वेब स्क्रैपिंग न केवल डेटा विज्ञान के प्रति उत्साही बल्कि छात्रों या एक शिक्षार्थी को उत्साहित करता है, जो वेबसाइटों में गहराई से खुदाई करना चाहता है। पायथन कई वेबस्क्रैपिंग लाइब्रेरी प्रदान करता है, जिनमें शामिल हैं,
-
स्क्रैपी
-
उरलिब
-
सुंदर सूप
-
सेलेनियम
-
पायथन अनुरोध
-
एलएक्सएमएल
हम एक वेबपेज से डेटा स्क्रैप करने के लिए अजगर की एलएक्सएमएल लाइब्रेरी पर चर्चा करेंगे, जो सी में लिखी गई libxml2 एक्सएमएल पार्सिंग लाइब्रेरी के शीर्ष पर बनाया गया है, जो इसे सुंदर सूप से तेज बनाने में मदद करता है, लेकिन कुछ कंप्यूटरों पर स्थापित करना भी कठिन होता है, विशेष रूप से विंडोज़ ।
lxml इंस्टाल और इंपोर्ट करना
पाइप का उपयोग करके कमांड लाइन से lxml स्थापित किया जा सकता है,
pip install lxml
या
conda install -c anaconda lxml
एक बार lxml स्थापना पूर्ण हो जाने पर, html मॉड्यूल आयात करें, जो HTML को lxml से पार्स करता है।
>>> from lxml import html
उस पृष्ठ का स्रोत कोड प्राप्त करें जिसे आप परिमार्जन करना चाहते हैं- हमारे पास दो विकल्प हैं या तो हम अजगर अनुरोध पुस्तकालय या urllib का उपयोग कर सकते हैं और इसका उपयोग पृष्ठ के संपूर्ण HTML वाले lxml HTML तत्व ऑब्जेक्ट को बनाने के लिए कर सकते हैं। हम पृष्ठ की HTML सामग्री को डाउनलोड करने के लिए अनुरोध पुस्तकालय का उपयोग करने जा रहे हैं।
अजगर अनुरोधों को स्थापित करने के लिए, बस इस सरल आदेश को अपनी पसंद के टर्मिनल में चलाएँ -
$ pipenv install requests
याहू फाइनेंस से डेटा स्क्रैप करना
मान लीजिए कि हम google.finance या yahoo.finance से स्टॉक/इक्विटी डेटा को परिमार्जन करना चाहते हैं। याहू फाइनेंस से माइक्रोसॉफ्ट कार्पोरेशन का स्क्रीनशॉट नीचे दिया गया है,
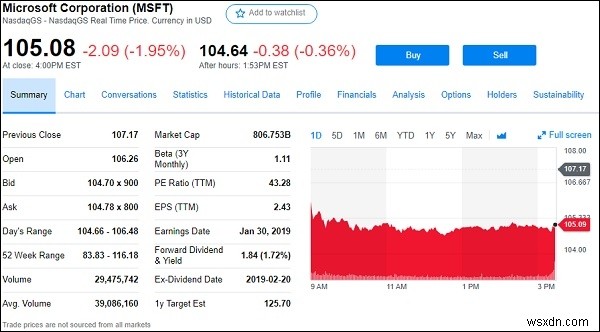
तो ऊपर से (https://finance.yahoo.com/quote/msft ), हम स्टॉक के सभी क्षेत्रों को निकालने जा रहे हैं जो ऊपर दिखाई दे रहे हैं, जैसे,
-
पिछला बंद करें, खोलें, बोली लगाएं, पूछें, दिन की सीमा, 52 सप्ताह की सीमा, मात्रा आदि।
पायथन एलएक्सएमएल मॉड्यूल का उपयोग करके इसे पूरा करने के लिए कोड नीचे दिया गया है -
lxml_scrape3.py
from lxml import html
import requests
from time import sleep
import json
import argparse
from collections import OrderedDict
from time import sleep
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s"%(ticker,ticker)
response = requests.get(url, verify = False)
print ("Parsing %s"%(url))
sleep(4)
parser = html.fromstring(response.text)
summary_table = parser.xpath('//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}? formatted=true&lang=en-
US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2
CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&
corsDomain=finance.yahoo.com".format(ticker)summary_json_response=requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
y_Target_Est = json_loaded_summary["quoteSummary"]["result"][0]["financialData"] ["targetMeanPrice"]['raw']
earnings_list = json_loaded_summary["quoteSummary"]["result"][0]["calendarEvents"]['earnings']
eps = json_loaded_summary["quoteSummary"]["result"][0]["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath('.//td[contains(@class,"C(black)")]//text()')
raw_table_value = table_data.xpath('.//td[contains(@class,"Ta(end)")]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key:table_value})
summary_data.update({'1y Target Est':y_Target_Est,'EPS (TTM)':eps,'Earnings Date':earnings_date,'ticker':ticker,'url':url})
return summary_data
except:
print ("Failed to parse json response")
return {"error":"Failed to parse json response"}
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker',help = '')
args = argparser.parse_args()
ticker = args.ticker
print ("Fetching data for %s"%(ticker))
scraped_data = parse(ticker)
print ("Writing data to output file")
with open('%s-summary.json'%(ticker),'w') as fp:
json.dump(scraped_data,fp,indent = 4) ऊपर दिए गए कोड को चलाने के लिए, अपने कमांड टर्मिनल में नीचे सरल टाइप करें -
c:\Python\Python361>python lxml_scrape3.py MSFT
lxml_scrap3.py चलाने पर आप देखेंगे, आपकी वर्तमान कार्यशील निर्देशिका में एक .json फ़ाइल बनाई गई है जिसका नाम "stockName-summary.json" जैसा कुछ है क्योंकि मैं याहू वित्त से msft (माइक्रोसॉफ्ट) फ़ील्ड निकालने का प्रयास कर रहा हूं, इसलिए एक फ़ाइल है नाम से बनाया गया - "msft-summary.json"।
नीचे दिए गए आउटपुट का स्क्रीनशॉट है -
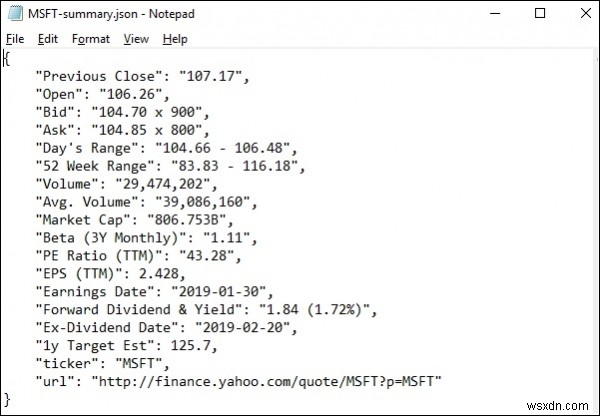
इसलिए हमने lxml और अनुरोधों का उपयोग करके Microsoft के yahoo.finance से सभी आवश्यक डेटा को सफलतापूर्वक परिमार्जन किया है और फिर डेटा को एक फ़ाइल में सहेजा है जिसे बाद में Microsoft स्टॉक के मूल्य आंदोलन को साझा या विश्लेषण करने के लिए उपयोग किया जा सकता है।