इस समस्या में कुछ टेक्स्ट वाली फ़ाइल है। हमें उन टेक्स्ट और एक मास्किंग इमेज से वर्ड क्लाउड बनाना है। प्रोग्राम क्लाउड इमेज शब्द को png . के रूप में संग्रहीत करेगा प्रारूप।
इस समस्या को लागू करने के लिए, हमें अजगर के कुछ पुस्तकालयों का उपयोग करने की आवश्यकता है। पुस्तकालय matplotlib, Wordcloud, numpy, tkinter और PIL हैं।
इन पुस्तकालयों को स्थापित करने के लिए, हमें इन आदेशों का पालन करना होगा -
लाइब्रेरी सेटअप करें
$ sudo pip3 install matplotlib $ sudo pip3 install wordcloud $ sudo apt-get install python3-tk
इन पुस्तकालयों को जोड़ने के बाद, हम कार्य करने के लिए पायथन कोड लिख सकते हैं।
एल्गोरिदम
Step 1: Read the data from the file and store it into ‘dataset’. Step 2: Create pixel array from the mask image. Step 3: Create the word cloud from the dataset. Set the background color, mask, and stop-words. Step 4: Store the final image into the disk.
इनपुट:sampleWords.txt फ़ाइल
पायथन एक उच्च-स्तरीय, व्याख्या की गई, संवादात्मक और वस्तु-उन्मुख स्क्रिप्टिंग भाषा है। पायथन को अत्यधिक पठनीय होने के लिए डिज़ाइन किया गया है। यह अक्सर अंग्रेजी कीवर्ड का उपयोग करता है जहां अन्य भाषाएं विराम चिह्न का उपयोग करती हैं, और इसमें अन्य भाषाओं की तुलना में कम वाक्य रचनाएं होती हैं।
पायथन को गुइडो वैन रोसुम द्वारा अस्सी के दशक के अंत और नब्बे के दशक की शुरुआत में नीदरलैंड में नेशनल रिसर्च इंस्टीट्यूट फॉर मैथमेटिक्स एंड कंप्यूटर साइंस में विकसित किया गया था।
पायथन एबीसी, मोडुला -3, सी, सी ++, एल्गोल -68, स्मॉलटॉक, और यूनिक्स शेल और अन्य स्क्रिप्टिंग भाषाओं सहित कई अन्य भाषाओं से लिया गया है।
पायथन कॉपीराइट है। पर्ल की तरह, पायथन स्रोत कोड अब जीएनयू जनरल पब्लिक लाइसेंस (जीपीएल) के तहत उपलब्ध है।
पायथन अब संस्थान में एक कोर डेवलपमेंट टीम द्वारा बनाए रखा जाता है, हालांकि गुइडो वैन रोसुम अभी भी इसकी प्रगति को निर्देशित करने में एक महत्वपूर्ण भूमिका निभाता है।
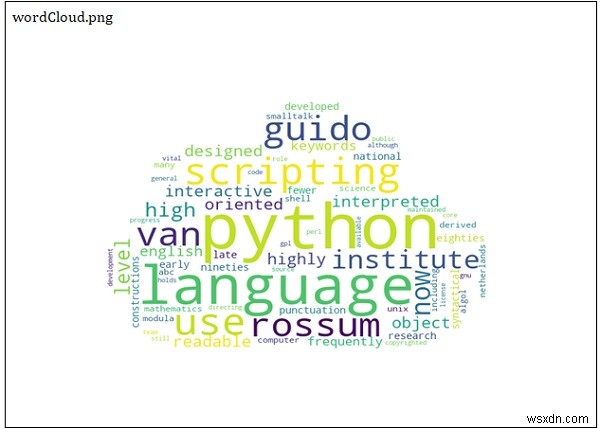
एक अन्य इनपुट मुखौटा छवि (क्लाउड.पीएनजी) है। अंतिम परिणाम दाईं ओर है।

उदाहरण कोड
import matplotlib.pyplot as pPlot
from wordcloud import WordCloud, STOPWORDS
import numpy as npy
from PIL import Image
dataset = open("sampleWords.txt", "r").read()
defcreate_word_cloud(string):
maskArray = npy.array(Image.open("cloud.png"))
cloud = WordCloud(background_color = "white", max_words = 200, mask = maskArray, stopwords = set(STOPWORDS))
cloud.generate(string)
cloud.to_file("wordCloud.png")
dataset = dataset.lower()
create_word_cloud(dataset)
आउटपुट