रूबी को इतनी शक्तिशाली, गतिशील भाषा बनाने के लिए एन्यूमरेटर्स के दिल में हैं। और आलसी प्रगणक आपको अत्यधिक बड़े संग्रहों के साथ कुशलतापूर्वक कार्य करने की अनुमति देकर इसे एक कदम आगे ले जाते हैं।
फ़ाइलें - यह पता चला है - बस लाइनों या पात्रों का बड़ा संग्रह है। इसलिए आलसी प्रगणक अपने साथ कुछ बहुत ही रोचक और शक्तिशाली चीजों को संभव बनाते हैं।
एन्यूमरेटर क्या है?
हर बार जब आप each . जैसी विधि का उपयोग करते हैं , आप एक गणक बनाते हैं। यही कारण है कि आप [1,2,3].map { ... }.reduce { ... } जैसी विधियों को एक साथ जोड़ सकते हैं। . आप नीचे दिए गए उदाहरण में मेरा क्या मतलब देख सकते हैं। कॉल करना each एक एन्यूमरेटर लौटाता है, जिसका उपयोग मैं अन्य पुनरावृत्त संचालन करने के लिए कर सकता हूं।
# I swiped this code from Ruby's documentation http://ruby-doc.org/core-2.2.0/Enumerator.html
enumerator = %w(one two three).each
puts enumerator.class # => Enumerator
enumerator.each_with_object("foo") do |item, obj|
puts "#{obj}: #{item}"
end
# foo: one
# foo: two
# foo: three
आलसी गणक बड़े संग्रह के लिए होते हैं
सामान्य प्रगणकों को बड़े संग्रह में समस्या होती है। कारण यह है कि आपके द्वारा कॉल की जाने वाली प्रत्येक विधि पूरे संग्रह पर पुनरावृति करना चाहती है। आप निम्न कोड चलाकर इसे स्वयं देख सकते हैं:
# This code will "hang" and you'll have to ctrl-c to exit
(1..Float::INFINITY).reject { |i| i.odd? }.map { |i| i*i }.first(5)
reject विधि हमेशा के लिए चलती है, क्योंकि यह अनंत संग्रह पर पुनरावृति कभी समाप्त नहीं कर सकती है।
लेकिन एक छोटे से जोड़ के साथ, कोड पूरी तरह से चलता है। अगर मैं बस lazy . को कॉल करूँ विधि, रूबी स्मार्ट काम करती है और गणना के लिए केवल उतनी ही पुनरावृत्तियां करती है जितनी आवश्यक है। इस मामले में यह केवल 10 पंक्तियाँ हैं, जो अनंत से काफी छोटी हैं।
(1..Float::INFINITY).lazy.reject { |i| i.odd? }.map { |i| i*i }.first(5)
#=> [4, 16, 36, 64, 100]
मोबी डिक की छह हज़ार कॉपी
इन फ़ाइल ट्रिक्स का परीक्षण करने के लिए, हमें एक बड़ी फ़ाइल की आवश्यकता होगी। एक इतना बड़ा कि कोई भी "आलसी होने में विफलता" स्पष्ट होगी।
मैंने प्रोजेक्ट गुटेनबर्ग से मोबी डिक डाउनलोड किया, और फिर 100 प्रतियों वाली एक टेक्स्ट फ़ाइल बनाई। हालांकि यह काफी बड़ा नहीं था। इसलिए मैंने इसे बढ़ाकर लगभग 6,000 कर दिया। इसका मतलब है कि इस समय शायद मैं दुनिया का अकेला आदमी हूं जिसके पास मोबी डिक की 6,000 प्रतियों वाली टेक्स्ट फाइल है। यह एक तरह से विनम्र है। लेकिन मैं पछताता हूं।
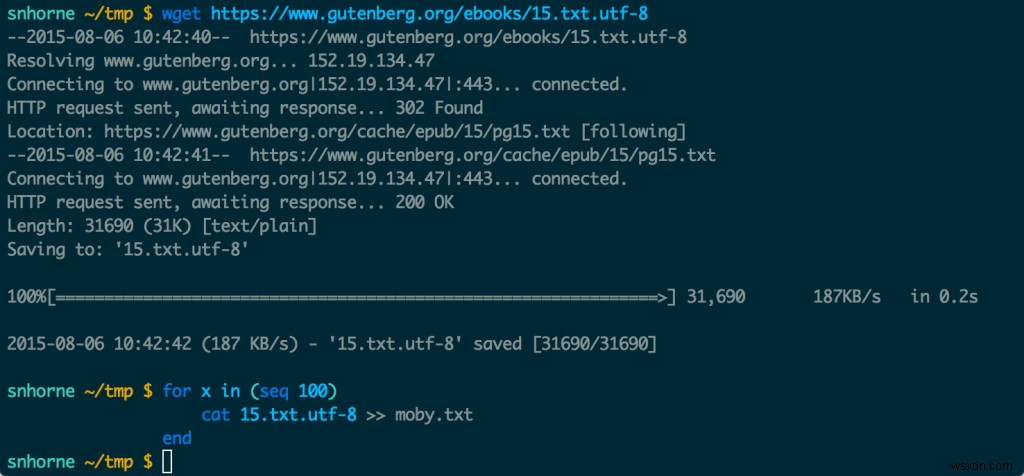 मैंने मोबी डिक डाउनलोड किया और एक बड़ी फ़ाइल के साथ खेलने के लिए इसे कई हजार बार दोहराया। वाक्यविन्यास बैश नहीं है। यह मछली का खोल है। मुझे लगता है कि इसका इस्तेमाल करने वाला मैं अकेला हूं।
मैंने मोबी डिक डाउनलोड किया और एक बड़ी फ़ाइल के साथ खेलने के लिए इसे कई हजार बार दोहराया। वाक्यविन्यास बैश नहीं है। यह मछली का खोल है। मुझे लगता है कि इसका इस्तेमाल करने वाला मैं अकेला हूं।
फ़ाइल के लिए एन्यूमरेटर कैसे प्राप्त करें
यहां एक शानदार रूबी ट्रिक है जिसका आपने शायद उपयोग किया है, भले ही आप नहीं जानते कि आप इसका उपयोग कर रहे हैं। रूबी में लगभग कोई भी विधि जो संग्रह पर पुनरावृत्त होती है, यदि आप इसे ब्लॉक में पास किए बिना कॉल करते हैं तो आपको एक एन्यूमरेटर ऑब्जेक्ट वापस कर देगा। इसका क्या मतलब है?
इस उदाहरण पर विचार करें। मैं एक फ़ाइल खोल सकता हूं, और प्रत्येक पंक्ति का उपयोग प्रत्येक पंक्ति को प्रिंट करने के लिए कर सकता हूं। लेकिन अगर मैं इसे बिना किसी ब्लॉक के कॉल करता हूं, तो मुझे एक एन्यूमरेटर मिलता है। रुचि के तरीके हैं each_line , each_char और each_codepoint ।
File.open("moby.txt") do |f|
# Print out each line in the file
f.each_line do |l|
puts l
end
# Also prints out each line in the file. But it does it
# by calling `each` on the Enumerator returned by `each_line`
f.each_line.each do |l|
puts l
end
end
ये दो उदाहरण लगभग एक जैसे दिखते हैं, लेकिन दूसरा उदाहरण अनलॉक करने की कुंजी रखता है अद्भुत शक्तियाँ ।
फ़ाइल के एन्यूमरेटर का उपयोग करना
एक बार जब आपके पास एक एन्यूमरेटर होता है जिसमें फ़ाइल में सभी पंक्तियां होती हैं, तो आप उन पंक्तियों को टुकड़ा और पासा कर सकते हैं जैसे आप किसी भी रूबी सरणी के साथ कर सकते हैं। यहां कुछ उदाहरण दिए गए हैं।
file.each_line.each_with_index.map { |line, i| "Line #{ i }: #{ line }" }[3, 10]
file.each_line.select { |line| line.size == 9 }.first(10)
file.each_line.reject { |line| line.match /whale/i }
यह वास्तव में अच्छा है, लेकिन इन सभी उदाहरणों में एक बड़ी समस्या है। वे सभी इस पर पुनरावृति करने से पहले पूरी फ़ाइल को मेमोरी में लोड करते हैं। Moby Dick की 6,000 प्रतियों वाली फ़ाइल के लिए, अंतराल ध्यान देने योग्य है।
आलसी-फ़ाइल की पंक्तियों को लोड करना
यदि हम "व्हेल" शब्द के पहले 10 उदाहरणों के लिए एक बड़ी टेक्स्ट फ़ाइल स्कैन कर रहे हैं तो वास्तव में 10वीं घटना की देखभाल करने की कोई आवश्यकता नहीं है। सौभाग्य से रूबी के गणकों को ऐसा करने के लिए कहना आसान है। आप बस "आलसी" कीवर्ड का उपयोग करें।
नीचे दिए गए उदाहरणों में, हम कुछ बहुत ही परिष्कृत चीजों को करने के लिए आलसी लोडिंग का लाभ उठाते हैं।
File.open("moby.txt") do |f|
# Get the first 3 lines with the word "whale"
f.each_line.lazy.select { |line| line.match(/whale/i) }.first(3)
# Go back to the beginning of the file.
f.rewind
# Prepend the line number to the first three lines
f.each_line.lazy.each_with_index.map do |line, i|
"LINE #{ i }: #{ line }"
end.first(3)
f.rewind
# Get the first three lines containing "whale" along with their line numbers
f.each_line.lazy.each_with_index.map { |line, i| "LINE #{ i }: #{ line }" }.select { |line| line.match(/whale/i) }.first(3)
end
यह केवल फाइलों के लिए नहीं है
सॉकेट, पाइप, सीरियल पोर्ट - वे रूबी में IO वर्ग का उपयोग करके दर्शाए जाते हैं। इसका मतलब है कि उन सभी के पास each_line है , each_char और each_codepoint तरीके। तो आप इस ट्रिक का इस्तेमाल उन सभी के लिए कर सकते हैं। बहुत साफ!
यह जादू नहीं है
दुर्भाग्य से, आलसी एन्यूमरेटर केवल चीजों को गति देते हैं यदि आप जिस कार्य को पूरा करने का प्रयास कर रहे हैं, उसके लिए पूरी फ़ाइल को पढ़ने की आवश्यकता नहीं है। यदि आप किसी ऐसे शब्द की खोज कर रहे हैं जो केवल पुस्तक के अंतिम पृष्ठ पर आता है, तो आपको उसे खोजने के लिए पूरी पुस्तक पढ़नी होगी। लेकिन उस स्थिति में यह दृष्टिकोण गैर-गणनाकर्ता दृष्टिकोण से धीमा नहीं होना चाहिए।