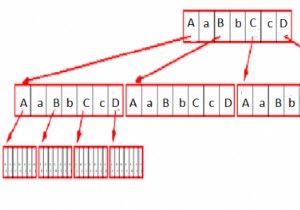
एक निर्णय वृक्ष एक प्रवाह-चार्ट-जैसी वृक्ष तंत्र है, जहां प्रत्येक आंतरिक नोड एक विशेषता पर एक परीक्षण इंगित करता है, प्रत्येक विभाग परीक्षण के परिणाम को परिभाषित करता है, और पत्ती नोड्स कक्षाओं या वर्ग वितरण का वर्णन करते हैं। पेड़ में सबसे ऊंचा नोड रूट नोड होता है।
डिसीजन ट्री सीखने के लिए एल्गोरिदम
एल्गोरिदम - दी गई प्रशिक्षण जानकारी से निर्णय वृक्ष बनाएं।
इनपुट - असतत-मूल्यवान विशेषताओं द्वारा वर्णित प्रशिक्षण नमूने, नमूने; छात्रों की विशेषताओं का सेट, विशेषता-सूची।
आउटपुट - एक निर्णय वृक्ष।
विधि
-
नोड एन बनाएं;
-
यदि नमूने सभी एक ही वर्ग, C के हैं तो
-
एन को क्लास सी के साथ लेबल किए गए लीफ नोड के रूप में लौटाएं
-
यदि विशेषता-सूची शून्य है तो
-
नमूनों में सबसे सामान्य वर्ग के साथ लेबल किए गए लीफ नोड के रूप में एन लौटाएं। // बहुमत मतदान
-
परीक्षण-विशेषता का चयन करें, विशेषता-सूची में सबसे अधिक जानकारी लाभ के साथ विशेषता।
-
परीक्षण विशेषता के साथ लेबल नोड एन।
-
परीक्षण-विशेषता के प्रत्येक ज्ञात मान के लिए // नमूनों को विभाजित करें।
-
स्थिति के लिए नोड N से एक शाखा विकसित करें test-attribute=ai ।
-
चलोi नमूनों में नमूनों का सेट हो जिसके लिए परीक्षण-विशेषता =ai ।
-
अगर si खाली है तो
-
यह नमूनों में सबसे आम वर्ग के साथ लेबल किए गए पत्ते को जोड़ सकता है।
-
अन्यथा जनरेट डिसीजन ट्री द्वारा लौटाए गए नोड को संलग्न करें ( si,विशेषता-सूची - परीक्षण-विशेषता)
डिसीजन ट्री इंडक्शन
उदाहरण के लिए निर्णय नियमों के स्वत:उत्पादन को नियम प्रेरण या स्वचालित नियम प्रेरण के रूप में जाना जाता है। यह एक निर्णय वृक्ष के निहित डिजाइन में निर्णय नियम बना सकता है जिसे अक्सर नियम प्रेरण के रूप में भी जाना जाता है, लेकिन शब्द वृक्ष प्रेरण या निर्णय वृक्ष प्रेरण लगातार चुने जाते हैं।
निर्णय वृक्ष प्रेरण के लिए मूल एल्गोरिथ्म एक लालची एल्गोरिथ्म है। इसका उपयोग टॉप-डाउन रिकर्सिव डिवाइड-एंड-कॉनकर तरीके से निर्णय पेड़ उत्पन्न करने के लिए किया जाता है। डिसीजन ट्री सीखने के लिए मूल एल्गोरिथम, ID3 का एक रूप है, जो एक प्रसिद्ध डिसीजन ट्री इंडक्शन एल्गोरिथम है।
बुनियादी तरीके इस प्रकार हैं -
-
ट्री प्रशिक्षण नमूनों को परिभाषित करने वाले एक व्यक्तिगत नोड के रूप में शुरू होता है।
-
यदि नमूने सभी समान वर्गों के हैं, तो नोड एक पत्ती में बदल जाता है और उस वर्ग के साथ लेबल किया जाता है।
-
एल्गोरिथ्म एक एंट्रोपी-आधारित माप को लागू करता है जिसे सूचना लाभ के रूप में संदर्भित किया जाता है, जो उस विशेषता को चुनने के लिए एक अनुमानी के रूप में होता है जो नमूनों को एकल वर्गों में विभाजित करेगा। यह विशेषता नोड पर "परीक्षण" या "निर्णय" विशेषता में विकसित होती है। एल्गोरिथम के इस रूप में, सभी विशेषताएँ श्रेणीबद्ध हैं, अर्थात, असतत-मूल्यवान। निरंतर मूल्यवान विशेषताओं को अलग किया जाना चाहिए।
-
परीक्षण विशेषता के प्रत्येक ज्ञात मूल्य के लिए एक विभाग तैयार किया जाता है, और नमूने उचित रूप से विभाजित होते हैं।
-
एल्गोरिथ्म प्रत्येक पृथक्करण पर नमूनों के लिए निर्णय ट्री बनाने के लिए समान प्रक्रिया लूपिंग का उपयोग करता है। चूंकि एक नोड पर एक विशेषता दिखाई दी है, इसलिए यह आवश्यक है कि नोड के कुछ वंशजों में इसका इलाज न किया जाए।