संपीड़ित क्वाडट्री
उप-विभाजित सेल से संबंधित प्रत्येक नोड को संग्रहीत करते समय, हम बहुत सारे खाली नोड्स को संग्रहीत कर सकते हैं। ऐसे विरल वृक्षों के आकार को कम करना केवल उन उप-वृक्षों को संग्रहीत करके संभव है जिनकी पत्तियों में दिलचस्प डेटा होता है (यानी "महत्वपूर्ण उपट्री")। फिर से हम वास्तव में आकार में और भी कटौती कर सकते हैं। जब हम केवल महत्वपूर्ण उप-वृक्षों पर विचार करते हैं, तो छंटाई प्रक्रिया पेड़ में लंबे पथों से बच सकती है जहां मध्यवर्ती नोड्स की डिग्री दो होती है (एक माता-पिता और एक बच्चे के लिए एक लिंक)। यह पता चला है कि हमें केवल इस पथ की शुरुआत में नोड यू को स्टोर करने की आवश्यकता है (और हटाए गए नोड्स का प्रतिनिधित्व करने के लिए इसके साथ कुछ मेटा-डेटा संबद्ध करें) और इसके अंत में रूट किए गए सबट्री को यू से संलग्न करें। इन संपीड़ित पेड़ों में अभी भी एक है "खराब" इनपुट पॉइंट दिए जाने पर रैखिक ऊँचाई।
यद्यपि हम इस संपीड़न को करते समय बहुत सारे पेड़ काट देते हैं, फिर भी जेड-ऑर्डर वक्रों का लाभ उठाकर लॉगरिदमिक-टाइम सम्मिलन, विलोपन और खोज प्राप्त करना संभव है। जेड-ऑर्डर वक्र पूर्ण क्वाडट्री (और इसलिए संपीड़ित क्वाडट्री) के प्रत्येक सेल को ओ (1) समय में 1-आयामी रेखा में परिवर्तित करता है (और इसे ओ (1) समय में भी परिवर्तित करता है), कुल ऑर्डर का निर्माण तत्वों पर। अब, हम ऑर्डर किए गए सेटों के लिए डेटा संरचना में क्वाडट्री को स्टोर करने में सक्षम हो सकते हैं (जिसमें हम पेड़ के नोड्स को स्टोर करते हैं)। अब, हमें जारी रखने से पहले एक उचित धारणा बतानी चाहिए:हम मानते हैं कि दो वास्तविक संख्या α,β € [0,1] को बाइनरी के रूप में दर्शाया गया है, हम ओ (1) समय में पहली बिट की अनुक्रमणिका की गणना कर सकते हैं जिसमें वे अलग होना। हम यह भी मानते हैं कि हम ओ (1) समय में क्वाडट्री में दो बिंदुओं/कोशिकाओं के सबसे छोटे सामान्य पूर्वज की गणना कर सकते हैं और उनके सापेक्ष जेड-ऑर्डरिंग स्थापित कर सकते हैं, और हम ओ (1) समय में फर्श फ़ंक्शन की गणना कर सकते हैं। इन मान्यताओं के साथ, किसी दिए गए बिंदु Q का बिंदु स्थान (अर्थात उस कक्ष का पता लगाएं जिसमें Q होगा), विलोपन और सम्मिलन संचालन सभी O(n log n) समय में किया जा सकता है (अर्थात खोज करने में लगने वाला समय) अंतर्निहित आदेशित सेट डेटा संरचना)।
क्यू के लिए एक बिंदु स्थान करने के लिए (यानी संपीड़ित पेड़ में अपने सेल का निर्धारण)
- मौजूदा सेल कंप्रेस्ड ट्री में पाया जाता है जो Z-क्रम में Q से पहले आता है। इस सेल V को कॉल करें।
- यदि Q€V किया जाता है, तो V लौटाएं।
- अन्यथा, एक असम्पीडित चतुर्भुज में बिंदु Q और सेल V का सबसे छोटा सामान्य पूर्वज ज्ञात कीजिए। इस पूर्वज सेल यू को बुलाओ।
- संपीड़ित पेड़ में मौजूदा सेल को खोजें जो Z-क्रम में U से पहले आता है और उसे वापस कर देता है।
विशिष्ट विवरण में जाने के बिना, सम्मिलन और विलोपन करने के लिए हम पहले उस चीज़ के लिए एक बिंदु स्थान करते हैं जिसे हम सम्मिलित / हटाना चाहते हैं, और फिर उसे सम्मिलित / हटाते हैं। पेड़ को उचित आकार देने, आवश्यकतानुसार नोड्स बनाने और हटाने के लिए देखभाल की जानी चाहिए।
ऑक्ट्री
एक ऑक्ट्री को एक ट्री डेटा संरचना के रूप में परिभाषित किया जाता है जिसमें प्रत्येक आंतरिक नोड ठीक आठ बच्चों से जुड़ा होता है।
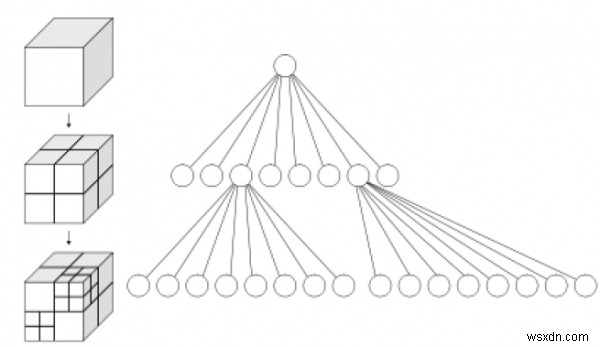
ऑक्ट्रीज़ को अक्सर एक 3-आयामी स्थान को आठ ऑक्टेंट में पुनरावर्ती रूप से उप-विभाजित करके विभाजित करने के लिए लागू किया जाता है।
ऑक्ट्रीज़ को क्वाडट्रीज़ के 3-आयामी एनालॉग के रूप में माना जाता है। नाम oct + tree से बनाया गया है, लेकिन ध्यान दें कि यह सामान्य रूप से केवल एक "t" के साथ "octree" लिखा जाता है।
ऑक्ट्रीज़ को अक्सर 3D ग्राफ़िक्स और 3D गेम इंजन में लागू किया जाता है।
स्थानिक प्रतिनिधित्व के लिए
एक ऑक्ट्री में प्रत्येक नोड उस स्थान को उप-विभाजित करने के लिए जिम्मेदार होता है जिसे वह आठ अष्टक में दर्शाता है। एक बिंदु क्षेत्र में (पीआर)
octree, नोड एक स्पष्ट 3-आयामी बिंदु संग्रहीत करता है, जो उस नोड के उपखंड का "केंद्र" है; बिंदु
आठ बच्चों में से प्रत्येक के लिए एक कोने को निर्दिष्ट करता है। मैट्रिक्स आधारित (एमएक्स) ऑक्ट्री के मामले में, उपखंड बिंदु परोक्ष रूप से नोड द्वारा दर्शाए गए स्थान का केंद्र होता है। एक पीआर ऑक्ट्री का मूल नोड अनंत स्थान का प्रतिनिधित्व करने में सक्षम हो सकता है; एमएक्स ऑक्ट्री का रूट नोड एक सीमित सीमित स्थान का प्रतिनिधित्व करने में सक्षम होना चाहिए ताकि निहित केंद्र अच्छी तरह से परिभाषित हों।
सामान्य उपयोग
- 3D कंप्यूटर ग्राफ़िक्स में विवरण रेंडरिंग का स्तर
- स्थानिक अनुक्रमण
- निकटतम पड़ोसी को खोज रहे हैं
- तीन आयामों में प्रभावी टक्कर का पता लगाना
- परिमित तत्व का विश्लेषण
- स्पैस वोक्सेल ऑक्ट्री
- राज्य का अनुमान
- सेट का अनुमान