लॉजिस्टिक रिग्रेशन बाइनरी परिणाम की भविष्यवाणी करने के लिए एक सांख्यिकीय तकनीक है। यह कोई नई बात नहीं है क्योंकि यह वर्तमान में वित्त से लेकर चिकित्सा से लेकर अपराध विज्ञान और अन्य सामाजिक विज्ञान तक के क्षेत्रों में लागू किया जा रहा है।
इस खंड में हम अजगर का उपयोग करके लॉजिस्टिक रिग्रेशन विकसित करने जा रहे हैं, हालांकि आप आर जैसी अन्य भाषाओं का उपयोग करके इसे लागू कर सकते हैं।
इंस्टॉलेशन
हम अपने उदाहरण कार्यक्रम में निम्न पुस्तकालयों का उपयोग करने जा रहे हैं,
-
बेवकूफ :संख्यात्मक सरणी और मैट्रिक्स को परिभाषित करने के लिए
-
पंडों :डेटा को संभालने और संचालित करने के लिए
-
आंकड़े मॉडल :पैरामीटर अनुमान और सांख्यिकीय परीक्षण को संभालने के लिए
-
पाइलाब :प्लॉट बनाने के लिए
आप सीएलआई में कमांड के नीचे चलाकर पाइप का उपयोग करके उपरोक्त पुस्तकालयों को स्थापित कर सकते हैं।
>पाइप इंस्टाल numpy pandas statsmodels
लॉजिस्टिक रिग्रेशन के लिए उदाहरण उपयोग केस
पायथन में हमारे लॉजिस्टिक रिग्रेशन का परीक्षण करने के लिए, हम यूसीएलए (इंस्टीट्यूट फॉर डिजिटल रिसर्च एंड एजुकेशन) द्वारा प्रदान किए गए लॉगिट रिग्रेशन डेटा का उपयोग करने जा रहे हैं। आप नीचे दिए गए लिंक से डेटा को csv प्रारूप में एक्सेस कर सकते हैं:https://stats.idre.ucla.edu/stat/data/binary.csv
मैंने इस सीएसवी फ़ाइल को अपनी स्थानीय मशीन में सहेजा है और वहां से डेटा पढ़ूंगा, आप या तो कर सकते हैं। इस सीएसवी फ़ाइल के साथ हम उन विभिन्न कारकों की पहचान करने जा रहे हैं जो स्नातक विद्यालय में प्रवेश को प्रभावित कर सकते हैं।
आवश्यक लाइब्रेरी आयात करें और डेटासेट लोड करें
हम पांडा पुस्तकालय (pandas.read_csv) का उपयोग करके डेटा को पढ़ने जा रहे हैं:
पंडों को pdimport statsmodels.api के रूप में smimport pylab के रूप में plimport numpy के रूप में npdf =pd.read_csv('binary.csv')#हम डेटा को सीधे लिंक से पढ़ सकते हैं \# df =pd.read_csv('https://stats.idre.ucla.edu/stat/data/binary.csv')print(df.head()) आउटपुट
जीपीए रैंक 0 0 380 3.61 31 1 660 3.67 32 1 800 4.00 13 1 640 3.19 44 0 520 2.93 4
जैसा कि हम उपरोक्त आउटपुट से देख सकते हैं, एक कॉलम का नाम 'रैंक' है, यह समस्या पैदा कर सकता है क्योंकि 'रैंक' भी पांडा डेटाफ्रेम में विधि का नाम है। किसी भी विवाद से बचने के लिए, मैं रैंक कॉलम का नाम बदलकर 'प्रतिष्ठा' कर रहा हूं। तो चलिए डेटासेट कॉलम का नाम बदलते हैं:
df.columns =["admit", "gre", "gpa", "prestige"]print(df.columns)
आउटपुट
Index(['admit', 'gre', 'gpa', 'prestige'], dtype='object')In [ ]:
अब सब कुछ ठीक लग रहा है, अब हम अपने डेटासेट में जो कुछ है उसे और गहराई से देख सकते हैं।
#डेटा को सारांशित करें
पांडा फ़ंक्शन का उपयोग करके वर्णन करें कि हम सब कुछ का एक संक्षिप्त दृश्य प्राप्त करेंगे।
प्रिंट(df.describe())
आउटपुट
ग्रे जीपीए प्रतिष्ठा स्वीकार करें 400.000000 400.000000 400.000000 400.00000मतलब 0.317500 587.700000 3.389900 2.48500std 0.466087 115.516536 0.380567 0.94446मिनट 0.000000 220.000000 2.260000 1.0000025%हम अपने डेटा के प्रत्येक कॉलम का मानक विचलन और फ़्रीक्वेंसी टेबल काटने की प्रतिष्ठा प्राप्त कर सकते हैं और किसी को भर्ती किया गया था या नहीं।
# प्रत्येक कॉलमप्रिंट के मानक विचलन पर एक नज़र डालें(df.std())आउटपुट
admit 0.466087gre 115.516536gpa 0.380567प्रतिष्ठा 0.944460dtype:float64उदाहरण
# फ़्रीक्वेंसी टेबल कटिंग प्रिसिट्ज और किसी को भर्ती किया गया था या नहींप्रिंट(pd.crosstab(df['admit'], df['prestige'], rownames =['admit']))आउटपुट
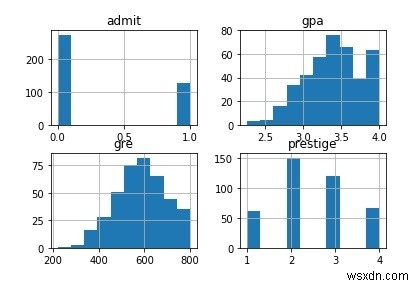
प्रतिष्ठा 1 2 3 4admit0 28 97 93 551 33 54 28 12आइए डेटासेट के सभी कॉलमों को प्लॉट करें।
# सभी कॉलमों को प्लॉट करेंdf.hist()pl.show()आउटपुट
डमी वैरिएबल
पायथन पांडा पुस्तकालय हमारे द्वारा श्रेणीबद्ध चर का प्रतिनिधित्व करने के तरीके में बहुत लचीलापन प्रदान करता है।
# dummify rankdummy_ranks =pd.get_dummies(df['prestige'], prefix='prestige')print(dummy_ranks.head())आउटपुट
प्रतिष्ठा_1 प्रतिष्ठा_2 प्रतिष्ठा_3 प्रतिष्ठा_40 0 0 1 01 0 0 1 02 1 0 0 03 0 0 0 14 0 0 0 1उदाहरण
# रिग्रेशनcols_to_keep =['admit', 'gre', 'gpa']data =df[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])आउटपुट
ग्रे जीपीए प्रतिष्ठा 2 प्रतिष्ठा_3 प्रतिष्ठा_40 0 380 3.61 0 1 01 1 660 3.67 0 1 02 1 800 4.00 0 0 03 1 640 3.19 0 0 14 0 520 2.93 0 0 1इन [ ]:प्रतिगमन करना
अब हम लॉजिस्टिक रिग्रेशन करने जा रहे हैं, जो काफी आसान है। हम केवल उस कॉलम को निर्दिष्ट करते हैं जिसमें वेरिएबल होते हैं जिनकी हम भविष्यवाणी करने का प्रयास कर रहे हैं और इसके बाद कॉलम का उपयोग मॉडल को भविष्यवाणी करने के लिए करना चाहिए।
अब हम जीआर, जीपीए और प्रेस्टीज डमी वेरिएबल्स प्रेस्टीज_2, प्रेस्टीज_3 और प्रेस्टीज_4 के आधार पर एडमिट कॉलम की भविष्यवाणी कर रहे हैं।
train_cols =data.columns[1:]# Index([gre, gpa, prestige_2, prestige_3, prestige_4], dtype=object)logit =sm.Logit(data['admit'], data[train_cols])# modelresult फिट करें =logit.fit()आउटपुट
ऑप्टिमाइज़ेशन सफलतापूर्वक समाप्त हो गया। वर्तमान फ़ंक्शन मान:0.573147Iterations 6परिणाम की व्याख्या करना
आइए statsmodels का उपयोग करके सारांश आउटपुट जेनरेट करें।
प्रिंट(result.summary2())आउटपुट
परिणाम:लॉगिट ===============================================================================================मॉडल:लॉगिट संख्या पुनरावृत्तियों:6.0000 आश्रित चर:छद्म आर-वर्ग स्वीकार करें:0.083 दिनांक:2019-03-03 14:16 एआईसी:470.5175 नहीं। अवलोकन:400 बीआईसी:494.4663 डीएफ मॉडल:5 लॉग-संभावना:-229.26 डीएफ अवशेष:394 एलएल-शून्य:-249.99 परिवर्तित:1.0000 स्केल:1.0000------------------- ------------------------------------------कोफ। कक्षा त्रुटि जेड पी>|जेड| [0.025 0.975]------------------------------------------ ------------------ग्रे 0.0023 0.0011 2.0699 0.0385 0.0001 0.0044जीपीए 0.8040 0.3318 2.4231 0.0154 0.1537 1.4544प्रतिष्ठा_2 -0.6754 0.3165 -2.1342 0.0328 -1.2958 -0.0551प्रतिष्ठा_3 -1.3402 0.3453 -3.8812 0.0001 -2.0170 -0.6634प्रतिष्ठा_4 -1.5515 0.4178 -3.7131 0.0002 -2.3704 -0.7325 अवरोध -3.9900 1.1400 -3.5001 0.0005 -6.2242 -1.7557=========================================================उपरोक्त परिणाम वस्तु हमें मॉडल आउटपुट के कुछ हिस्सों को अलग और निरीक्षण करने देती है।
#प्रत्येक गुणांक के विश्वास अंतराल को देखें(result.conf_int())आउटपुट
0 1gre 0.000120 0.004409gpa 0.153684 1.454391prestige_2 -1.295751 -0.055135prestige_3 -2.016992 -0.663416prestige_4 -2.370399 -0.732529इंटरसेप्ट -6.224242 -1.755716उपरोक्त आउटपुट से, हम देख सकते हैं कि भर्ती होने की संभावना और उम्मीदवार के स्नातक विद्यालय की प्रतिष्ठा के बीच एक विपरीत संबंध है।
इसलिए एक उम्मीदवार के स्नातक कार्यक्रम में स्वीकार किए जाने की संभावना उन छात्रों के लिए अधिक होती है, जिन्होंने निम्न रैंक वाले स्कूल (प्रतिष्ठा_3 या प्रतिष्ठा_4) के विपरीत शीर्ष रैंक वाले स्नातक कॉलेज (प्रतिष्ठा_1 =सत्य) में भाग लिया था।