रैखिक प्रतिगमन मशीन सीखने में सबसे सरल मानक उपकरण में से एक है जो यह इंगित करता है कि दो चर के बीच सकारात्मक या नकारात्मक संबंध है या नहीं।
त्वरित भविष्य कहनेवाला विश्लेषण के लिए रैखिक प्रतिगमन कुछ अच्छे उपकरणों में से एक है। इस खंड में हम डेटा लोड करने के लिए पायथन पांडा पैकेज का उपयोग करने जा रहे हैं और फिर रैखिक प्रतिगमन मॉडल का अनुमान, व्याख्या और कल्पना कर सकते हैं।
इससे पहले कि हम और नीचे जाएं, आइए पहले चर्चा करें कि प्रतिगमन क्या है?
रिग्रेशन क्या है?
प्रतिगमन भविष्य कहनेवाला मॉडलिंग तकनीक का एक रूप है जो एक आश्रित और स्वतंत्र चर के बीच संबंध बनाने में मदद करता है।
प्रतिगमन के प्रकार
- रैखिक प्रतिगमन
- लॉजिस्टिक रिग्रेशन
- बहुपद प्रतिगमन
- चरणबद्ध प्रतिगमन
लीनियर रिग्रेशन का उपयोग कहां किया जाता है?
- रुझानों और बिक्री अनुमानों का मूल्यांकन करना
- कीमत में बदलाव के असर का विश्लेषण करना
- जोखिम का आकलन
हमारे लीनियर रिग्रेशन मॉडल को बनाने के चरण
-
सबसे पहले हम सेटअप बनाने जा रहे हैं और डेटासेट और ज्यूपिटर को डाउनलोड कर रहे हैं (जिसका उपयोग मैं इस ट्यूटोरियल के लिए कर रहा हूं, आप अन्य आईडीई जैसे एनाकोंडा या लाइक का उपयोग कर सकते हैं)।
-
आवश्यक पैकेज और डेटासेट आयात करें।
-
हमारे डेटासेट लोड होने के साथ, हम अपने डेटासेट को एक्सप्लोर करने जा रहे हैं।
-
हमारे डेटासेट के साथ लीनियर रिग्रेशन करेंगे
-
फिर हम अपने चर और दिन के समय के बीच संबंध का पता लगाएंगे।
-
सारांश।
सेटअप
आप नीचे दिए गए लिंक से डेटासेट डाउनलोड कर सकते हैं,
http://en.openei.org/datasets/dataset/649aa6d3-2832-4978-bc6e-fa563568398e/resource/b710e97d-29c9-4ca5-8137-63b7cf447317/download/build1retail.csv
जिसका उपयोग हम एक व्याख्यात्मक चर के रूप में बाहरी वायु तापमान (OAT) का उपयोग करके किसी भवन की शक्ति को मॉडल करने के लिए करने जा रहे हैं।
csv फ़ाइल को उसी फ़ोल्डर में सहेजें जहाँ हमारा jupyter या IDE स्थापित है।
आवश्यक लाइब्रेरी और डेटासेट आयात करें
सबसे पहले हम आवश्यक पुस्तकालयों को आयात करने जा रहे हैं और फिर पांडा पायथन पुस्तकालय का उपयोग करके डेटासेट को पढ़ेंगे।
# Importing Necessary Libraries
import pandas as pd
#Required for numerical functions
import numpy as np
from scipy import stats
from datetime import datetime
from sklearn import preprocessing
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
#For plotting the graph
import matplotlib.pyplot as plt
%matplotlib inline
# Reading Data
df = pd.read_csv('building1retail.csv', index_col=[0],
date_parser=lambda x: datetime.strptime(x, "%m/%d/%Y %H:%M"))
df.head() आउटपुट

डेटासेट को एक्सप्लोर करना
तो आइए सबसे पहले अपने डेटासेट को पांडा के साथ प्लॉट करके कल्पना करें।
df.plot(figsize=(22,6))
आउटपुट
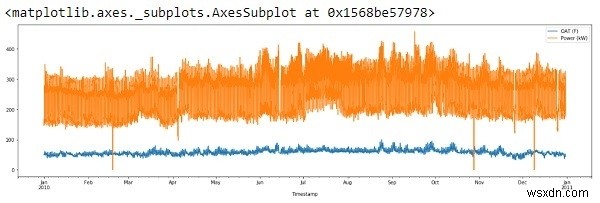
तो, एक्स-अक्ष जनवरी 2010 से जनवरी 2011 तक डेटा दिखा रहा है।
यदि हम उपरोक्त आउटपुट देखते हैं, तो हम देख सकते हैं कि प्लॉट के बारे में दो अजीब चीजें हैं:
-
ऐसा लगता है कि कोई गुम डेटा नहीं है, इसे जांचने के लिए, बस दौड़ें:
df.isnull().values.any()
आउटपुट
False
गलत परिणाम हमें बता रहा है कि डेटाफ़्रेम में कोई शून्य मान नहीं है।
-
ऐसा प्रतीत होता है, डेटा में कुछ विसंगतियां हैं (लंबे समय तक नीचे की ओर स्पाइक्स)
विसंगतियाँ या 'आउटलेयर' आम तौर पर एक प्रयोगात्मक त्रुटि का परिणाम होते हैं या सही मूल्य हो सकते हैं। किसी भी मामले में, हम इसे त्यागने जा रहे हैं क्योंकि वे प्रतिगमन रेखा के ढलान को गंभीर रूप से प्रभावित करते हैं।
इससे पहले कि हम 'आउटलेर्स' को छोड़ दें, पहले जांच लें कि हमारा डेटा किस तरह के वितरण का प्रतिनिधित्व कर रहा है:
df.hist()
आउटपुट
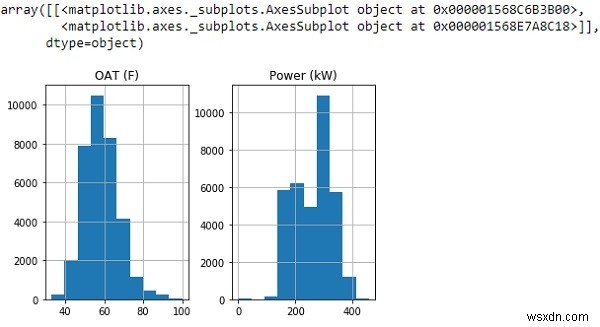
ऊपर के हिस्टोग्राम से, हम देख सकते हैं कि हमारा ग्राफ डेटा दिखा रहा है जो मोटे तौर पर एक सामान्य वितरण का अनुसरण करता है।
तो आइए उन सभी मानों को छोड़ दें जो माध्य से 3 मानक विचलन से अधिक हैं और नए डेटाफ़्रेम को प्लॉट करें।
std_dev = 3 df = df[(np.abs(stats.zscore(df)) < float(std_dev)).all(axis=1)] df.plot(figsize=(22, 6))
आउटपुट
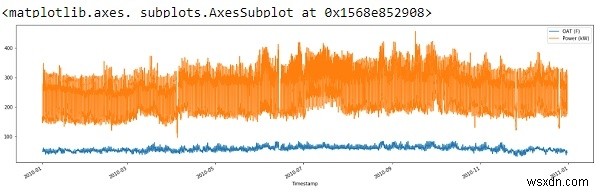
तो उपरोक्त आउटपुट से हम देख सकते हैं, हमने स्पाइक्स को कुछ हद तक हटा दिया है और अपना डेटा साफ़ कर दिया है।
रैखिक संबंध मान्य करें
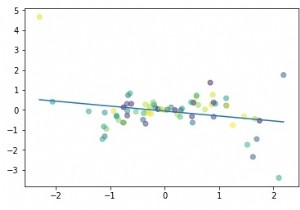
यह पता लगाने के लिए कि क्या ओएटी और पावर के बीच कोई रैखिक संबंध है, आइए एक साधारण स्कैटर प्लॉट की साजिश करें:
plt.scatter(df['OAT (F)'], df['Power (kW)'])
आउटपुट
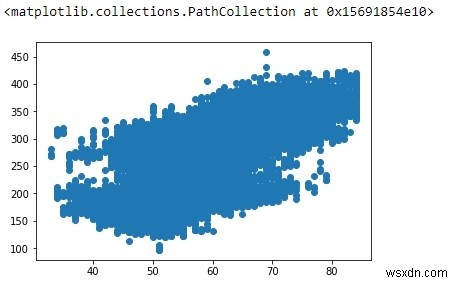
रैखिक प्रतिगमन
मॉडल चलाने और उसके प्रदर्शन का आकलन करने के लिए हम स्किकिट-लर्न मॉड्यूल का भी उपयोग करने जा रहे हैं, हम अपने मॉडल के प्रदर्शन का आकलन करने के लिए k-folds क्रॉस सत्यापन (k=3) का उपयोग करने जा रहे हैं।
X = pd.DataFrame(df['OAT (F)']) y = pd.DataFrame(df['Power (kW)']) model = LinearRegression() scores = [] kfold = KFold(n_splits=3, shuffle=True, random_state=42) for i, (train, test) in enumerate(kfold.split(X, y)): model.fit(X.iloc[train,:], y.iloc[train,:]) score = model.score(X.iloc[test,:], y.iloc[test,:]) scores.append(score) print(scores)
आउटपुट
[0.38768927735902703, 0.3852220878090444, 0.38451654781487116]
उपरोक्त कार्यक्रम में, मॉडल =रैखिक प्रतिगमन () एक रैखिक प्रतिगमन मॉडल बनाता है और लूप के लिए डेटासेट को तीन तहों में विभाजित करता है। फिर लूप के अंदर, हम डेटा को फिट करते हैं और फिर उसके स्कोर को एक सूची में जोड़कर उसके प्रदर्शन का आकलन करते हैं।
हालांकि, परिणाम अच्छे नहीं लगते हैं और हम इसके प्रदर्शन में सुधार कर सकते हैं।
दिन का समय
शक्ति (चर) दिन के समय पर अत्यधिक निर्भर है। आइए इस जानकारी का उपयोग एक-हॉट एन्कोडिंग का उपयोग करके इसे हमारे प्रतिगमन मॉडल में शामिल करने के लिए करें।
model = LinearRegression() scores = [] kfold = KFold(n_splits=3, shuffle=True, random_state=42) for i, (train, test) in enumerate(kfold.split(X, y)): model.fit(X.iloc[train,:], y.iloc[train,:]) scores.append(model.score(X.iloc[test,:], y.iloc[test,:])) print(scores)
आउटपुट
[0.8074246958895391, 0.8139449185141592, 0.8111379602960773]
हमारे मॉडल में यह एक बड़ा अंतर है।
सारांश
इस खंड में, हमने डेटासेट की खोज करने और इसे प्रतिगमन मॉडल में फिट करने के लिए तैयार करने की मूल बातें सीखीं। हमने इसके प्रदर्शन का आकलन किया, इसकी कमियों का पता लगाया और इसे ठीक किया।