यदि आपके पास पाइपलाइन में दृश्यता नहीं है, तो बहाव यादृच्छिक प्रतीत होगा। इससे इसका निदान हो जाता है.
<पी> इस कारण से, उत्पादन आरएजी सिस्टम को स्पष्ट रूप से संस्करणित और अवलोकनीय बनाने की आवश्यकता है। एंबेडिंग्स को संस्करणित किया जाना चाहिए। इंडेक्स बिल्ड का पता लगाया जाना चाहिए। चंकिंग नीति को प्रलेखित और पुनरुत्पादित किया जाना चाहिए। यदि गुणवत्ता ख़राब होने लगती है, तो आपको प्रश्नों का उत्तर देने में सक्षम होना चाहिए जैसे:किस एम्बेडिंग मॉडल ने इस सूचकांक का उत्पादन किया? सामग्री के इस हिस्से को किस नियम के तहत बनाया गया है? यह दस्तावेज़ आखिरी बार सिस्टम में कब पुनः शामिल किया गया था? किस रिट्रीवर और रीरैंकर ने इस अनुरोध को पूरा किया? <पी> यदि आपके पास पाइपलाइन में दृश्यता नहीं है, तो बहाव यादृच्छिक प्रतीत होगा। इससे इसका निदान हो जाता है. मूल्यांकन अंतराल के कारण विफलता:वास्तविक बाधा को छिपाती है
<पी> कमजोर मूल्यांकन चौथा सबसे आम कारण है कि टीमें आरएजी सिस्टम को उत्पादन में तैनात करने में विफल रहती हैं। हम केवल अंतिम उत्तर का मूल्यांकन करते हैं। यह पर्याप्त नहीं है. <पी> उत्पादन-ग्रेड आरएजी एक पाइपलाइन है। किसी भी संख्या में परतों पर, खराब इनपुट खराब अंतिम आउटपुट का कारण बन सकता है। हो सकता है पुनर्प्राप्तकर्ता सही दस्तावेज़ पुनर्प्राप्त करने में विफल रहा हो। हो सकता है कि रैंकर ने सर्वोत्तम साक्ष्य को बहुत कम रैंक दिया हो। संदर्भ असेंबलर में बहुत अधिक शोर शामिल हो सकता है। हो सकता है कि जनरेटर ने सबसे मजबूत मार्ग को चमका दिया हो। उत्तर व्यापक स्तर पर सही हो सकता है जबकि अभी भी पुनर्प्राप्त साक्ष्यों के प्रति पूरी तरह से बेवफा है। यदि आप केवल अंतिम आउटपुट टेक्स्ट स्कोर करते हैं तो आप कमजोर चरणों की पहचान नहीं कर सकते। पुनर्प्राप्ति मेट्रिक्स का मूल्यांकन अलग से किया जाना चाहिए
<पी> इस कारण से, आरएजी मूल्यांकन में जेनरेशन मेट्रिक्स से अलग पुनर्प्राप्ति मेट्रिक्स शामिल होना चाहिए। पुनर्प्राप्ति मेट्रिक्स में संदर्भ परिशुद्धता और संदर्भ स्मरण शामिल होना चाहिए। - संदर्भ स्मरण :संदर्भ स्मरण यह जांचता है कि प्राप्त अंशों में प्रश्न का उत्तर देने के लिए आवश्यक जानकारी है या नहीं।
- संदर्भ परिशुद्धता :संदर्भ परिशुद्धता मापता है कि पुनर्प्राप्त सेट अधिकतर प्रासंगिक है या शोर से प्रदूषित है।
- रैंकिंग गुणवत्ता: रैंकिंग की गुणवत्ता भी मायने रखती है, क्योंकि रैंक 1 पर प्रासंगिक अनुच्छेद रैंक 10 पर समान प्रासंगिक अनुच्छेद की तुलना में अधिक उपयोगी है।
जेनरेशन मेट्रिक्स उतना ही मायने रखता है
<पी> एक बार पुनर्प्राप्ति को मापने के बाद, पीढ़ी परत का मूल्यांकन अपनी शर्तों पर किया जाना चाहिए। दो प्रमुख मीट्रिक हैं ज़मीनीपन और विश्वसनीयता। - आधारभूतता: ग्राउंडेडनेस पूछती है कि क्या उत्तर पुनर्प्राप्त संदर्भ में प्रदान की गई जानकारी को दर्शाता है।
- विश्वासयोग्यता: फेथफुलनेस पूछती है कि क्या मॉडल उस संदर्भ का सटीक प्रतिनिधित्व करता है। यह मीट्रिक मायने रखती है क्योंकि एक प्रणाली स्रोत सामग्री को गलत तरीके से प्रस्तुत करते हुए भी विश्वसनीय लग सकती है।
अवास्तविक परीक्षण डेटा वास्तविक विफलताओं को छुपाता है
<पी> अवास्तविक परीक्षण डेटा एक और प्रमुख मुद्दा है। कई टीमें स्वच्छ, सिंथेटिक प्रश्नों या आंतरिक टीमों द्वारा सावधानीपूर्वक तैयार किए गए संकेतों पर मूल्यांकन करती हैं। यह मूल रूप से वास्तविक विफलता सतह को छुपाता है। उत्पादन में मूल्यांकन की स्थितियों में अस्पष्ट प्रश्न, विरोधाभासी दस्तावेज़, आंशिक उपयोगकर्ता इनपुट, पुरानी सामग्री और ऐसी स्थितियाँ शामिल होनी चाहिए जहाँ सही उत्तर का उत्तर ही न दिया जाए। यदि डेटासेट वास्तविक उपयोगकर्ता व्यवहार को प्रतिबिंबित नहीं करता है, तो मूल्यांकन एक निदान उपकरण के बजाय एक आरामदायक तंत्र बन जाता है। तैनाती के बाद भी मूल्यांकन जारी रहना चाहिए
<पी> प्रारंभिक दौड़ पूरी करने के बाद मूल्यांकन बंद नहीं होना चाहिए। उत्पादन आरएजी बदलते हैं। दस्तावेज़ बदलते हैं. एंबेडिंग्स की अदला-बदली हो जाती है। रैंकिंग तर्क विकसित होता है। शीघ्र टेम्पलेट्स शिफ्ट. आपके सीआई/सीडी के हिस्से के रूप में मूल्यांकन और तैनाती के बाद उत्पादन का पता लगाने के बिना, आप उनकी स्वयं की निगरानी के बजाय नाखुश उपयोगकर्ताओं से प्रतिगमन के बारे में सीखेंगे। बेंचमार्क अच्छे दिखने पर भी उत्पादन RAG विफल क्यों होता है
<पी> यहीं पर कई टीमें भ्रमित हो जाती हैं। बेंचमार्क में सुधार हुआ है, फिर भी लाइव सिस्टम अभी भी निराश करता है। <पी> उत्पादन विफलताएं आमतौर पर प्रोत्साहन के गलत संरेखण के कारण होती हैं। टीमें विलंबता बजट को ध्यान में रखे बिना पुनर्प्राप्ति रिकॉल के लिए अनुकूलन करने का प्रयास करती हैं या पुनर्प्राप्ति परिशुद्धता को ट्रैक किए बिना उच्च एलएलएम स्कोर के लिए अनुकूलन करती हैं। उत्पादन की गुणवत्ता की कीमत पर पुनर्प्राप्ति को ओवर-ट्यून किया जा सकता है, जिससे शोर उत्पन्न हो सकता है। पुनर्प्राप्ति सुधारों की परवाह किए बिना पीढ़ी को ओवर-ट्यून किया जा सकता है। पुनर्प्राप्ति और पीढ़ी सटीकता के बीच उचित अनुपात अनुप्रयोग पर निर्भर करता है। अनुपालन, कानूनी और अन्य उच्च जोखिम वाले उपयोग के मामलों में यथासंभव अधिक विश्वसनीयता और संदर्भ परिशुद्धता की आवश्यकता होती है। रचनात्मक उपयोग के मामले गति के बदले शोर की अनुमति दे सकते हैं। <पी> उत्पादन को किसी एक मीट्रिक पर अनुकूलित नहीं किया गया है। पुनर्प्राप्ति गुणवत्ता, विलंबता, ताजगी, जमीनीपन और परिचालन सादगी के बीच व्यापार-संबंध हैं। इसीलिए डेमो सफलता इतनी भ्रामक हो सकती है। डेमो पुरस्कार प्रणाली जो "सही लगती है"। उत्पादन विश्वसनीयता को पुरस्कृत करता है। उत्पादन RAG सिस्टम को कैसे ठीक करें
<पी> आगे का रास्ता आरएजी को छोड़ना नहीं है। इसे एक अनुशासित पुनर्प्राप्ति प्रणाली के रूप में मानना है। फोकस क्षेत्र | क्या करें | यह क्यों मायने रखता है | पुनर्प्राप्ति गुणवत्ता डिफ़ॉल्ट निश्चित विंडो के बजाय डोमेन-जागरूक चंकिंग का उपयोग करें। जहां यह मायने रखता है वहां दस्तावेज़ संरचना को सुरक्षित रखें। सघन और शाब्दिक पुनर्प्राप्ति को मिलाएं। पुनःरैंकिंग जोड़ें. मेटाडेटा का बुद्धिमानी से उपयोग करें। कवरेज और प्रासंगिकता में सुधार करता है, और सिस्टम को उस संदर्भ को पुनः प्राप्त करने में मदद करता है जो जमीनी उत्तरों के लिए अधिक उपयोगी है। विलंबता नियंत्रण हर चरण को मापें। उन कदमों को हटा दें जिनसे सार्थक लाभ न हो। पाइपलाइन को उतना सरल रखें जितना उपयोग का मामला अनुमति देता है। वास्तविक इंटरेक्शन पैटर्न के लिए निर्माण करें। अनावश्यक ओवरहेड को कम करता है और सिस्टम को वास्तविक उत्पादन सेटिंग्स में उत्तरदायी रखता है। बहाव प्रबंधन संस्करण एम्बेडिंग, इंडेक्स, चंकिंग रणनीतियों और अंतर्ग्रहण नीतियों को नियंत्रित करता है। दस्तावेज़ बदलने या मॉडल बदलने पर पुनर्मूल्यांकन करें। इंजीनियर ताजगी स्पष्ट रूप से। समय के साथ सामग्री, मॉडल और क्वेरी पैटर्न विकसित होने पर मौन गुणवत्ता क्षय को रोकता है। मूल्यांकन वास्तविक प्रश्नों के आधार पर सुनहरे डेटासेट बनाए रखता है। पुनर्प्राप्ति मेट्रिक्स को जनरेशन मेट्रिक्स से अलग करें। संदर्भ परिशुद्धता, स्मरण, जमीनीपन और विश्वसनीयता को मापें। केवल अंतिम उत्तर की गुणवत्ता पर निर्भर रहने के बजाय वास्तविक विफलता बिंदु की पहचान करने में मदद करें। निगरानी और अनुरेखण, तैनाती से पहले मूल्यांकन चलाएं और लॉन्च के बाद निगरानी करें। पुनर्प्राप्ति और पीढ़ी परतों में ट्रेसिंग जोड़ें। प्रतिगमन को दृश्यमान बनाता है और टीमों को उत्पादन में विफलताओं का अधिक सटीक निदान करने में मदद करता है। परहेज़ व्यवहार सिस्टम को बताता है कि जब सबूत गायब है, बासी है, या विरोधाभासी है। आत्मविश्वास से भरे लेकिन कमजोर उत्तरों पर अनुशासित ग्राउंडिंग का समर्थन करके विश्वास में सुधार करता है। अक्सर पूछे जाने वाले प्रश्न अनुभाग
आप RAG में पुनर्प्राप्ति गुणवत्ता कैसे मापते हैं?
<पी> हम संदर्भ परिशुद्धता, संदर्भ स्मरण और रैंकिंग गुणवत्ता जैसे पुनर्प्राप्ति मेट्रिक्स का उपयोग करते हैं, और यह भी जांचते हैं कि क्या पुनर्प्राप्त साक्ष्य वास्तव में उत्तर पीढ़ी का समर्थन करते हैं। RAG सिस्टम के उत्पादन में विफल होने का क्या कारण है?
<पी> उत्पादन विफलताएं आमतौर पर पुनर्प्राप्ति गुणवत्ता में गिरावट, विलंबता रेंगना, एम्बेडिंग/कॉर्पस बहाव और खराब मूल्यांकन प्रथाओं के कारण होती हैं जो समस्याएं जहां शुरू होती हैं वहां छुप जाती हैं। RAG पाइपलाइन में एम्बेडिंग ड्रिफ्ट क्या है?
<पी> एंबेडिंग ड्रिफ्ट तब होता है जब एंबेडिंग मॉडल, कॉर्पोरा, या लाइव क्वेरी व्यवहार के अपडेट धीरे-धीरे पुनर्प्राप्ति व्यवहार (घटती प्रासंगिकता) को बदलते हैं, बिना किसी स्पष्ट रूप से टूटे हुए सिस्टम व्यवहार के। RAG विलंबता बड़े पैमाने पर क्यों बढ़ती है?
<पी> विलंबता बढ़ जाती है क्योंकि उत्पादन प्रणालियाँ अक्सर क्वेरी पुनर्लेखन, एकाधिक पुनर्प्राप्ति पास, पुनर्रैंकिंग, अतिरिक्त मॉडल कॉल और बड़े कॉर्पोरा जोड़ती हैं, जो सभी प्रसंस्करण समय और परिचालन जटिलता को बढ़ाते हैं। आप RAG में ज़मीनीपन और ईमानदारी का मूल्यांकन कैसे करते हैं?
<पी> आप उत्पन्न उत्तर की तुलना पुनर्प्राप्त साक्ष्यों से करते हैं, यह जाँचते हुए कि क्या दावे स्रोतों द्वारा समर्थित हैं और क्या शब्दांकन बिना किसी आविष्कार या विरूपण के उन स्रोतों को सटीक रूप से दर्शाता है। निष्कर्ष
<पी> अधिकांश आरएजी प्रणालियों में उत्पादन विफलता विफलता के एक बिंदु का परिणाम नहीं है। इसके बजाय, जिम्मेदार इंजीनियर देखेंगे कि अधिकांश ब्रेकडाउन एक जुड़ी हुई श्रृंखला में एक कमजोर लिंक से शुरू होते हैं। पुनर्प्राप्ति गुणवत्ता लगभग हमेशा सबसे पहले विफल होती है। इंजीनियर अधिक पुनर्प्राप्ति, अधिक संदर्भ और अधिक ऑर्केस्ट्रेशन परतों का लाभ उठाकर इस समस्या को "हल" करते हैं। ऐसा करना विलंबता को बढ़ाने का काम करता है। जैसे-जैसे एंबेडिंग, कॉर्पोरा और उपयोगकर्ता व्यवहार समय के साथ बदलते जाते हैं, कमजोर मूल्यांकन मेट्रिक्स छिप जाते हैं जहां सिस्टम वास्तव में विफल हो रहा है। इससे पहले कि प्रबंधकों को पता चले कि कोई समस्या है, उपयोगकर्ता नोटिस करना शुरू कर देते हैं और भरोसा खो देते हैं। तब तक, पैटर्न का टूटना रहस्यमय लगता है। हालाँकि, समस्याएँ शुरू से ही स्पष्ट थीं। <पी> आरएजी बड़े पैमाने पर विफल रहता है, इसलिए नहीं कि पैटर्न गलत है, बल्कि इसलिए कि निर्माण उत्पादन आरएजी सिस्टम के लिए मजबूत पुनर्प्राप्ति इंजीनियरिंग, विलंबता प्रबंधन, बहाव शमन और निरंतर मूल्यांकन की आवश्यकता होती है। वे बेहतर रैंकिंग, बेहतर चंकिंग, बेहतर अवलोकन, और जमीनी स्तर और विश्वसनीयता के माप की मांग करते हैं। सबसे महत्वपूर्ण बात यह है कि टीमों को आरएजी को एक सेट-इट-एंड-फॉरगेट-इट डेमो आर्किटेक्चर के बजाय एक जीवित प्रणाली के रूप में देखने की जरूरत है। संदर्भ
- उत्पादन में RAG प्रणाली:यह विफल क्यों होती है और इसे कैसे ठीक करें
- 2026 में RAG (और LLM) के लिए सर्वश्रेष्ठ चंकिंग रणनीतियाँ
- आरएजी मूल्यांकन क्या है? पुनर्प्राप्ति गुणवत्ता और उत्तर की जमीनी स्थिति को मापना
- पुनर्प्राप्ति-संवर्धित पीढ़ी मॉडल अनुमान में सिस्टम ट्रेड-ऑफ को समझने की दिशा में
- RAGPerf:रिट्रीवल-ऑगमेंटेड जेनरेशन सिस्टम के लिए एक एंड-टू-एंड बेंचमार्किंग फ्रेमवर्क
- रीरैंकर्स और टू-स्टेज रिट्रीवल
- RAG से संदर्भ तक - RAG की 2025 साल के अंत की समीक्षा
<पी>  यह कार्य क्रिएटिव कॉमन्स एट्रिब्यूशन-नॉन-कमर्शियल- के तहत लाइसेंस प्राप्त है शेयरअलाइक 4.0 अंतर्राष्ट्रीय लाइसेंस।
यह कार्य क्रिएटिव कॉमन्स एट्रिब्यूशन-नॉन-कमर्शियल- के तहत लाइसेंस प्राप्त है शेयरअलाइक 4.0 अंतर्राष्ट्रीय लाइसेंस।