रेडिस को प्रदर्शन पर बहुत जोर देने के साथ विकसित किया गया है। हम यह सुनिश्चित करने के लिए हर रिलीज़ के साथ अपना सर्वश्रेष्ठ प्रयास करते हैं कि आप एक बहुत ही स्थिर और तेज़ उत्पाद का अनुभव करें।
फिर भी, यदि आप रेडिस की दक्षता में सुधार करने के लिए जगह ढूंढ रहे हैं या प्रदर्शन रिग्रेशन जांच कर रहे हैं, तो आपको रेडिस के प्रदर्शन की निगरानी और विश्लेषण करने के एक संक्षिप्त तरीके की आवश्यकता होगी। यह उन अनुकूलनों में से एक की कहानी है।
अंत में, हमने स्ट्रीम के अंतर्ग्रहण प्रदर्शन में लगभग 20% सुधार किया है, एक ऐसा सुधार जिसका आप पहले से ही Redis v7.0 पर लाभ उठा सकते हैं।
एक मानक विशिष्टता
ऑप्टिमाइज़ेशन में कूदने से पहले, हम आपको एक उच्च-स्तरीय विचार देना चाहते हैं कि हम इसे कैसे प्राप्त करते हैं।
जैसा कि पहले कहा गया है, हम रेडिस के प्रदर्शन प्रतिगमन और/या संभावित ऑन-सीपीयू प्रदर्शन सुधारों की पहचान करना चाहते हैं। ऐसा करने के लिए, हमने प्रदर्शन और अवलोकन आवश्यकताओं और अपेक्षाओं से संबंधित सभी मामलों पर क्रॉस-कंपनी और क्रॉस-कम्युनिटी मानकों के एक सेट को बढ़ावा देने की आवश्यकता महसूस की।
संक्षेप में, हम SPEC के बेंचमार्क को शाखा/टैग द्वारा तोड़कर लगातार चलाते हैं और परिणामी प्रदर्शन डेटा की व्याख्या करते हैं जिसमें प्रोफाइलिंग टूल/प्रोबर्स आउटपुट और क्लाइंट आउटपुट "ज़ीरो-टच" पूरी तरह से स्वचालित मोड में शामिल हैं।
उपयोग किए गए उपकरण सभी खुले स्रोत हैं और memtier_benchmark, redis-benchmark, Linux perf_events, bcc/BPF ट्रेसिंग टूल और ब्रेंडन ग्रेग के फ्लेमग्राफ रेपो जैसे टूल/लोकप्रिय ढांचे पर निर्भर हैं।
यदि आप अधिक विवरण में रुचि रखते हैं कि हम रेडिस के साथ प्रोफाइलर्स का उपयोग कैसे करते हैं, तो हम अनुशंसा करते हैं कि हमारे अत्यंत विस्तृत “ पर एक नज़र डालें। ऑन-सीपीयू प्रोफाइलिंग और ट्रेसिंग के लिए प्रदर्शन इंजीनियरिंग गाइड ।"
प्रदर्शन सुधारने के लिए डुप्लीकेट गणना से बचें
जैसे ही यह पहला कदम दिया गया, हमने प्रोफाइलिंग टूल/प्रोबर्स के आउटपुट की व्याख्या करना शुरू कर दिया। एक दिलचस्प पैटर्न प्रस्तुत करने वाले बेंचमार्क में से एक था स्ट्रीम्स का अंतर्ग्रहण बेंचमार्क जो नीचे दिए गए कमांड के समान डेटा को स्ट्रीम में सम्मिलित करता है:
`XADD key *field value`।
हमने देखा है कि आईडी के बिना स्ट्रीम में जोड़ते समय, यह एसडीएस निर्माण/फ्रीिंग/एसडीएसएलएन पर डुप्लिकेट कार्य बनाता है जिसकी लागत लगभग 10% CPU चक्रों में होती है, जैसा कि अगले दो perf रिपोर्ट प्रिंट में विस्तार से दिखाया गया है।
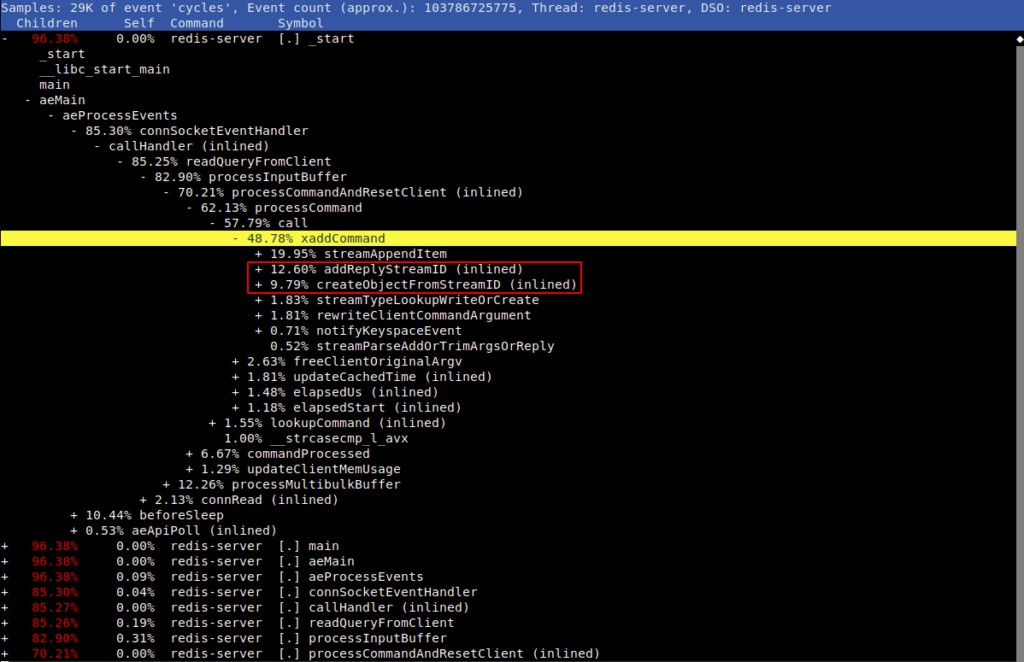
एक ही इनपुट के लिए, sdscatfmt और _sdsnewlen को दो बार कॉल किया जा रहा था:

इसने हमें निम्नलिखित बेंचमार्क परिणामों की पुष्टि के अनुसार लगभग 9-10% में स्ट्रीम अंतर्ग्रहण को अनुकूलित करने की अनुमति दी:
अस्थिर शाखा पर आधार रेखा ( 6b403f5 ) :
इस पीआर की पहली प्रतिबद्धता (डुप्लिकेट काम से बचें):

प्रदर्शन सुधारने के लिए डुप्लिकेट आवंटन से बचना
इस उपयोग-मामले में सुधार का प्रारंभिक फोकस ओरान (कोर-टीम के सदस्यों में से एक) से आगे के विश्लेषण की ओर ले जाता है, जिसने सीपीयू चक्रों की एक और बर्बादी को देखा। इस बार, यह समान कोड ब्लॉक के भीतर गैर-इष्टतम मेमोरी प्रबंधन के कारण था। हम एक खाली एसडीएस आवंटित कर रहे थे, और फिर उसे फिर से आवंटित कर रहे थे। कॉलों की संख्या कम करने से हमें गति में एक और सुधार मिलेगा, जैसा कि नीचे दिखाया गया है।
दूसरा कमिट (रीयलॉक्स से बचें):

मापा सुधार
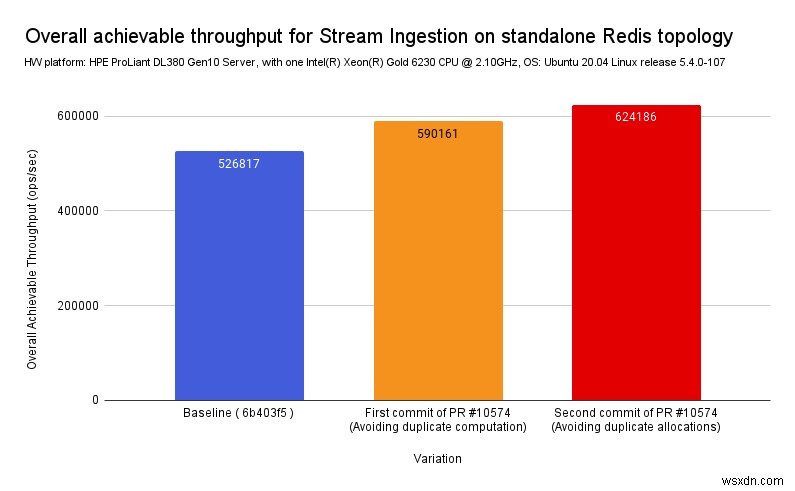
जैसा कि अपेक्षित था, केवल इंटरमीडिएट गणना का पुन:उपयोग करके और आंतरिक रूप से बुलाए गए कार्यों के भीतर अनावश्यक गणना और आवंटन को कम करके, हमने रेडिस स्ट्रीम के ~ =20% के समग्र CPU समय में कमी को माप लिया है।
हमारा मानना है कि यह एक उदाहरण है कि कैसे रेडिस जैसे पहले से ही गहराई से अनुकूलित कोड के लिए भी व्यवस्थित सरल सुधार प्रदर्शन में महत्वपूर्ण बाधा उत्पन्न कर सकते हैं।
हमारा लक्ष्य रेडिस की प्रदर्शन दृश्यता का विस्तार करना है, और संगठनों और व्यक्तियों सहित उद्योग और अकादमिक दोनों के सदस्यों को योगदान देने के लिए प्रोत्साहित किया जाता है। अगर हम इसे नहीं मापते हैं, तो हम इसे सुधार नहीं सकते हैं।