<पी> इस पोस्ट में, मैं इस बारे में बात करता हूं कि कैसे मैंने अपस्टैश वेक्टर, अपस्टैश रेडिस, हगिंग फेस इनफेरेंस एपीआई, रेप्लिकेट LLAMA-2-70B चैट मॉडल और वर्सेल के साथ एक ओपन-सोर्स कस्टम कंटेंट RAG चैटबॉट बनाया। अपस्टैश वेक्टर ने मुझे वैक्टर सम्मिलित करने और क्वेरी करने, प्रत्येक उपयोगकर्ता संदेश के लिए प्रासंगिक संदर्भ को गतिशील रूप से बनाने या अपडेट करने में मदद की, और अपस्टैश रेडिस ने मुझे चैटबॉट वार्तालापों को संग्रहीत करने में मदद की। आवश्यकताएँ
<पी> आपको निम्नलिखित की आवश्यकता होगी: - Node.js 18 या बाद का संस्करण
- एक अपस्टैश खाता
- ए हगिंग फेस अकाउंट
- एक प्रतिकृति खाता
- एक वर्सेल खाता
टेक स्टैक
प्रौद्योगिकी | विवरण | अपस्टैशसर्वरलेस डेटाबेस प्लेटफ़ॉर्म। हम क्रमशः वैक्टर और वार्तालापों को संग्रहीत करने के लिए अपस्टैश वेक्टर और अपस्टैश रेडिस दोनों का उपयोग कर रहे हैं। वेब के लिए नेक्स्ट.जेएस रिएक्ट फ्रेमवर्क। हम रैपिड प्रोटोटाइपिंग के लिए पॉप्युलेट shadcn/ui का उपयोग कर रहे हैं। रिप्लिकेट रन और ओपन-सोर्स मॉडल को फाइन-ट्यून करें। हम LLAMA-2-70B चैट मॉडल का उपयोग कर रहे हैं। हगिंग फेस वह प्लेटफॉर्म है जहां मशीन लर्निंग समुदाय मॉडल, डेटासेट और एप्लिकेशन पर सहयोग करता है। हम एम्बेडिंग बनाने के लिए हगिंग फेस इनफेरेंस एपीआई का उपयोग कर रहे हैं। भाषा मॉडल द्वारा संचालित अनुप्रयोगों को विकसित करने के लिए लैंगचेनफ्रेमवर्क। कस्टम डिजाइन बनाने के लिए टेलविंडसीएसएससीएसएस फ्रेमवर्क। वेब अनुप्रयोगों को तैनात करने और स्केल करने के लिए वर्सेलएक क्लाउड प्लेटफॉर्म। अपस्टैश रेडिस की स्थापना
<पी> एक बार जब आप एक अपस्टैश खाता बना लेते हैं और लॉग इन हो जाते हैं तो आप रेडिस टैब पर जाएंगे और एक डेटाबेस बनाएंगे। <पी> 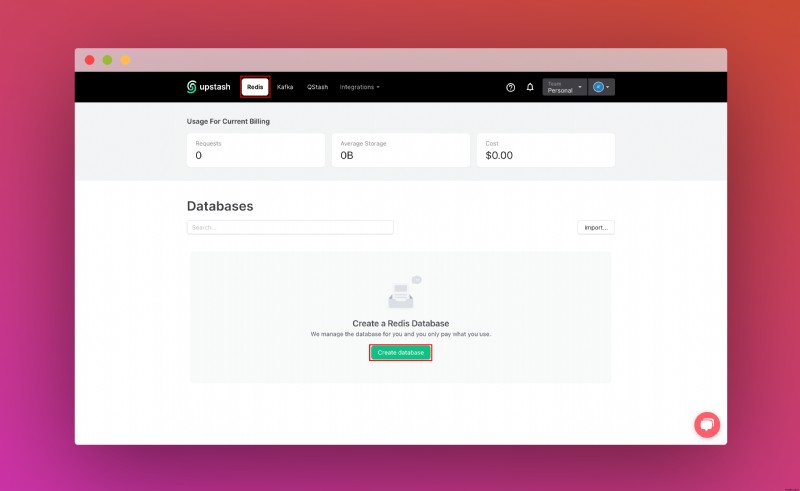 <पी>
<पी> 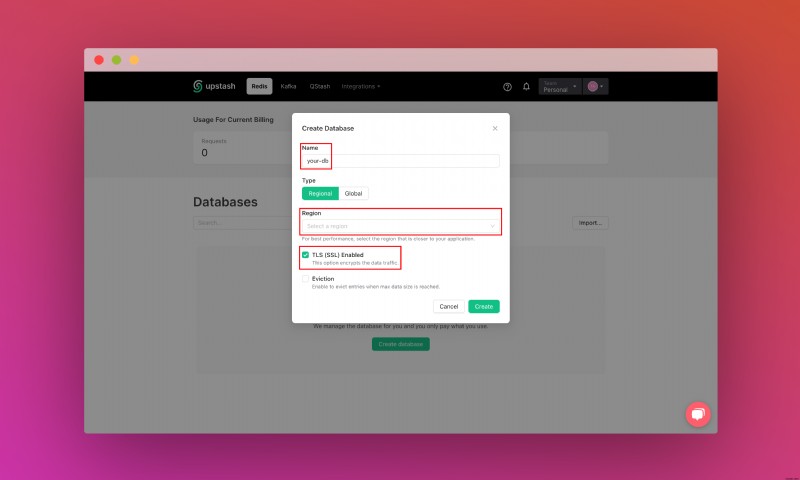 <पी> अपना डेटाबेस बनाने के बाद, आप विवरण टैब पर जा रहे हैं। जब तक आपको अपना डेटाबेस कनेक्ट करें अनुभाग नहीं मिल जाता तब तक नीचे स्क्रॉल करें। सामग्री को कॉपी करें और इसे किसी सुरक्षित स्थान पर सहेजें। <पी>
<पी> अपना डेटाबेस बनाने के बाद, आप विवरण टैब पर जा रहे हैं। जब तक आपको अपना डेटाबेस कनेक्ट करें अनुभाग नहीं मिल जाता तब तक नीचे स्क्रॉल करें। सामग्री को कॉपी करें और इसे किसी सुरक्षित स्थान पर सहेजें। <पी> 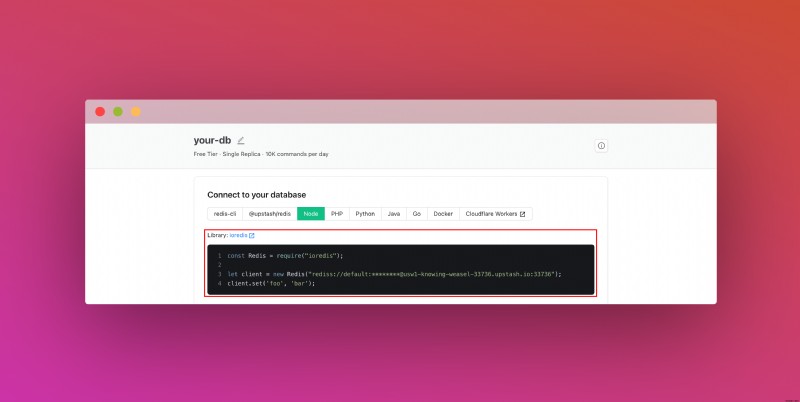 <पी> इसके अलावा, तब तक नीचे स्क्रॉल करें जब तक आपको REST API अनुभाग न मिल जाए और .env बटन का चयन करें। सामग्री को कॉपी करें और इसे किसी सुरक्षित स्थान पर सहेजें। <पी>
<पी> इसके अलावा, तब तक नीचे स्क्रॉल करें जब तक आपको REST API अनुभाग न मिल जाए और .env बटन का चयन करें। सामग्री को कॉपी करें और इसे किसी सुरक्षित स्थान पर सहेजें। <पी> 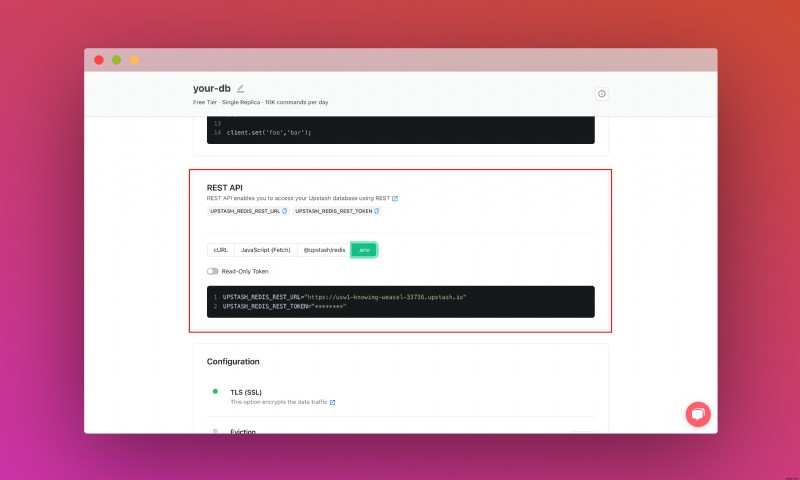
अपस्टैश वेक्टर सेट करना
<पी> एक बार जब आप एक अपस्टैश खाता बना लेते हैं और लॉग इन हो जाते हैं तो आप वेक्टर टैब पर जाएंगे और एक इंडेक्स बनाएंगे। <पी>  <पी>
<पी> 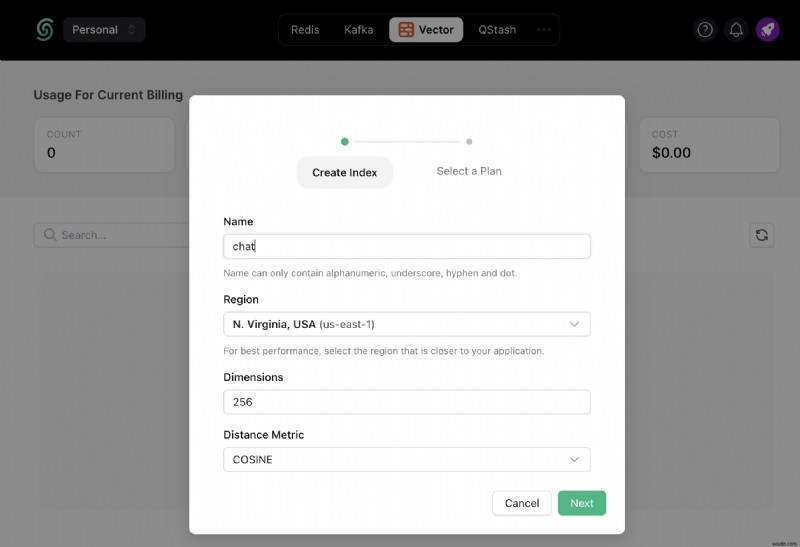 <पी> इसके अलावा, तब तक नीचे स्क्रॉल करें जब तक आपको कनेक्ट न मिल जाए अनुभाग और .env का चयन करें बटन. सामग्री को कॉपी करें और इसे किसी सुरक्षित स्थान पर सहेजें। <पी>
<पी> इसके अलावा, तब तक नीचे स्क्रॉल करें जब तक आपको कनेक्ट न मिल जाए अनुभाग और .env का चयन करें बटन. सामग्री को कॉपी करें और इसे किसी सुरक्षित स्थान पर सहेजें। <पी> 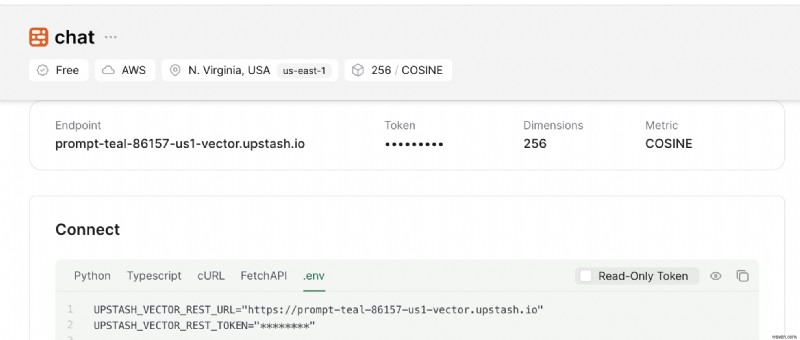
प्रोजेक्ट की स्थापना
<पी> सेट अप करने के लिए, बस ऐप रेपो को क्लोन करें और इसमें जो कुछ भी है उसे जानने के लिए इस ट्यूटोरियल का अनुसरण करें। प्रोजेक्ट को फोर्क करने के लिए, चलाएँ: git clone https://github.com/rishi-raj-jain/custom-rag-chatbot-upstash-vector
cd custom-rag-chatbot-upstash-vector
pnpm install
<पी> एक बार जब आप रेपो क्लोन कर लेते हैं, तो आप एक .env बनाने जा रहे हैं फ़ाइल. आप उपरोक्त अनुभागों से हमारे द्वारा सहेजे गए आइटम जोड़ने जा रहे हैं। <पी> इसे कुछ इस तरह दिखना चाहिए: # .env
# Obtained from the steps as above
# Upstash Redis URL and Token
UPSTASH_REDIS_REST_URL="https://....upstash.io"
UPSTASH_REDIS_REST_TOKEN="..."
# Upstash Vector URL and Token
UPSTASH_VECTOR_REST_URL="https://...-vector.upstash.io"
UPSTASH_VECTOR_REST_TOKEN="..."
# Replicate API Key
REPLICATE_API_TOKEN="r8_..."
# Hugging Face Inference API Key
HUGGINGFACEHUB_API_KEY="hf_..."
<पी> इन चरणों के बाद, आपको निम्न आदेश का उपयोग करके स्थानीय वातावरण प्रारंभ करने में सक्षम होना चाहिए: pnpm dev
भंडार संरचना
<पी> यह प्रोजेक्ट के लिए मुख्य फ़ोल्डर संरचना है. मैंने उन फ़ाइलों को लाल रंग में चिह्नित किया है जिन पर इस पोस्ट में आगे चर्चा की जाएगी जो आपके कस्टम संदर्भ पर प्रशिक्षित एआई के साथ चैट करने के लिए एपीआई रूट बनाने और upsert द्वारा संदर्भ को अपडेट करने से संबंधित है। -मौजूदा सूचकांक में वैक्टर डालना। <पी> 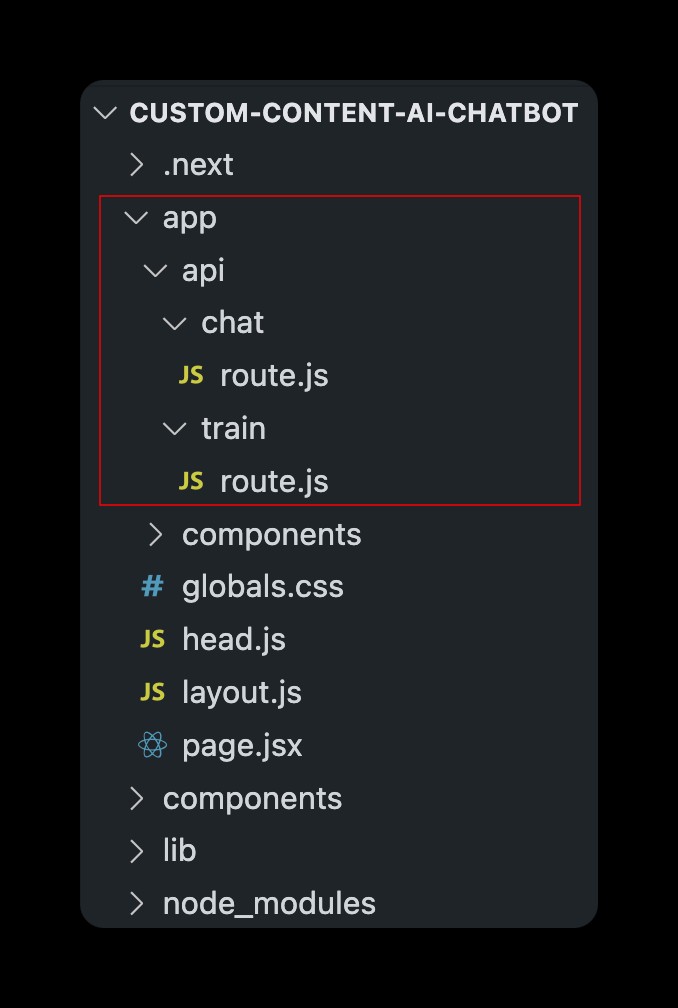
नेक्स्ट.जेएस ऐप राउटर में चैट रूट सेटअप करें
<पी> इस अनुभाग में, हम इस बारे में बात करते हैं कि हमने मार्ग कैसे सेटअप किया है:app/api/chat/route.js हमारे सर्वर रहित डेटाबेस में बातचीत को सिंक करने के लिए, गतिशील रूप से स्ट्रिंग्स की एम्बेडिंग बनाएं, संदर्भ बनाने के लिए किसी दिए गए इंडेक्स से प्रासंगिक वैक्टर को क्वेरी करें, और LLAMA-2-70B चैट मॉडल का उपयोग करके प्रासंगिक भविष्यवाणियों का अनुरोध करें। चीजों को सरल बनाने के लिए, हम इसे आगे के भागों में तोड़ेंगे: बातचीत संग्रहीत करना
<पी> अपस्टैश रेडिस के साथ होने वाली बातचीत को कैश करने के लिए, हम रेडिस लिस्ट्स का उपयोग करेंगे। जैसे ही किसी उपयोगकर्ता की ओर से प्रतिक्रिया देने के लिए कोई संदेश आता है, हम सशर्त प्रतिक्रिया को चैटबॉट (पहले) से सूची में धकेल देते हैं। फिर, हम उपयोगकर्ता के नवीनतम संदेश को भी सूची में धकेल कर सहेजते हैं, और उस पर प्रतिक्रिया देने के लिए आगे बढ़ते हैं। // File: app/api/chat/route.js
import { Redis } from '@upstash/redis'
// Instantiate the Upstash Redis
const upstashRedis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL,
token: process.env.UPSTASH_REDIS_REST_TOKEN,
})
export async function POST(req) {
try {
// the whole chat as array of messages
const { messages } = await req.json()
// assuming user - assistant chat
// add assitant's response to the chat history
if (messages.length > 1) {
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 2]))
}
// add user's request to the chat history
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 1]))
// Proceed to create a response
}
नवीनतम संदेश की एम्बेडिंग बनाएं
<पी> उपयोगकर्ता के नवीनतम संदेश का सभी दिए गए संदर्भों (यानी उपयोगकर्ता द्वारा आपूर्ति की गई कस्टम सामग्री) में प्रभावी ढंग से उत्तर देने के लिए, हम एक एम्बेडिंग बनाने जा रहे हैं जो हमें मौजूदा सूचकांक से प्रासंगिक संदर्भ (उर्फ समान वैक्टर) पुनर्प्राप्त करने में मदद करेगा। हम किनारे पर सिर्फ एक एपीआई कॉल के साथ एम्बेडिंग बनाने के लिए लैंगचेन के साथ हगिंग फेस इनफरेंस एपीआई का उपयोग करेंगे और प्राप्त वेक्टर को अपस्टैश वेक्टर इंडेक्स (यहां, 256) को स्पिन करते समय कॉन्फ़िगर की गई लंबाई में काट देंगे। ). // File: app/api/chat/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// ...
// get the latest question stored in the last message of the chat array
const userMessages = messages.filter((i) => i.role === 'user')
const lastMessage = userMessages[userMessages.length - 1].content
// generate embeddings of the latest question
const queryVector = (await embeddings.embedQuery(lastMessage)).slice(0, 256)
// Proceed to create a response
}
नवीनतम संदेश के आधार पर प्रासंगिक संदर्भ वैक्टर पुनर्प्राप्त करें
<पी> उपयोगकर्ता द्वारा प्रति संदेश दिए गए सभी संदर्भों को गतिशील रूप से लाना एक महंगा ऑपरेशन है। हम केवल उपयोगकर्ता के नवीनतम संदेश से संबंधित संदर्भ का उपयोग करना चाहते हैं, और इसे सिस्टम प्रॉम्प्ट के रूप में LLAMA-2-70B चैट मॉडल में पास करना चाहते हैं। केवल प्रासंगिक संदर्भ लाने के लिए, हम उनके मेटाडेटा सहित 2 सबसे अधिक प्रासंगिक वैक्टर प्राप्त करने के लिए वैक्टर के मौजूदा सेट को क्वेरी करते हैं और उन परिणामों को फ़िल्टर करते हैं जहां आत्मविश्वास स्कोर 70% से अधिक है। // File: app/api/chat/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// query the relevant vectors from the embedding vector
const queryResult = await upstashVectorIndex.query({
vector: queryVector,
// get the top 2 relevant results
topK: 2,
// do not include the whole set of embeddings in the response
includeVectors: false,
// include the meta data so that can get the description out of the index
includeMetadata: true,
})
// console.log('The query result came in', queryResult.length)
// using the resulting set of relevant vectors
// filter the one that have score of greater than 70% match
// and get the description we stored while training
const queryPrompt = queryResult
.filter((match) => match.score && match.score > 0.7)
.map((match) => match.metadata.description)
.join('\n')
// console.log('The query prompt is', queryPrompt)
// Proceed to create a response
}
भविष्यवाणियों के संदर्भ के साथ LLAMA-2-70B चैट मॉडल का संकेत दें
<पी> अब जब हमने प्रासंगिक संदर्भ को एक स्ट्रिंग के रूप में प्राप्त कर लिया है, तो अंतिम चरण उपयोगकर्ता के नवीनतम संदेश का जवाब देने के लिए llama-2-70B चैट मॉडल को संकेत देना है। हम वर्सेल एआई एसडीके के experimental_buildLlama2Prompt का उपयोग करते हैं विधि जो llama-2-70B चैट मॉडल के लिए उपयुक्त प्रॉम्प्ट प्रारूप बनाने का ध्यान रखती है। // File: app/api/chat/route.js
import Replicate from 'replicate'
import { experimental_buildLlama2Prompt } from 'ai/prompts'
import { ReplicateStream, StreamingTextResponse } from 'ai'
// Instantiate the Replicate API
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
})
export async function POST(req) {
try {
// ...
const response = await replicate.predictions.create({
// You must enable streaming.
stream: true,
// The model must support streaming. See https://replicate.com/docs/streaming
// This is the model ID for Llama 2 70b Chat
version: '2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1',
// Format the message list into the format expected by Llama 2
// @see https://github.com/vercel/ai/blob/99cf16edf0a09405d15d3867f997c96a8da869c6/packages/core/prompts/huggingface.ts#L53C1-L78C2
input: {
prompt: experimental_buildLlama2Prompt([
{
// create a system content message to be added as
// the llama2prompt generator will supply it as the context with the API
role: 'system',
content: queryPrompt.substring(0, Math.min(queryPrompt.length, 2000)),
},
// also, pass the whole conversation!
...messages,
]),
},
})
// stream the result to the frontend
const stream = await ReplicateStream(response)
return new StreamingTextResponse(stream)
}
नेक्स्ट.जेएस ऐप राउटर में ट्रेन रूट सेटअप करें
<पी> इस अनुभाग में, हम इस बारे में बात करते हैं कि हमने मार्ग कैसे सेटअप किया है:app/api/train/route.js अनुरोध ऑब्जेक्ट में पारित स्ट्रिंग्स की एम्बेडिंग को गतिशील रूप से बनाने के लिए, और उन्हें अपस्टैश वेक्टर इंडेक्स में जोड़ें। चीजों को सरल बनाने के लिए, हम इसे आगे के भागों में तोड़ेंगे: स्ट्रिंग्स की एम्बेडिंग बनाएं
<पी> हम स्ट्रिंग्स की एम्बेडिंग बनाने जा रहे हैं जो हमें मौजूदा इंडेक्स को सेट या अपडेट करने में मदद करेगी। ऐसा करने से हमें चैटबॉट की भविष्य की प्रतिक्रियाओं के संदर्भ को अद्यतन रखने की अनुमति मिलती है। हम किनारे पर केवल एक एपीआई कॉल के साथ एम्बेडिंग बनाने के लिए लैंगचेन के साथ हगिंग फेस इनफेरेंस एपीआई का उपयोग करेंगे। // File: app/api/train/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// a default set of messages to create vector embeddings on
let messagesToVectorize = [
'Rishi is pretty much active on Twitter nowadays.',
'Rishi loves writing for Upstash',
"Rishi's recent article on building chatbot using Upstash went viral",
'Rishi is enjoying building launchfa.st.',
]
// if the POST request is of type application/json
if (req.headers.get('Content-Type') === 'application/json') {
// and if the request contains array of messages to train on
const { messages } = await req.json()
if (typeof messages !== 'string' && messages.length > 0) {
messagesToVectorize = messages
}
}
// Call the Hugging Face Inference API to get emebeddings on the messages
const generatedEmbeddings = await Promise.all(messagesToVectorize.map((i) => embeddings.embedQuery(i)))
// ...
}
प्रासंगिकता खोज के लिए वैक्टर संग्रहीत करें
<पी> जेनरेट किए गए एम्बेडिंग को वेक्टर इंडेक्स में जोड़ने के लिए, हम प्राप्त वैक्टर को अपस्टैश वेक्टर इंडेक्स को स्पिन करते समय कॉन्फ़िगर की गई लंबाई में काटते हैं (यहां, 256 ) और upsert का उपयोग करें मेटाडेटा के साथ एम्बेडिंग डालने की विधि, यानी स्ट्रिंग्स स्वयं। जब समान वैक्टर खोजे जाते हैं तो यह हमें स्ट्रिंग्स को पुनः प्राप्त करने की अनुमति देता है और इसलिए, प्रतिक्रिया उत्पन्न करने के लिए LLAMA-2-70B चैट मॉडल को कॉल करते समय बातचीत का ज्ञान आधार सेट करता है। // File: app/api/train/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// Slice the vector into lengths of upto 256
await Promise.all(
generatedEmbeddings
.map((i) => i.slice(0, 256))
.map((vector, index) =>
// Upsert the vector with description to be further as the context to upcoming questions
upstashVectorIndex.upsert({
vector,
id: index.toString(),
metadata: { description: messagesToVectorize[index] },
}),
),
)
// Once done, return with a successful 200 response
return new Response(JSON.stringify({ code: 1 }), { status: 200, headers: { 'Content-Type': 'application/json' } })
}
<पी> वह बहुत कुछ सीखने वाला था! अब आपका काम पूरा हो गया है ✨ वर्सेल में तैनात करें
<पी> रिपॉजिटरी, अब वर्सेल में तैनात करने के लिए तैयार है। 👇🏻 को तैनात करने के लिए निम्नलिखित चरणों का उपयोग करें - अपने ऐप के कोड वाली GitHub रिपॉजिटरी बनाकर शुरुआत करें।
- फिर, वर्सेल डैशबोर्ड पर नेविगेट करें और एक नया प्रोजेक्ट बनाएं .
- नए प्रोजेक्ट को आपके द्वारा अभी बनाए गए GitHub रिपॉजिटरी से लिंक करें।
- सेटिंग्स में ,
Environment Variables को अपडेट करें आपके स्थानीय .env से मिलान करने के लिए फ़ाइल.
- तैनाती! 🚀
अधिक जानकारी
<पी> अधिक विस्तृत जानकारी के लिए, इस पोस्ट में उद्धृत संदर्भ देखें। निष्कर्ष
<पी> अंत में, इस परियोजना ने एम्बेडिंग बनाने, वैक्टर के मौजूदा सेट से क्वेरी करने और LLAMA-2-70B चैट मॉडल का उपयोग करके प्रासंगिक भविष्यवाणियां बनाने के लिए संदर्भ का उपयोग करने के तरीके को सीखने में मूल्यवान अनुभव प्रदान किया है, जबकि आपकी ज़रूरत के अनुरूप सेवा का उपयोग करते हुए, यानी अपस्टैश।