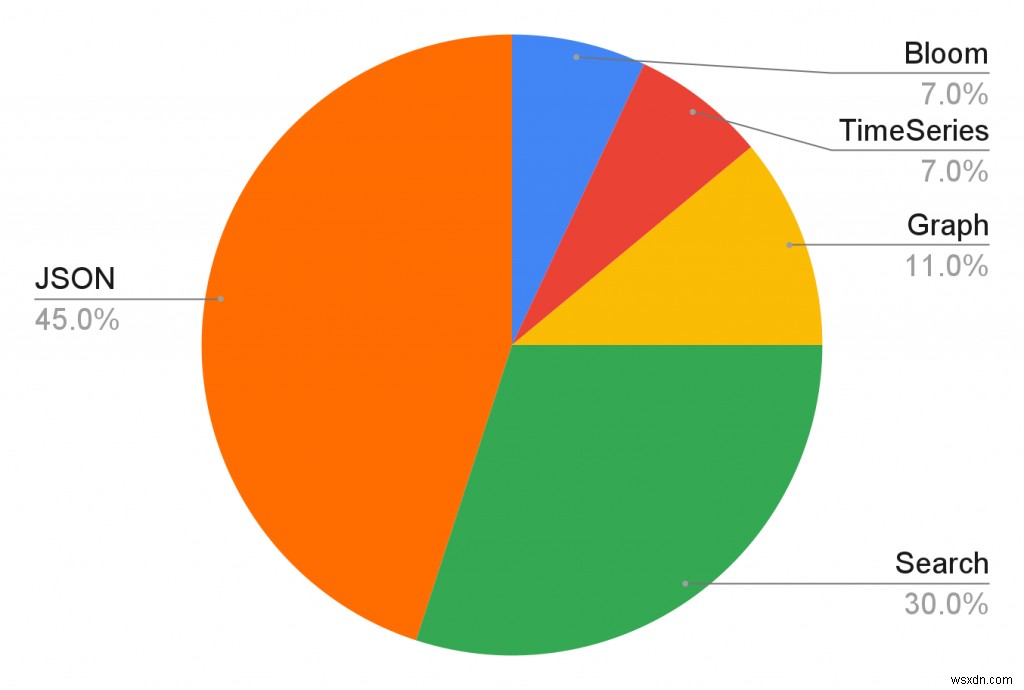
RedisJSON और RediSearch हमारे क्लाउड में अब तक के सबसे लोकप्रिय Redis मॉड्यूल हैं। (अंजीर देखें। 1) RedisJSON और RediSearch (Redis के साथ बंडल) की डॉकटर छवियां हर एक दिन में 2000 से अधिक बार खींची जाती हैं। यही कारण है कि हम रेडिस के प्रौद्योगिकी प्रचारक इतामार हैबर को एक दूरदर्शी के रूप में सोचते हैं, जब उन्होंने 4 साल पहले पहला संस्करण लिखा था। अप्रैल में, हमने RedisConf में JSON, अनुक्रमण और पूर्ण-पाठ खोज क्षमताओं से संबंधित कई घोषणाएँ कीं। आज, हमें इन क्षमताओं के निजी पूर्वावलोकन की घोषणा करते हुए खुशी हो रही है।
इस ब्लॉग में, हम आपको वर्तमान RedisJSON क्षमताओं का अवलोकन देंगे। उसके बाद हम इस निजी पूर्वावलोकन के नए क्षमता अनुभाग में प्रवेश करेंगे। RediSearch का उपयोग करके JSON दस्तावेज़ों पर पूर्ण-पाठ खोज को अनुक्रमित करने, क्वेरी करने और उपयोग करने की क्षमता इस रिलीज़ की सबसे अच्छी नई विशेषता है। अंत में, हम आपको दिखाएंगे कि कैसे जल्दी से शुरुआत करें।
JSON क्षमताएं
जब आपके पास RedisJSON नहीं होता है, तो आप स्ट्रिंग डेटा संरचना का उपयोग करके Redis में नेस्टेड दस्तावेज़ों को मॉडल करते हैं।
लेकिन, क्या होगा यदि हमें दस्तावेज़ के उप-भाग को अपडेट करने की आवश्यकता है?
ऑपरेशन की परमाणुता को बनाए रखने के लिए, हमें यह करना होगा:
- दस्तावेज़ देखें
- पिछला संस्करण पढ़ें और उसे क्रमानुसार करें
- एक Redis लेनदेन में अद्यतन एम्बेड करें
- JSON को क्रमानुसार करें और दस्तावेज़ को अपडेट करें
- लेन-देन निष्पादित करें
यदि किसी अन्य क्लाइंट ने इस प्रक्रिया के दौरान दस्तावेज़ को अपडेट किया है, तो हमें इन सभी चरणों का पुन:प्रयास करने की आवश्यकता हो सकती है।
हालाँकि, RedisJSON के साथ, हम यह अपडेट एकल परमाणु लेनदेन के साथ कर सकते हैं :
आइए एक और उदाहरण देखें, जहां आपके पास एक बड़ा JSON है, लेकिन आपके आवेदन में केवल उस दस्तावेज़ के एक उप-भाग की आवश्यकता है।
RedisJSON के बिना:
आपको यह करना होगा:
- एक स्ट्रिंग के रूप में क्रमबद्ध, संपूर्ण जोंस स्ट्रिंग प्राप्त करें
- JSON को डिसेरिएलाइज़ करें
- अपनी ज़रूरत का सबपार्ट निकालें
RedisJSON के साथ, आप केवल उसी डेटा को पुनः प्राप्त कर सकते हैं जिसकी आपको एक कमांड के साथ आवश्यकता होती है, CPU चक्र को कम करके, नेटवर्क ओवरहेड, और, सबसे महत्वपूर्ण, विलंबता।
जैसा कि आप देख सकते हैं, RedisJSON JSON दस्तावेज़ जोड़तोड़ को सरल करता है। RedisJSON (v1.0) का वर्तमान GA संस्करण वह संस्करण है जिसका समुदाय पहले से ही व्यापक रूप से उपयोग कर रहा है और स्ट्रिंग डेटा संरचना के साथ नेस्टेड संरचनाओं के मॉडलिंग की कमियों को ठीक करता है। यहां इसकी कुछ प्रमुख क्षमताओं का अवलोकन दिया गया है।
Redis में एक कुंजी के साथ जुड़े JSON दस्तावेज़ को स्टोर (या अपडेट) करें
उप-भाग बदलें (उदा. कुंजी का स्ट्रिंग मान)
किसी संग्रह या मानचित्र में कोई आइटम जोड़ें
संपूर्ण दस्तावेज़ निकालें
JSONPath के सबसेट का उपयोग करके इसका कुछ भाग निकालें
RedisJSON 2.0:निजी पूर्वावलोकन रिलीज़
हमने RedisConf 2021 में इस संस्करण की घोषणा की, और आज हमें यह घोषणा करते हुए खुशी हो रही है कि यह हमारे Redis Enterprise ग्राहकों के एक चुनिंदा समूह के लिए एक निजी पूर्वावलोकन के रूप में उपलब्ध है—और हमारे समुदाय के लिए एक रिलीज़ उम्मीदवार के रूप में। इस संस्करण में तीन प्रमुख विशेषताएं हैं, अर्थात्, JSONPath अभिव्यक्ति का पूर्ण समर्थन, सक्रिय-सक्रिय (Redis Enterprise के साथ) के लिए समर्थन, और RediSearch के साथ JSON दस्तावेज़ों पर अनुक्रमण, क्वेरी और पूर्ण-पाठ खोज का उपयोग करने की क्षमता। लेकिन और भी है! आइए नई अच्छाइयों के बारे में जानें।
रूस्ट में फिर से लिखा गया
सिस्टम प्रोग्रामिंग भाषाएं दक्षता के लिए उन्मुख भाषाओं का एक परिवार है। इन भाषाओं में लिखे गए प्रोग्राम आमतौर पर हल्के होते हैं और सर्वश्रेष्ठ प्रदर्शन प्रदान करते हैं। यही कारण है कि रेडिस को ऐतिहासिक रूप से सी में लिखा गया है। यह भी बताता है कि रेडिस बेहद कम विलंबता और उच्च थ्रूपुट प्राप्त करने में सक्षम क्यों है। अधिकांश रेडिस मॉड्यूल सी, सी ++, या रस्ट में लिखे गए हैं, जो एक ही परिवार की भाषाएं हैं।
JSON को विशेष रूप से रस्ट समुदाय द्वारा बहुत तेज़ और कुशल JSON क्रमांकन और JSONPath कार्यान्वयन सहित अच्छी तरह से परोसा जाता है। Redis उपयोगकर्ताओं को उन कार्यान्वयनों का लाभ देना स्पष्ट था और केवल Redis मॉड्यूल API और Rust के बीच मैपिंग की आवश्यकता थी।
JSONPath के लिए पूर्ण समर्थन
और यहाँ इस RUST पुनर्लेखन का लाभ है। इस नए संस्करण में JSONPath का व्यापक समर्थन शामिल है। अब JSONPath अभिव्यक्तियों की सभी अभिव्यक्तियों का उपयोग करना संभव है।
JSON दस्तावेज़ को देखते हुए
वाइल्डकार्ड (पहले पहले आइटम तक सीमित था)
स्लाइस निकालें
फ़िल्टर एक्सप्रेशन के साथ एक अधिक उन्नत उदाहरण
सक्रिय-सक्रिय के लिए समर्थन
एक्टिव-एक्टिव रेडिस एंटरप्राइज द्वारा प्रदान की गई एक सुविधा है। सक्रिय-सक्रिय आपको अपने डेटाबेस को भौगोलिक रूप से वितरित कई रेडिस एंटरप्राइज क्लस्टर में दोहराने की अनुमति देता है। उपयोगकर्ता स्थानीय पढ़ने और लिखने की विलंबता के साथ निकटतम क्लस्टर से जुड़ सकते हैं।
यह कार्यान्वयन कॉन्फ्लिक्ट-फ्री रेप्लिकेटेड डेटा-टाइप (सीआरडीटी) तकनीक पर आधारित है। रेडिस द्वारा समर्थित अधिकांश कोर डेटा संरचनाओं के लिए इसे लागू करते समय, रेडिस ने JSON के लिए किए गए इस नए कार्यान्वयन द्वारा पुष्टि की गई एक मजबूत ज्ञान और अनुभव विकसित किया।
एप्लिकेशन डेवलपर अब JSON दस्तावेज़ों का उपयोग करके भू-वितरित एप्लिकेशन बनाने के लिए इस पर भरोसा कर सकते हैं। यहां दो समूहों के साथ सक्रिय-सक्रिय वातावरण में संचालन के उत्तराधिकार का एक उदाहरण दिया गया है:
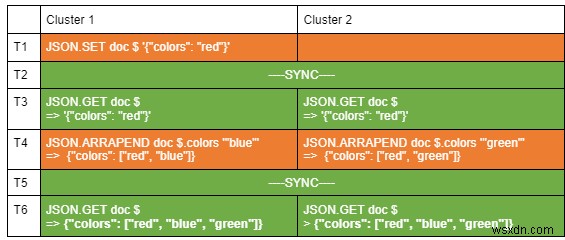
आइए प्रत्येक ऑपरेशन का विवरण देखें:
- T1:क्लाइंट क्लस्टर 1 पर JSON दस्तावेज़ सेट करता है।
- T2:सिंक्रनाइज़ेशन प्रक्रिया दस्तावेज़ को क्लस्टर 2 पर दोहराती है।
- T3:दोनों समूहों में एक ही दस्तावेज़ है।
- T4:एक क्लाइंट क्लस्टर 1 में रंग सरणी में नीला रंग जोड़ता है, और साथ ही, दूसरा क्लाइंट क्लस्टर 2 में उसी सरणी में हरा रंग जोड़ रहा है।
- T5:सिंक्रोनाइज़ेशन प्रक्रिया ऑपरेशन को मर्ज करती है और दस्तावेज़ को दोनों क्लस्टर पर अपडेट करती है।
- T6:दोनों समूहों में एक ही दस्तावेज़ है।
जब यह क्षमता सार्वजनिक पूर्वावलोकन में होगी, तो हम सभी सिंक्रनाइज़ेशन प्रवाहों के बारे में अधिक विस्तार से बताएंगे, लेकिन यदि आप इस क्षमता में रुचि रखते हैं, तो अब support@redis.com पर संपर्क करने में संकोच न करें।
RediSearch 2.2:निजी पूर्वावलोकन रिलीज़
यह ब्लॉग RediSearch 2.2 के लिए एक निजी पूर्वावलोकन की उपलब्धता की भी घोषणा करता है (हमारे Redis Enterprise ग्राहकों के चुनिंदा समूह के लिए एक निजी पूर्वावलोकन के रूप में और हमारे समुदाय के लिए एक रिलीज़ उम्मीदवार के रूप में)।
इस खंड में हम RediSearch की इस नई रिलीज़ द्वारा प्रदान की गई नई सुविधाओं का वर्णन करने जा रहे हैं। लेकिन पहले, यहाँ एक कारण है कि हम उन दो लोकप्रिय मॉड्यूल को एक साथ क्यों जारी कर रहे हैं:
JSON दस्तावेज़ों का अनुक्रमण, क्वेरी करना और पूर्ण-पाठ खोज
यह विशेष रूप से नई सुविधा रेडिस की JSON क्षमताओं को एक नए स्तर पर लाएगी। की-वैल्यू स्टोर होने के अलावा, अब तक, RediSearch हैश पर अनुक्रमण और खोज क्षमताएं प्रदान करता रहा है। हुड के तहत, RedisJSON 2.0 एक आंतरिक सार्वजनिक एपीआई को उजागर करता है। आंतरिक, क्योंकि यह एपीआई रेडिस नोड के अंदर चल रहे अन्य मॉड्यूल के संपर्क में है। सार्वजनिक, क्योंकि कोई भी मॉड्यूल इस एपीआई का उपभोग कर सकता है। तो क्या RediSearch 2.2 !
अन्य मॉड्यूल के लिए अपनी क्षमताओं को उजागर करके, RedisJSON RediSearch को JSON दस्तावेज़ों को अनुक्रमित करने की क्षमता देता है ताकि उपयोगकर्ता अब सामग्री को अनुक्रमित और क्वेरी करके दस्तावेज़ ढूंढ सकें। ये संयुक्त मॉड्यूल आपको एक शक्तिशाली, कम विलंबता, JSON-उन्मुख दस्तावेज़ डेटाबेस प्रदान करते हैं !
आइए देखें कि यह कैसा दिखेगा।
हमें पहले JSON.SET कमांड का उपयोग करके डेटाबेस को JSON दस्तावेज़ के साथ पॉप्युलेट करना चाहिए।
एक नया इंडेक्स बनाने के लिए, हम FT.CREATE कमांड का उपयोग करते हैं। अनुक्रमणिका का स्कीमा अब JSONPath व्यंजकों को स्वीकार करता है। व्यंजक का परिणाम अनुक्रमित होता है और एक विशेषता के साथ संबद्ध होता है (यहां:शीर्षक)।
अब हम एक खोज क्वेरी कर सकते हैं और FT.SEARCH का उपयोग करके अपना JSON दस्तावेज़ ढूंढ सकते हैं:
JSON दस्तावेज़ों पर एकत्रीकरण
एकत्रीकरण RediSearch की एक शक्तिशाली विशेषता है जिसका उपयोग विश्लेषणात्मक रिपोर्ट बनाने या पहलू खोज शैली क्वेरी करने के लिए किया जा सकता है। अब जबकि RediSearch JSON दस्तावेज़ों को एक्सेस कर सकता है, JSONPath एक्सप्रेशन का उपयोग करके JSON दस्तावेज़ से किसी भी मान को लोड करना और पाइपलाइन में इसका उपयोग करना संभव है, चाहे मान अनुक्रमित हो या नहीं।
आइए एक इंडेक्स बनाएं:
डेटाबेस में JSON दस्तावेज़ जोड़ें:
और JSON दस्तावेज़ से निकाले गए दो संख्यात्मक मान का उपयोग करके एक सरल गणना करें:
अनुक्रमण रणनीति पर अधिक लचीलापन
RediSearch के नए संस्करण के साथ, अब समान मान (हैश पर फ़ील्ड, या JSON दस्तावेज़ से JSON मान) को विभिन्न मापदंडों के साथ अनुक्रमित करना संभव है। यहाँ एक विशिष्ट उपयोग मामला है, जिसे इस नई सुविधा द्वारा हल किया गया है:
आइए एक डेटाबेस रखते हैं जिसमें दस्तावेज़ शामिल हैं जो श्रेणियों से संबंधित हैं।
TAG प्रकार का उपयोग करके आप अपने खोज परिणामों को किसी भी श्रेणी में आसानी से फ़िल्टर कर सकते हैं:
लेकिन क्या होगा यदि आप भी श्रेणियों पर पूर्ण-पाठ खोज करने में सक्षम होना चाहते हैं?
अब तक, हैश के साथ, आपको मान को दो क्षेत्रों में डुप्लिकेट करना पड़ता था, जो दो बार मेमोरी की खपत करता था।
यह वह जगह है जहाँ FT.CREATE…AS काम से कहीं अधिक हो गया है। आइए अपने अच्छे और सरल दस्तावेज़ पर वापस आते हैं:
...और नई AS सुविधा का उपयोग करें:
…और…
बिंगो! अब हम एक टैग द्वारा फ़िल्टर कर सकते हैं, और उसी फ़ील्ड में डेटा की नकल किए बिना पूरी टेक्स्ट खोज कर सकते हैं।
क्वेरी प्रोफाइलिंग
अधिकांश रेडिस कमांड की समय जटिलता अच्छी तरह से प्रलेखित है। उदाहरण के तौर पर, एचएमजीईटी ओ (एन) की जटिलता के साथ आता है, "जहां एन अनुरोध किए जा रहे फ़ील्ड की संख्या है।" RediSearch के साथ, उन्नत प्रश्न लिखना संभव है। हालांकि, FT.SEARCH और FT.AGGREGATE कमांड की जटिलता, क्वेरी की जटिलता पर निर्भर करती है।
हम आपको यह समझने के लिए टूल देना चाहते हैं कि क्वेरी निष्पादित होने पर क्या हो रहा है, यह पता लगाने के लिए कि समय कहाँ खर्च होता है, और क्वेरी को कैसे अनुकूलित किया जा सकता है। नया FT.PROFILE कमांड एक ट्री लौटाता है जो क्वेरी को निष्पादित करने के लिए RediSearch द्वारा उपयोग किए गए मुख्य चरणों को दर्शाता है। प्रत्येक चरण के लिए, एक समय की जानकारी दी गई है।
तो जब हम एक अस्पष्ट खोज के साथ कोई प्रश्न कर रहे होते हैं तो RediSearch के अंदर क्या होता है?
एक उदाहरण देखें:
हम अपनी क्वेरी को प्रोफाइल करने के लिए तैयार हैं। आइए प्रोफाइलिंग चलाते हैं और प्रोफाइलिंग परिणाम को विघटित करते हैं।
redis.cloud:6379> FT.PROFILE idx SEARCH LIMITED QUERY "%hello%"
पहले हमें परिणाम मिलता है। यह जाँचने के लिए उपयोगी है कि प्रोफाइलिंग क्वेरी अपेक्षित रिटर्न देती है।
यहां कुल समय दिया गया है, जिसे "प्रोफ़ाइल समय" कहा जाता है, क्योंकि इसमें प्रोफ़ाइल जानकारी एकत्र करने में लगा समय शामिल होता है।
क्वेरी को पार्स करने और निष्पादन योजना बनाने में लगने वाला समय:
शब्दकोश में अस्पष्ट मिलान खोजने में बिताया गया समय यहां दिया गया है:
और अंत में, क्या आपने कभी सोचा है कि खोज परिणाम बनाने का क्या अर्थ है? हमें प्रत्येक दस्तावेज़ के लिए पूर्ण-पाठ स्कोर की गणना करने, उन्हें स्कोर के आधार पर क्रमबद्ध करने और अंत में फ़ील्ड लोड करने की आवश्यकता है। इस जानकारी से आप बाधाओं की पहचान कर सकते हैं, प्रश्नों को तेज कर सकते हैं और सर्वर के प्रदर्शन में सुधार कर सकते हैं।
कैसे शुरू करें
हम मानते हैं कि ये नई क्षमताएं एप्लिकेशन डेवलपर्स और रेडिस समुदाय के लिए गेम चेंजर हैं। यहां बताया गया है कि आप कैसे शुरुआत करते हैं।
पूर्वावलोकन की docker छवि का उपयोग करें
आरंभ करने के लिए आप निम्न डॉकटर छवि को :पूर्वावलोकन टैग के साथ खींच सकते हैं:
docker run -p 6379:6379 redis/redismod:previewवैकल्पिक रूप से, आप दोनों रिपॉजिटरी पर RC1 रिलीज़ टैग (RediSearch के लिए v2.2.0, RedisJSON के लिए v2.0.0) से संकलित कर सकते हैं और उन्हें Redis पर लोड कर सकते हैं।
एक बार जब आप ऊपर और चल रहे हों, तो आप उपरोक्त सभी आदेशों को या इस त्वरित प्रारंभ मार्गदर्शिका के साथ आज़मा सकते हैं। हम RedisMart . के बारे में ब्लॉगों की एक श्रृंखला भी शुरू करेंगे , एक ऑनलाइन रिटेल एप्लिकेशन जिसे हमने RedisConf 2021 के मुख्य वक्ता के रूप में प्रदर्शित किया था। RedisMart सर्वोत्तम ऑनलाइन रिटेल अनुभव प्रदान करने के लिए भू-वितरित तरीके से तैनात RediSearch और RedisJSON का लाभ उठाता है। इस श्रृंखला में, हम आपको इस एप्लिकेशन को बनाने के तरीके के बारे में चरण दर चरण बताएंगे।
संगत क्लाइंट के नवीनतम संस्करणों का उपयोग करके विकसित करें
ग्राहकों की निम्न सूची को वर्तमान में अपग्रेड किया जा रहा है ताकि आप एक अच्छे डेवलपर अनुभव के साथ नई सुविधाओं का उपयोग कर सकें। नवीनतम रिलीज़ और/या पुल अनुरोधों की जाँच करें (इस समय उनमें से अधिकांश मास्टर शाखाओं पर पूर्वावलोकन संस्करण का समर्थन कर रहे हैं)।
| RedisJSON | RediSearch | |
| Node.js | रेडिस-मॉड्यूल-एसडीके | रेडिस-मॉड्यूल-एसडीके |
| जावा | JredisJSON | JRediSearch |
| .NET | NRedisJSON | NRediSearch |
| पायथन | redisjson-py | redissearch-py |
समुदाय में शामिल हों
जब हम सामान्य उपलब्धता की दिशा में काम करते हैं तो हम किसी भी प्रतिक्रिया, बग रिपोर्ट, फीचर अनुरोधों का स्वागत करते हैं। दस्तावेज़ीकरण वेबसाइटों पर या RediSearch (Github पर) या RedisJSON (Github पर) के github रिपॉजिटरी में प्रतिक्रिया दें, या Discord पर हमसे संपर्क करें।