RedisTimeSeries एक Redis मॉड्यूल है जो Redis में मूल समय-श्रृंखला डेटा संरचना लाता है। समय-श्रृंखला समाधान, जो पहले सॉर्ट किए गए सेट (या रेडिस स्ट्रीम) के शीर्ष पर बनाए गए थे, रेडिसटाइमसीरीज़ सुविधाओं जैसे उच्च-वॉल्यूम सम्मिलन, कम-विलंबता रीड, लचीली क्वेरी भाषा, डाउन-सैंपलिंग, और बहुत कुछ से लाभ उठा सकते हैं!
सामान्यतया, समय-श्रृंखला डेटा (अपेक्षाकृत) सरल है। ऐसा कहने के बाद, हमें अन्य विशेषताओं को भी ध्यान में रखना होगा:
- डेटा वेग:उदा. प्रति सेकंड हज़ारों उपकरणों से सैकड़ों मीट्रिक सोचें
- वॉल्यूम (बड़ा डेटा):महीनों (यहां तक कि वर्षों) में डेटा संचय के बारे में सोचें
इस प्रकार, RedisTimeSeries जैसे डेटाबेस समग्र समाधान का एक हिस्सा मात्र हैं। आपको यह भी सोचना होगा कि एकत्र कैसे करें (निगलना), प्रक्रिया, और भेजें आपका सारा डेटा RedisTimeSeries को। आपको वास्तव में एक स्केलेबल डेटा पाइपलाइन की आवश्यकता है जो उत्पादकों और उपभोक्ताओं को अलग करने के लिए बफर के रूप में कार्य कर सके।
यहीं से अपाचे काफ्का आता है! कोर ब्रोकर के अलावा, इसमें घटकों का एक समृद्ध पारिस्थितिकी तंत्र है, जिसमें काफ्का कनेक्ट (जो इस ब्लॉग पोस्ट में प्रस्तुत समाधान वास्तुकला का एक हिस्सा है), कई भाषाओं में क्लाइंट लाइब्रेरी, काफ्का स्ट्रीम, मिरर मेकर, आदि शामिल हैं। पी> 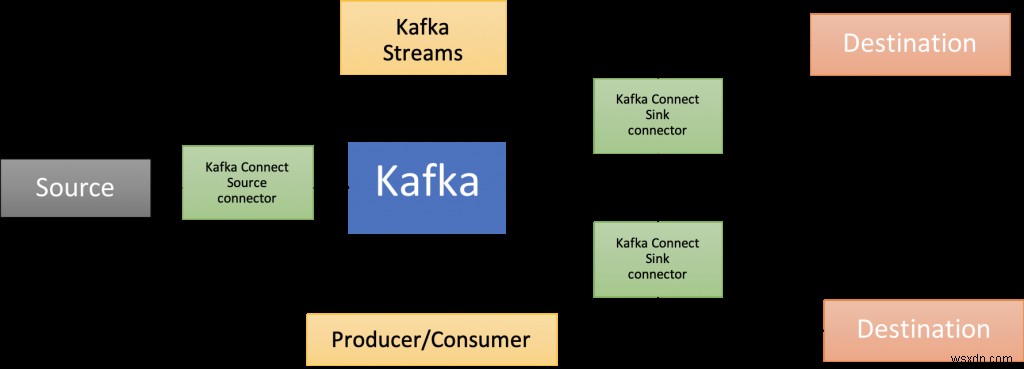
यह ब्लॉग पोस्ट समय-श्रृंखला डेटा का विश्लेषण करने के लिए अपाचे काफ्का के साथ RedisTimeSeries का उपयोग करने का एक व्यावहारिक उदाहरण प्रदान करता है।
कोड इस GitHub रेपो में उपलब्ध है https://github.com/abhirockzz/redis-timeseries-kafka
आइए पहले उपयोग के मामले की खोज करके शुरुआत करें। कृपया ध्यान दें कि ब्लॉग पोस्ट के प्रयोजनों के लिए इसे सरल रखा गया है और फिर बाद के अनुभागों में इसकी व्याख्या की गई है।
परिदृश्य:डिवाइस निगरानी
कल्पना कीजिए कि कई स्थान हैं, उनमें से प्रत्येक में कई डिवाइस हैं, और आपको डिवाइस मेट्रिक्स की निगरानी करने की जिम्मेदारी सौंपी गई है - अभी के लिए हम तापमान और दबाव पर विचार करेंगे। ये मेट्रिक्स RedisTimeSeries (बेशक!) में संग्रहीत किए जाएंगे और कुंजियों के लिए निम्नलिखित नामकरण परंपरा का उपयोग करेंगे—<मीट्रिक नाम>:<स्थान>:<डिवाइस>। उदाहरण के लिए, स्थान 5 में डिवाइस 1 के लिए तापमान को अस्थायी:5:1 के रूप में दर्शाया जाएगा। प्रत्येक समय-श्रृंखला डेटा बिंदु में निम्नलिखित लेबल (कुंजी-मूल्य जोड़े) भी होंगे-मीट्रिक, स्थान, डिवाइस। यह लचीली क्वेरी की अनुमति देने के लिए है जैसा कि आप आगामी अनुभागों में देखेंगे।
TS.ADD कमांड का उपयोग करके आप डेटा बिंदुओं को कैसे जोड़ेंगे, इसका अंदाजा लगाने के लिए यहां कुछ उदाहरण दिए गए हैं:
# लेबल के साथ स्थान 3 में डिवाइस 2 के लिए तापमान:
TS.ADD temp:3:2 * 20 LABELS metric temp location 3 device 2
# 3 स्थान पर डिवाइस 2 के लिए दबाव:
TS.ADD pressure:3:2 * 60 LABELS metric pressure location 3 device 2
समाधान संरचना
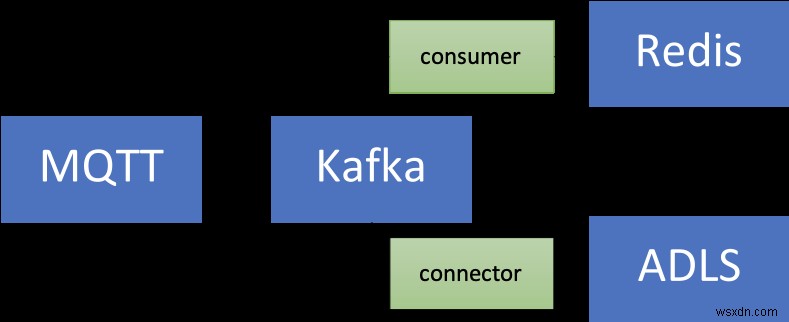
यहां बताया गया है कि उच्च स्तर पर समाधान कैसा दिखता है:
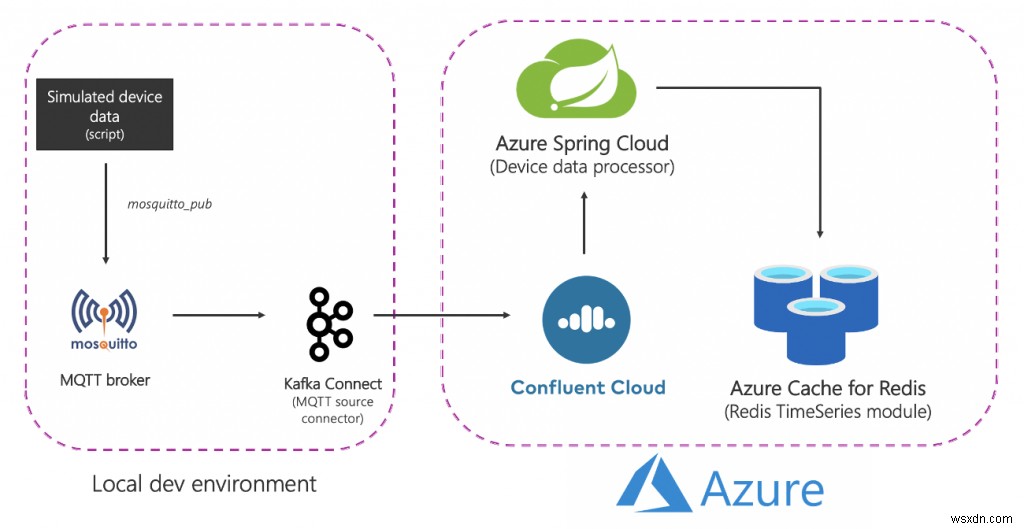
आइए इसे तोड़ दें:
स्रोत (स्थानीय) घटक
- MQTT ब्रोकर (मच्छर): MQTT IoT उपयोग के मामलों के लिए एक वास्तविक प्रोटोकॉल है। हम जिस परिदृश्य का उपयोग करेंगे, वह IoT और टाइम सीरीज़ का संयोजन है - इस पर बाद में।
- काफ्का कनेक्ट:एमक्यूटीटी स्रोत कनेक्टर का उपयोग एमक्यूटीटी ब्रोकर से डेटा को काफ्का क्लस्टर में स्थानांतरित करने के लिए किया जाता है।
Azure सेवाएं
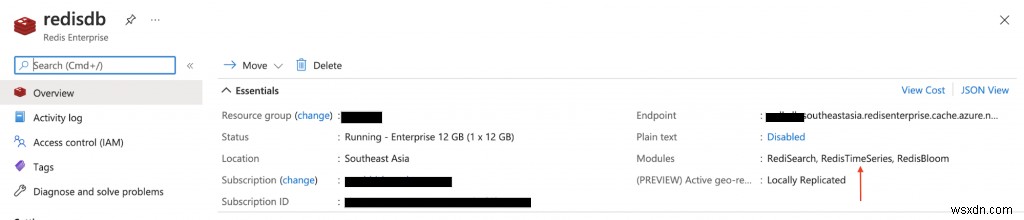
- Redis Enterprise tiers के लिए Azure Cache:Enterprise tiers Redis Enterprise पर आधारित हैं, जो Redis से Redis का एक वाणिज्यिक संस्करण है। RedisTimeSeries के अलावा, एंटरप्राइज़ टियर RediSearch और RedisBloom का भी समर्थन करता है। ग्राहकों को एंटरप्राइज़ स्तरों के लिए लाइसेंस प्राप्त करने के बारे में चिंता करने की आवश्यकता नहीं है। रेडिस के लिए एज़्योर कैश इस प्रक्रिया को सुविधाजनक बनाएगा जिसमें ग्राहक एज़्योर मार्केटप्लेस ऑफ़र के माध्यम से इस सॉफ़्टवेयर के लिए लाइसेंस प्राप्त कर सकते हैं और भुगतान कर सकते हैं।
- एज़्योर पर कंफ्लुएंट क्लाउड:पूरी तरह से प्रबंधित पेशकश जो अपाचे काफ्का को एक सेवा के रूप में प्रदान करती है, एज़्योर से कंफ्लुएंट क्लाउड तक एक एकीकृत प्रावधान परत के लिए धन्यवाद। यह क्रॉस-प्लेटफ़ॉर्म प्रबंधन के बोझ को कम करता है और एज़्योर इन्फ्रास्ट्रक्चर पर कंफ्लुएंट क्लाउड का उपयोग करने के लिए एक समेकित अनुभव प्रदान करता है, जिससे आप अपने एज़्योर एप्लिकेशन के साथ कंफ्लुएंट क्लाउड को आसानी से एकीकृत कर सकते हैं।
- Azure Spring Cloud: Azure में स्प्रिंग बूट माइक्रोसर्विसेज को परिनियोजित करना Azure Spring Cloud के लिए आसान है। एज़्योर स्प्रिंग क्लाउड बुनियादी ढांचे की चिंताओं को दूर करता है, कॉन्फ़िगरेशन प्रबंधन, सेवा खोज, सीआई/सीडी एकीकरण, ब्लू-ग्रीन परिनियोजन, और बहुत कुछ प्रदान करता है। सेवा सभी भारी भारोत्तोलन करती है ताकि डेवलपर्स अपने कोड पर ध्यान केंद्रित कर सकें।
कृपया ध्यान दें कि कुछ सेवाओं को केवल चीजों को सरल रखने के लिए स्थानीय रूप से होस्ट किया गया था। उत्पादन ग्रेड परिनियोजन में आप उन्हें Azure में भी चलाना चाहेंगे। उदाहरण के लिए आप Azure Kubernetes Service में MQTT कनेक्टर के साथ काफ्का कनेक्ट क्लस्टर संचालित कर सकते हैं।
संक्षेप में, यहाँ शुरू से अंत तक प्रवाह है:
- एक स्क्रिप्ट सिम्युलेटेड डिवाइस डेटा तैयार करती है जिसे स्थानीय MQTT ब्रोकर को भेजा जाता है।
- यह डेटा MQTT काफ्का कनेक्ट स्रोत कनेक्टर द्वारा उठाया जाता है और Azure में चल रहे कंफ्लुएंट क्लाउड काफ्का क्लस्टर में एक विषय पर भेजा जाता है।
- इसे आगे एज़्योर स्प्रिंग क्लाउड में होस्ट किए गए स्प्रिंग बूट एप्लिकेशन द्वारा संसाधित किया जाता है, जो फिर इसे रेडिस उदाहरण के लिए एज़्योर कैश में बना रहता है।
व्यावहारिक सामान के साथ शुरुआत करने का समय आ गया है! इससे पहले, सुनिश्चित करें कि आपके पास निम्नलिखित हैं।
आवश्यकताएं:
- एक Azure खाता—आप इसे यहां निःशुल्क प्राप्त कर सकते हैं
- Azure CLI इंस्टॉल करें
- JDK 11 उदा. ओपनजेडीके
- मेवेन और गिट का नवीनतम संस्करण
बुनियादी ढांचे के घटक सेट अप करें
RedisTimeSeries मॉड्यूल के साथ आने वाले Redis (Enterprise Tier) के लिए Azure Cache का प्रावधान करने के लिए दस्तावेज़ों का पालन करें।
Azure मार्केटप्लेस पर प्रोविज़न कॉन्फ़्लुएंट क्लाउड क्लस्टर। साथ ही एक काफ्का विषय बनाएं (mqtt.device-stats) and create credentials (API key and secret) that you will use later on to connect to your cluster securely.

आप Azure पोर्टल का उपयोग करके Azure स्प्रिंग क्लाउड के उदाहरण का प्रावधान कर सकते हैं या Azure CLI का उपयोग कर सकते हैं:
az spring-cloud create -n <name of Azure Spring Cloud service> -g <resource group name> -l <enter location e.g southeastasia>
आगे बढ़ने से पहले, GitHub रेपो का क्लोन बनाना सुनिश्चित करें:
git clone https://github.com/abhirockzz/redis-timeseries-kafka
cd redis-timeseries-kafkaस्थानीय सेवाओं को सेटअप करें
घटकों में शामिल हैं:
- मच्छर MQTT दलाल
- काफ्का MQTT स्रोत कनेक्टर से कनेक्ट करें
- डैशबोर्ड में समय-श्रृंखला डेटा ट्रैक करने के लिए ग्राफाना
MQTT ब्रोकर
मैंने मैक पर स्थानीय रूप से मच्छर दलाल स्थापित किया और शुरू किया।
brew install mosquitto
brew services start mosquittoआप अपने ओएस से संबंधित चरणों का पालन कर सकते हैं या इस डॉकर छवि का उपयोग करने के लिए स्वतंत्र महसूस कर सकते हैं।
ग्राफाना
मैंने Mac पर स्थानीय रूप से Grafana को स्थापित और प्रारंभ किया है।
brew install grafana
brew services start grafanaआप अपने ओएस के लिए भी ऐसा ही कर सकते हैं या इस डॉकर छवि का उपयोग करने के लिए स्वतंत्र महसूस कर सकते हैं।
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=redis-datasource" grafana/grafanaकाफ्का कनेक्ट
आपको रेपो में connect-distributed.properties फ़ाइल खोजने में सक्षम होना चाहिए जिसे आपने अभी क्लोन किया है। बूटस्ट्रैप.सर्वर, sasl.jaas.config आदि जैसे गुणों के लिए मान बदलें।
सबसे पहले, अपाचे काफ्का को स्थानीय रूप से डाउनलोड और अनज़िप करें।
स्थानीय काफ्का कनेक्ट क्लस्टर प्रारंभ करें:
export KAFKA_INSTALL_DIR=<kafka installation directory e.g. /home/foo/kafka_2.12-2.5.0>
$KAFKA_INSTALL_DIR/bin/connect-distributed.sh connect-distributed.propertiesMQTT स्रोत कनेक्टर को मैन्युअल रूप से स्थापित करने के लिए:
- इस लिंक से कनेक्टर/प्लगइन ज़िप फ़ाइल डाउनलोड करें, और,
- इसे कनेक्ट वर्कर के प्लगइन.पथ कॉन्फ़िगरेशन गुणों पर सूचीबद्ध निर्देशिकाओं में से एक में निकालें
यदि आप स्थानीय रूप से कंफ्लुएंट प्लेटफॉर्म का उपयोग कर रहे हैं, तो बस कंफ्लुएंट हब सीएलआई का उपयोग करें: confluent-hub install confluentinc/kafka-connect-mqtt:latest
MQTT स्रोत कनेक्टर इंस्टेंस बनाएं
mqtt-source-config.json फ़ाइल की जाँच करना सुनिश्चित करें। सुनिश्चित करें कि आपने kafka.topic के लिए सही विषय नाम दर्ज किया है और mqtt.topics को अपरिवर्तित छोड़ दिया है।
curl -X POST -H 'Content-Type: application/json'
http://localhost:8083/connectors -d @mqtt-source-config.json
# wait for a minute before checking the connector status
curl http://localhost:8083/connectors/mqtt-source/statusडिवाइस डेटा प्रोसेसर एप्लिकेशन परिनियोजित करें
GitHub रेपो में आपने अभी-अभी क्लोन किया है, application.yaml फ़ाइल को consumer/src/resources folder and replace the values for:
- Redis होस्ट, पोर्ट और प्राथमिक एक्सेस कुंजी के लिए Azure Cache
- Azure API कुंजी और गुप्त पर कंफ़्लुएंट क्लाउड
एप्लिकेशन JAR फ़ाइल बनाएँ:
cd consumer
export JAVA_HOME=<enter absolute path e.g. /Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home>
mvn clean packageएक Azure स्प्रिंग क्लाउड एप्लिकेशन बनाएं और उसमें JAR फ़ाइल परिनियोजित करें:
az spring-cloud app create -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --runtime-version Java_11
az spring-cloud app deploy -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --jar-path target/device-data-processor-0.0.1-SNAPSHOT.jarसिम्युलेटेड डिवाइस डेटा जेनरेटर प्रारंभ करें
आप अभी-अभी क्लोन किए गए GitHub रेपो में स्क्रिप्ट का उपयोग कर सकते हैं:
./gen-timeseries-data.shनोट—यह केवल डेटा भेजने के लिए mosquitto_pub CLI कमांड का उपयोग करता है।
डेटा डिवाइस-आंकड़े MQTT विषय पर भेजा जाता है (यह नहीं है काफ्का विषय)। आप सीएलआई सब्सक्राइबर का उपयोग करके दोबारा जांच कर सकते हैं:
mosquitto_sub -h localhost -t device-statsकंफ्लुएंट क्लाउड पोर्टल में काफ्का विषय की जाँच करें। आपको Azure स्प्रिंग क्लाउड में डिवाइस डेटा प्रोसेसर ऐप के लॉग भी देखने चाहिए:
az spring-cloud app logs -f -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group>ग्राफाना डैशबोर्ड का आनंद लें!
स्थानीय होस्ट:3000 पर Grafana UI में ब्राउज़ करें।
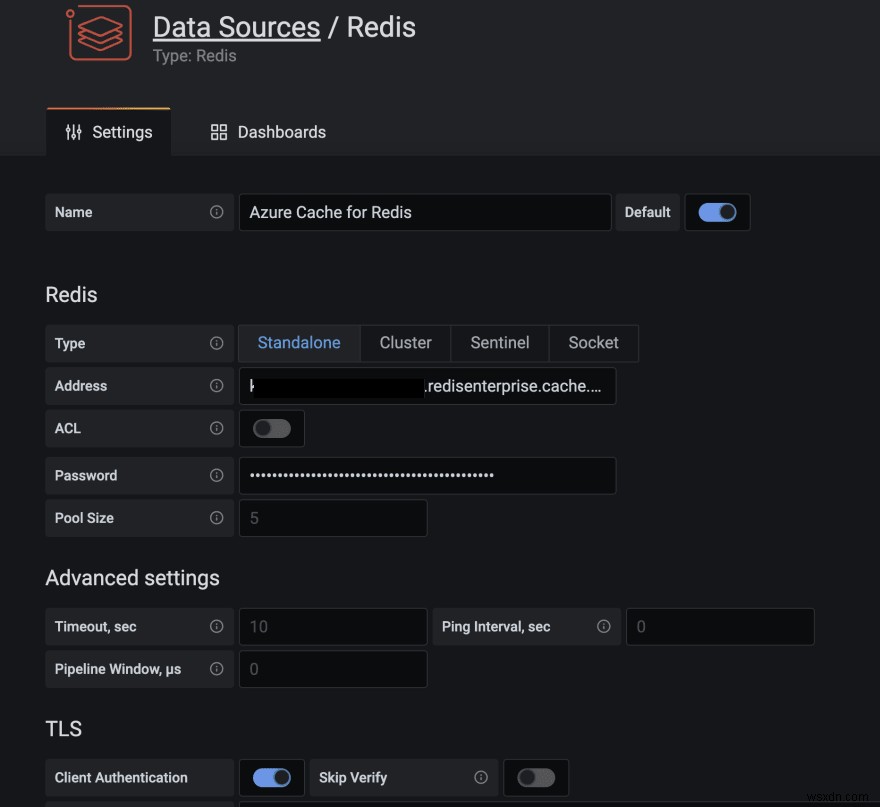
ग्राफाना के लिए रेडिस डेटा स्रोत प्लगइन रेडिस के लिए एज़ूर कैश सहित किसी भी रेडिस डेटाबेस के साथ काम करता है। डेटा स्रोत को कॉन्फ़िगर करने के लिए इस ब्लॉग पोस्ट में दिए गए निर्देशों का पालन करें।
आपके द्वारा क्लोन किए गए GitHub रेपो में grafana_dashboards फ़ोल्डर में डैशबोर्ड आयात करें (यदि आपको डैशबोर्ड आयात करने के बारे में सहायता की आवश्यकता है तो Grafana दस्तावेज़ देखें)।
उदाहरण के लिए, यहां एक डैशबोर्ड है जो स्थान 1 में डिवाइस 5 के लिए औसत दबाव (30 सेकंड से अधिक) दिखाता है (TS.MRANGE का उपयोग करता है)।
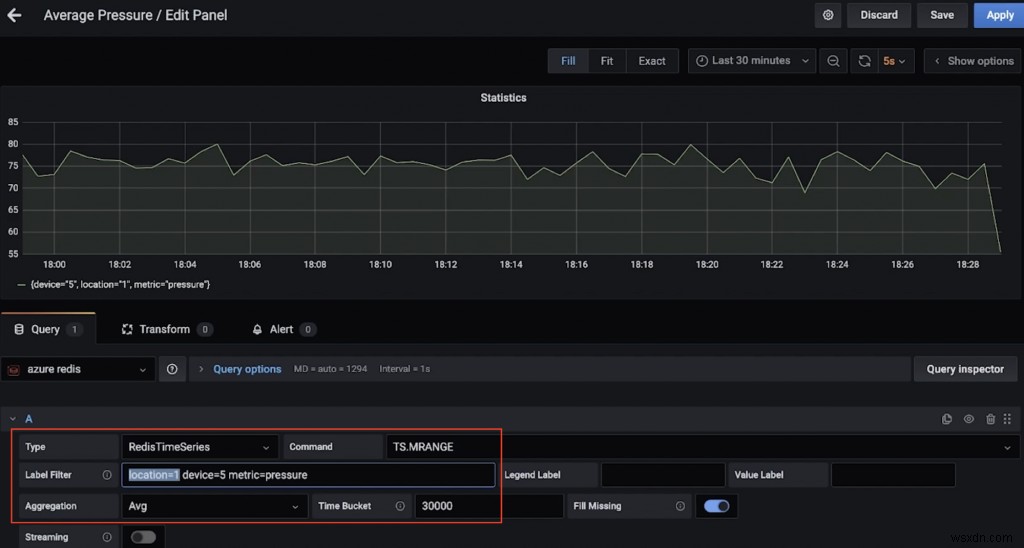
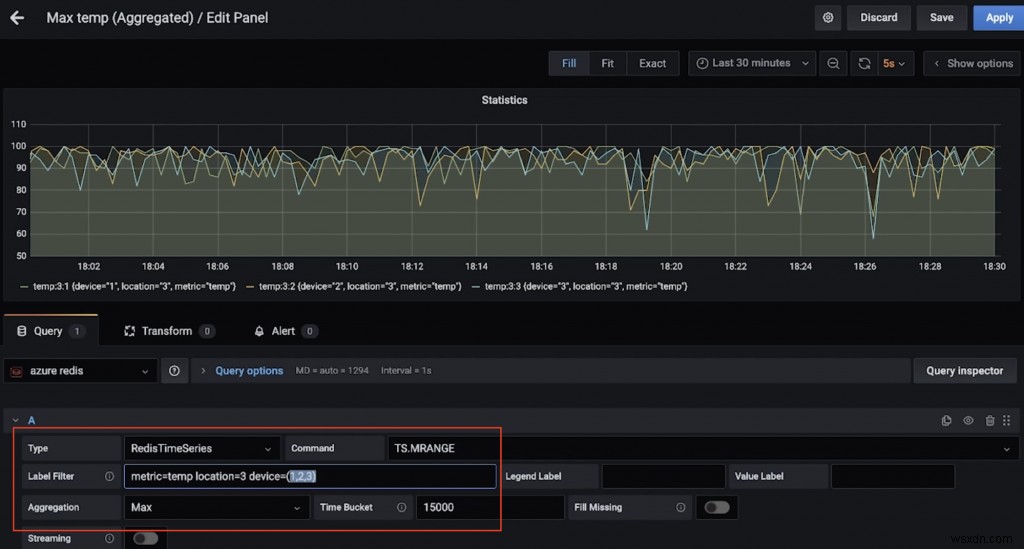
यहां एक और डैशबोर्ड है जो स्थान 3 में कई उपकरणों के लिए अधिकतम तापमान (15 सेकंड से अधिक) दिखाता है (फिर से, TS.MRANGE के लिए धन्यवाद)।
तो, आप कुछ RedisTimeSeries कमांड चलाना चाहते हैं?
रेडिस-क्ली को क्रैंक करें और रेडिस इंस्टेंस के लिए एज़्योर कैश से कनेक्ट करें:
redis-cli -h <azure redis hostname e.g. myredis.southeastasia.redisenterprise.cache.azure.net> -p 10000 -a <azure redis access key> --tlsसरल प्रश्नों से शुरू करें:
# pressure in device 5 for location 1
TS.GET pressure:1:5
# temperature in device 5 for location 4
TS.GET temp:4:5स्थान के अनुसार फ़िल्टर करें और सभी . के लिए तापमान और दबाव प्राप्त करें डिवाइस:
TS.MGET WITHLABELS FILTER location=3एक विशिष्ट समय सीमा के भीतर एक या अधिक स्थानों में सभी उपकरणों के लिए तापमान और दबाव निकालें:
TS.MRANGE - + WITHLABELS FILTER location=3
TS.MRANGE - + WITHLABELS FILTER location=(3,5)- + शुरुआत से लेकर नवीनतम टाइमस्टैम्प तक सब कुछ संदर्भित करता है, लेकिन आप अधिक विशिष्ट हो सकते हैं।
MRANGE is what we needed! We can also filter by a specific device in a location and further drill down by either temperature or pressure:
TS.MRANGE - + WITHLABELS FILTER location=3 device=2
TS.MRANGE - + WITHLABELS FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS FILTER location=3 device=2 metric=tempइन सभी को एकत्रीकरण के साथ जोड़ा जा सकता है।
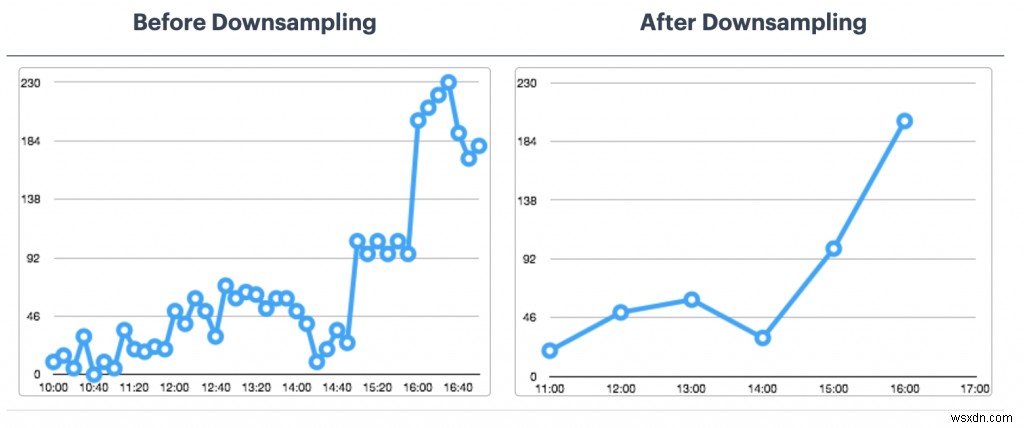
# all the temp data points are not useful. how about an average (or max) instead of every temp data points?
TS.MRANGE - + WITHLABELS AGGREGATION avg 10000 FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS AGGREGATION max 10000 FILTER location=3 metric=tempइस एकत्रीकरण को करने के लिए एक नियम बनाना और इसे एक अलग समय श्रृंखला में संग्रहीत करना भी संभव है।
काम पूरा करने के बाद, अवांछित लागतों से बचने के लिए संसाधनों को हटाना न भूलें।
संसाधन हटाएं
- कॉन्फ्लुएंट क्लाउड क्लस्टर को हटाने के लिए दस्तावेज़ में दिए गए चरणों का पालन करें—आपको बस कॉन्फ़्लुएंट संगठन को हटाना है।
- इसी तरह, आपको रेडिस इंस्टेंस के लिए एज़्योर कैशे को भी हटा देना चाहिए।
आपकी स्थानीय मशीन पर:
- काफ्का कनेक्ट क्लस्टर बंद करो
- मच्छर दलाल को रोकें (उदाहरण के लिए काढ़ा सेवाएं मच्छर को रोकें)
- ग्राफाना सेवा बंद करें (उदाहरण के लिए शराब की भठ्ठी सेवाएं बंद करो ग्राफाना)
हमने रेडिस और काफ्का का उपयोग करके समय-श्रृंखला डेटा को निगलना, संसाधित करना और क्वेरी करने के लिए एक डेटा पाइपलाइन की खोज की। जब आप अगले चरणों के बारे में सोचते हैं और उत्पादन ग्रेड समाधान की ओर बढ़ते हैं, तो आपको कुछ और बातों पर विचार करना चाहिए।
अतिरिक्त विचार
RedisTimeSeries का अनुकूलन
- अवधारण नीति:इस बारे में सोचें क्योंकि आपके समय-श्रृंखला डेटा बिंदु नहीं डिफ़ॉल्ट रूप से काट-छांट करें या हटा दें।
- डाउन-सैंपलिंग और एग्रीगेशन नियम:आप डेटा को हमेशा के लिए स्टोर नहीं करना चाहते हैं, है ना? इसका ध्यान रखने के लिए उपयुक्त नियमों को कॉन्फ़िगर करना सुनिश्चित करें (उदा. TS.CREATERULE अस्थायी:1:2 अस्थायी:औसत:30 एकत्रीकरण औसत 30000)।
- डुप्लिकेट डेटा नीति:आप डुप्लीकेट नमूनों को कैसे संभालना चाहेंगे? सुनिश्चित करें कि डिफ़ॉल्ट नीति (ब्लॉक) वास्तव में वही है जो आपको चाहिए। यदि नहीं, तो अन्य विकल्पों पर विचार करें।
यह एक विस्तृत सूची नहीं है। अन्य कॉन्फ़िगरेशन विकल्पों के लिए, कृपया RedisTimeSeries दस्तावेज़ीकरण देखें
दीर्घावधि डेटा प्रतिधारण के बारे में क्या?
डेटा कीमती है, जिसमें समय श्रृंखला भी शामिल है! आप इसे आगे संसाधित करना चाह सकते हैं (उदाहरण के लिए अंतर्दृष्टि निकालने के लिए मशीन लर्निंग चलाएं, भविष्य कहनेवाला रखरखाव, आदि)। यह संभव होने के लिए, आपको इस डेटा को लंबे समय तक बनाए रखने की आवश्यकता होगी, और इसके लिए लागत प्रभावी और कुशल होने के लिए, आप एक स्केलेबल ऑब्जेक्ट स्टोरेज सेवा जैसे Azure Data Lake Storage Gen2 (ADLS Gen2) का उपयोग करना चाहेंगे। ।
उसके लिए एक कनेक्टर है! आप ADLS में डेटा को प्रोसेस और स्टोर करने के लिए कंफ्लुएंट क्लाउड के लिए पूरी तरह से प्रबंधित Azure डेटा लेक स्टोरेज Gen2 सिंक कनेक्टर का उपयोग करके मौजूदा डेटा पाइपलाइन को बढ़ा सकते हैं और फिर Azure Synapse Analytics या Azure Databricks का उपयोग करके मशीन लर्निंग चला सकते हैं।
मापनीयता
आपकी समय-श्रृंखला डेटा वॉल्यूम केवल एक ही तरीके से आगे बढ़ सकता है—ऊपर! आपके समाधान का मापनीय होना महत्वपूर्ण है:
- मुख्य अवसंरचना:प्रबंधित सेवाएं टीमों को बुनियादी ढांचे को स्थापित करने और बनाए रखने के बजाय समाधान पर ध्यान केंद्रित करने की अनुमति देती हैं, खासकर जब यह डेटाबेस और स्ट्रीमिंग प्लेटफॉर्म जैसे रेडिस और काफ्का जैसे जटिल वितरित सिस्टम की बात आती है।
- काफ्का कनेक्ट:जहां तक डेटा पाइपलाइन का संबंध है, आप अच्छे हाथों में हैं क्योंकि काफ्का कनेक्ट प्लेटफॉर्म स्वाभाविक रूप से स्टेटलेस और क्षैतिज रूप से स्केलेबल है। आप अपने काफ्का कनेक्ट वर्कर क्लस्टर को किस तरह से आर्किटेक्ट और आकार देना चाहते हैं, इसके संदर्भ में आपके पास बहुत सारे विकल्प हैं।
- कस्टम एप्लिकेशन:जैसा कि इस समाधान में हुआ था, हमने काफ्का विषयों में डेटा को संसाधित करने के लिए एक कस्टम एप्लिकेशन बनाया। सौभाग्य से, वही मापनीयता विशेषताएँ उन पर भी लागू होती हैं। क्षैतिज पैमाने के संदर्भ में, यह केवल आपके पास काफ्का विषय विभाजन की संख्या तक सीमित है।
एकीकरण :यह सिर्फ ग्राफाना नहीं है! RedisTimeSeries प्रोमेथियस और टेलीग्राफ के साथ भी एकीकृत है। हालांकि, इस ब्लॉग पोस्ट के लिखे जाने के समय कोई काफ्का कनेक्टर नहीं था—यह एक बेहतरीन ऐड-ऑन होगा!
निष्कर्ष

निश्चित रूप से, आप समय-श्रृंखला वर्कलोड सहित (लगभग) सब कुछ के लिए रेडिस का उपयोग कर सकते हैं! डेटा पाइपलाइन के लिए एंड-टू-एंड आर्किटेक्चर के बारे में सोचना सुनिश्चित करें और समय-श्रृंखला डेटा स्रोतों से रेडिस और उससे आगे तक एकीकरण करें।