इसमें हम MNIST डेटासेट का उपयोग करके हस्तलिखित डिजिट क्लासिफायर को पहचानने के लिए CNN को प्रशिक्षित करने के लिए PyTorch का उपयोग करने जा रहे हैं।
MNIST हस्तलिखित वर्गीकरण कार्य के लिए व्यापक रूप से उपयोग किया जाने वाला डेटासेट है जिसमें हस्तलिखित अंकों की 28*28 पिक्सेल ग्रेस्केल छवियों के 70k से अधिक लेबल शामिल हैं। डेटासेट में लगभग 60k प्रशिक्षण चित्र और 10k परीक्षण चित्र हैं। हमारा काम 60k प्रशिक्षण छवियों का उपयोग करके एक मॉडल को प्रशिक्षित करना है और बाद में 10k परीक्षण छवियों पर इसकी वर्गीकरण सटीकता का परीक्षण करना है।
इंस्टॉलेशन
सबसे पहले हमें एमएक्सनेट के नवीनतम संस्करण की आवश्यकता है, इसके लिए बस अपने टर्मिनल पर निम्नलिखित चलाएं:
$pip install mxnet
और आपको कुछ पसंद आएगा,
mxnet डाउनलोड करना https://files.pythonhosted.org/packages/60/6f/071f9ef51467f9f6cd35d1ad87156a29314033bbf78ad862a338b9eaf2e6/mxnet-1.2.0-py2.py3-none-win32.whl | 12.8MB 131kB/s आवश्यकता पहले से ही संतुष्ट है:c:\python\python361\lib\site-packages (mxnet से) (1.16.0) में numpy ग्राफ़विज़ एकत्र करना (mxnet से) डाउनलोड करना https://files.pythonhosted.org/packages/ 1f/e2/ef2581b5b86625657afd32030f90cf2717456c1d2b711ba074bf007c0f1a/graphviz-0.10.1-py2.py3-none-any.whl….. एकत्रित पैकेज स्थापित करना:ग्राफ़विज़, एमएक्सनेटसफलतापूर्वक स्थापित ग्राफविज़-12.0दूसरा, हमें टॉर्च और टॉर्चविज़न लाइब्रेरी की आवश्यकता है- यदि यह वह जगह नहीं है जहाँ आप इसे पाइप का उपयोग करके स्थापित कर सकते हैं।
आयात पुस्तकालय
आयात मशालआयात मशाल दृष्टिMNIST डेटासेट लोड करें
इससे पहले कि हम अपने कार्यक्रम पर काम करना शुरू करें, हमें MNIST डेटासेट की आवश्यकता है। तो चलिए इमेज और लेबल को मेमोरी में लोड करते हैं और उन हाइपरपैरामीटर को परिभाषित करते हैं जिनका उपयोग हम इस प्रयोग के लिए करेंगे।
#n_epochs कई बार होते हैं, हम संपूर्ण प्रशिक्षण डेटासेट पर लूप करेंगेn_epochs =3batch_size_train =64batch_size_test =1000# Learning_rate और गति opimizerlearning_rate =0.01momentum =0.5log_interval =10random_seed =1torch.backends.cudnn के लिए हैं। =Falsetorch.manual_seed(random_seed)अब हम TorchVision का उपयोग करके MNIST डेटासेट लोड करने जा रहे हैं। हम इस डेटासेट पर परीक्षण के लिए प्रशिक्षण के लिए 64 के बैच_साइज और आकार 1000 का उपयोग कर रहे हैं। सामान्यीकरण के लिए, हम MNIST डेटासेट के 0.1307 के माध्य मान और 0.3081 के मानक विचलन का उपयोग करेंगे।
train_loader=torch.utils.data.DataLoader(torchvision.datasets.MNIST('/files/', train=True, download=True, transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()), Torchvision.transforms.Normalize((0.1307,), (0.3081,))])), बैच_साइज=batch_size_train, shuffle=True)test_loader =torch.utils.data.DataLoader(torchvision.datasets.MNIST('/files/'), ट्रेन =झूठा, डाउनलोड =सच, ट्रांसफॉर्म =टॉर्चविजन। ट्रांसफॉर्म्स। कंपोज ([टॉर्चविजन। ट्रांसफॉर्म्स। टोटेन्सर (), टॉर्चविजन। ट्रांसफॉर्म्स। नॉर्मलाइज (0.1307,), (0.3081,))])), बैच_साइज =बैच_साइज_टेस्ट, फेरबदल =सच)आउटपुट
http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gzडाउनलोड करना http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gzडाउनलोड करना http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gzडाउनलोड करना !परीक्षण डेटा लोड करने के लिए test_loader का उपयोग करें
उदाहरण =गणना (test_loader)batch_idx, (example_data, example_targets) =अगला(उदाहरण)example_data.shapeआउटपुट
मशाल.आकार([1000, 1, 28, 28])तो आउटपुट से हम देख सकते हैं कि हमारे पास एक परीक्षण डेटा बैच है जो आकार का एक टेंसर है:[1000, 1, 28, 28] का अर्थ है- ग्रेस्केल में 28*28 पिक्सेल के 1000 उदाहरण।
आइए matplotlib का उपयोग करके कुछ डेटासेट प्लॉट करें।
आयात matplotlib.pyplot को pltfig =plt.figure() के रूप में i रेंज में(5):plt.subplot(2,3,i+1)plt.tight_layout()plt.imshow(example_data[i][0 ], cmap='ग्रे', इंटरपोलेशन='कोई नहीं')plt.title("ग्राउंड ट्रुथ:{}.format(example_targets[i]))plt.xticks([])plt.yticks([])print( अंजीर)आउटपुट
नेटवर्क बनाना
अब हम अपने नेटवर्क को 2-डी कन्वेन्शनल लेयर्स और उसके बाद दो पूरी तरह से कनेक्टेड लेयर्स का उपयोग करके बनाने जा रहे हैं। हम उस नेटवर्क के लिए एक नया वर्ग बनाने जा रहे हैं जिसे हम बनाना चाहते हैं लेकिन उससे पहले कुछ मॉड्यूल आयात करते हैं।
आयात मशाल.एनएन एनएनआईमपोर्ट मशाल के रूप में। Conv2d(1, 10, kernel_size=5) self.conv2 =nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop =nn.Dropout2d() self.fc1 =nn.Linear(320, 50) self.fc2 =nn.Linear(50, 10) def आगे(स्वयं, x):x =F.relu(F.max_pool2d(self.conv1(x), 2)) x =F.relu(F.max_pool2d(self.conv2_drop) (self.conv2(x)), 2)) x =x.view(-1, 320) x =F.relu(self.fc1(x)) x =F.ड्रॉपआउट (x, ट्रेनिंग =सेल्फ.ट्रेनिंग) x =self.fc2(x)return F.log_softmax(x)नेटवर्क और ऑप्टिमाइज़र को इनिशियलाइज़ करें:
नेटवर्क =नेट () ऑप्टिमाइज़र =ऑप्टिम। एसजीडी (नेटवर्क.पैरामीटर (), एलआर =लर्निंग_रेट, मोमेंटम =मोमेंटम)मॉडल को प्रशिक्षित करना
आइए हमारे प्रशिक्षण मॉडल का निर्माण करें। तो पहले जांचें कि हमारा नेटवर्क नेटवर्क मोड में है और फिर प्रति युग एक बार समग्र प्रशिक्षण डेटा को इंटरैक्ट करें। डेटालोडर अलग-अलग बैचों को लोड करेगा। हम ऑप्टिमाइज़र का उपयोग करके ग्रेडिएंट को शून्य पर सेट करते हैं।zero_grad()
train_losses =[]train_counter =[]test_losses =[]test_counter =[i*len(train_loader.dataset) मेरे लिए रेंज में (n_epochs + 1)]एक अच्छा प्रशिक्षण वक्र बनाने के लिए, हम प्रशिक्षण और परीक्षण हानियों को बचाने के लिए दो सूचियाँ बनाते हैं। एक्स-अक्ष पर हम प्रशिक्षण उदाहरणों की संख्या प्रदर्शित करना चाहते हैं।
बैकवर्ड () कॉल अब हम ग्रेडिएंट का एक नया सेट एकत्र करते हैं जिसे हम ऑप्टिमाइज़र.स्टेप () का उपयोग करके नेटवर्क के प्रत्येक पैरामीटर में वापस प्रचारित करते हैं।
डीईएफ़ ट्रेन (युग):बैच_आईडीएक्स के लिए नेटवर्क.ट्रेन (), (डेटा, लक्ष्य) एन्यूमरेट (ट्रेन_लोडर) में:ऑप्टिमाइज़र.ज़ीरो_ग्रेड () आउटपुट =नेटवर्क (डेटा) हानि =F.nll_loss (आउटपुट, लक्ष्य) हानि .backward() ऑप्टिमाइज़र.स्टेप() अगर बैच_आईडीएक्स% log_interval ==0:प्रिंट ('ट्रेन युग:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}'। प्रारूप (युग, बैच_आईडीएक्स * लेन (डेटा), लेन (ट्रेन_लोडर.डेटासेट), 100। बैच_आईडीएक्स*64) + ((युग-1)*लेन(train_loader.dataset))) टॉर्च /results/optimizer.pth')तटस्थ नेटवर्क मॉड्यूल, साथ ही अनुकूलक, .state_dict() का उपयोग करके अपनी आंतरिक स्थिति को सहेजने और लोड करने की क्षमता रखते हैं।
अब हमारे परीक्षण लूप के लिए, हम परीक्षण हानि का योग करते हैं और नेटवर्क की सटीकता की गणना करने के लिए सही ढंग से वर्गीकृत अंकों का ट्रैक रखते हैं।
def test():network.eval() test_loss =0 सही =0 मशाल के साथ।no_grad():डेटा के लिए, test_loader में लक्ष्य:आउटपुट =नेटवर्क (डेटा) test_loss + =F.nll_loss (आउटपुट, लक्ष्य, size_average=False).item() pred =output.data.max(1, Keepdim=True)[1] सही +=pred.eq(target.data.view_as(pred)).sum() test_loss /=len( test_loader.dataset) test_losses.append(test_loss) print('\nटेस्ट सेट:औसत हानि:{:.4f}, शुद्धता:{}/{} ({:.0f}%)\n'.format( test_loss, सही, लेन (test_loader.dataset), 100. * सही / लेन (test_loader.dataset)))प्रशिक्षण को चलाने के लिए, हम यादृच्छिक रूप से आरंभिक मापदंडों के साथ अपने मॉडल का मूल्यांकन करने के लिए n_epochs पर लूप करने से पहले एक परीक्षण () कॉल जोड़ते हैं।
टेस्ट () रेंज में युग के लिए(1, n_epochs + 1):ट्रेन(एपोच) टेस्ट ()आउटपुट
परीक्षण सेट:औसत। हानि:2.3048, सटीकता:1063/10000 (10%) ट्रेन युग:1 [0/60000 (0%)] हानि:2.294911 ट्रेन युग:1 [640/60000 (1%)] हानि:2.314225 ट्रेन युग:1 [ 1280/60000 (2%)] हानि:2.290719 ट्रेन युग:1 [1920/60000 (3%)] हानि:2.294191 ट्रेन युग:1 [2560/60000 (4%)] हानि:2.246799 ट्रेन युग:1 [3200/ 60000 (5%)] हानि:2.292224 ट्रेन युग:1 [3840/60000 (6%)] हानि:2.216632 ट्रेन युग:1 [4480/60000 (7%)] हानि:2.259646 ट्रेन युग:1 [5120/60000 ( 9%)] हानि:2.244781 ट्रेन युग:1 [5760/60000 (10%)] हानि:2.245569 ट्रेन युग:1 [6400/60000 (11%)] हानि:2.203358 ट्रेन युग:1 [7040/60000 (12%) )]नुकसान:2.192290ट्रेन युग:1 [7680/60000 (13%)]नुकसान:2.040502ट्रेन युग:1 [8320/60000 (14%)]नुकसान:2.102528ट्रेन युग:1 [8960/60000 (15%)] हानि:1.944297 ट्रेन युग:1 [9600/60000 (16%)] हानि:1.886444 ट्रेन युग:1 [10240/60000 (17%)] हानि:1.801920 ट्रेन युग:1 [10880/60000 (18%)] हानि:1.421267 ट्रेन युग:1 [11520/60000 (19%)] हानि:1.491448 ट्रेन युग:1 [12160/60000 (20%)] हानि:1.600088 ट्रेन युग:1 [12800/60000 ( 21%)] हानि:1.218677 ट्रेन युग:1 [13440/60000 (22%)] हानि:1.060651 ट्रेन युग:1 [14080/60000 (23%)] हानि:1.161512 ट्रेन युग:1 [14720/60000 (25%) )] हानि:1.351181 ट्रेन युग:1 [15360/60000 (26%)] हानि:1.012257 ट्रेन युग:1 [16000/60000 (27%)] हानि:1.018847 ट्रेन युग:1 [16640/60000 (28%)] हानि:0.944324 ट्रेन युग:1 [17280/60000 (29%)] हानि:0.929246 ट्रेन युग:1 [17920/60000 (30%)] हानि:0.903336 ट्रेन युग:1 [18560/60000 (31%)] हानि:1.243159 ट्रेन युग:1 [19200/60000 (32%)] हानि:0.696106 ट्रेन युग:1 [19840/60000 (33%)] हानि:0.902251 ट्रेन युग:1 [20480/60000 (34%)] हानि:0.986816 ट्रेन युग:1 [21120/60000 (35%)] हानि:1.203934 ट्रेन युग:1 [21760/60000 (36%)] हानि:0.682855 ट्रेन युग:1 [22400/60000 (37%)] हानि:0.65392 ट्रेन युग:1 [23040/60000 (38%)] हानि:0.932158 ट्रेन युग:1 [23680/60000 (39%)] हानि:1.110188 ट्रेन युग:1 [24320/60000 (41%)] हानि:0.817414 ट्रेन युग:1 [ 24960/60000 (42%)] हानि:0.584215 ट्रेन युग:1 [25600/60000 (43%)] हानि:0.724121 ट्रेन युग:1 [26240 60000 (44%)] हानि:0.707071 ट्रेन युग:1 [26880/60000 (45%)] हानि:0.574117 ट्रेन युग:1 [27520/60000 (46%)] हानि:0.652862 ट्रेन युग:1 [28160/60000 (47%)] हानि:0.654354 ट्रेन युग:1 [28800/60000 (48%)] हानि:0.811647 ट्रेन युग:1 [29440/60000 (49%)] हानि:0.536885 ट्रेन युग:1 [30080/60000 (500) %)] हानि:0.849961 ट्रेन युग:1 [30720/60000 (51%)] हानि:0.844555 ट्रेन युग:1 [31360/60000 (52%)] हानि:0.687859 ट्रेन युग:1 [32000/60000 (53%) ]नुकसान:0.766818 ट्रेन युग:1 [32640/60000 (54%)] हानि:0.597061 ट्रेन युग:1 [33280/60000 (55%)] हानि:0.691049 ट्रेन युग:1 [33920/60000 (57%)] हानि :0.573049 ट्रेन युग:1 [34560/60000 (58%)] हानि:0.405698 ट्रेन युग:1 [35200/60000 (59%)] हानि:0.480660 ट्रेन युग:1 [35840/60000 (60%)] हानि:0.582871 ट्रेन युग:1 [36480/60000 (61%)] हानि:0.496494 ………. ट्रेन युग:3 [49920/60000 (83%)] हानि:0.253500 ट्रेन युग:3 [50560/60000 (84%) )]नुकसान:0.364354 ट्रेन युग:3 [51200/60000 (85%)] हानि:0.333843 ट्रेन युग:3 [51840/60000 (86%)] हानि:0.096922 ट्रेन युग:3 [52480/60000 (87%)] हानि:0.282102 ट्रेन युग:3 [53120/60000 (88%)] हानि:0.236428 ट्रेन युग:3 [53760/60000 (90%)] हानि:0.610584 ट्रेन युग:3 [54400/60000 (91%)] हानि:0.198840 ट्रेन युग:3 [55040/60000 (92%)] हानि:0.344225 ट्रेन युग:3 [55680/60000 (93%)] हानि:0.158644 ट्रेन युग:3 [ 56320/60000 (94%)] हानि:0.216912 ट्रेन युग:3 [56960/60000 (95%)] हानि:0.309554 ट्रेन युग:3 [57600/60000 (96%)] हानि:0.243239 ट्रेन युग:3 [58240/ 60000 (97%)] हानि:0.176541 ट्रेन युग:3 [58880/60000 (98%)] हानि:0.456749 ट्रेन युग:3 [59520/60000 (99%)] हानि:0.318569 परीक्षण सेट:औसत। हानि:0.0912, शुद्धता:9716/10000 (97%)मॉडल के प्रदर्शन का मूल्यांकन करना
इसलिए केवल 3 अवधियों के प्रशिक्षण के साथ हम परीक्षण सेट पर 97% सटीकता प्राप्त करने में सफल रहे। बेतरतीब ढंग से आरंभिक मापदंडों के साथ, हमने प्रशिक्षण शुरू करने से पहले परीक्षण सेट पर 10% सटीकता के साथ शुरुआत की।
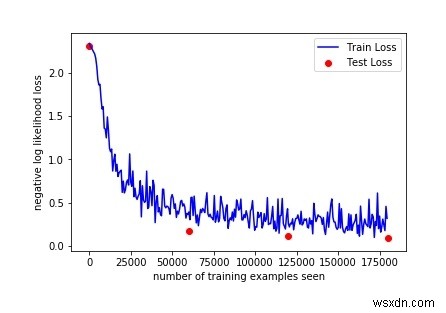
हमारे प्रशिक्षण वक्र को प्लॉट करें:
अंजीर =plt.figure()plt.plot(train_counter, train_losses, color='blue')plt.scatter(test_counter, test_losses, color='red')plt.legend(['train loss', 'Test' loss'], loc='ऊपरी दाएं')plt.xlabel('देखे गए प्रशिक्षण उदाहरणों की संख्या')plt.ylabel('negative log संभावना हानि')अंजीरआउटपुट
उपरोक्त आउटपुट की जाँच करके, हम कुछ और परिणाम देखने के लिए युगों की संख्या बढ़ा सकते हैं, क्योंकि 3 युगों की जाँच करके सटीकता बढ़ाई जाती है।
लेकिन इससे पहले, कुछ और उदाहरण चलाएँ और मॉडल के आउटपुट की तुलना करें:
torch.no_grad() के साथ:आउटपुट =नेटवर्क (example_data) fig =plt.figure() for i इन रेंज(6):plt.subplot(2,3,i+1) plt.tight_layout() plt। imshow(example_data[i][0], cmap='gray', interpolation='none') plt.title("prediction:{}.format(output.data.max(1, Keepdim=True)[1] [i].item ())) plt.xticks([]) plt.yticks([])fig
जैसा कि हम अपने मॉडल की भविष्यवाणियों को देख सकते हैं, यह उन उदाहरणों के लिए समान दिखता है।