इस लेख में, हम दिए गए समस्या कथन को हल करने के लिए समाधान और दृष्टिकोण के बारे में जानेंगे।
समस्या कथन
एक स्ट्रिंग इनपुट को देखते हुए, हमें दिए गए स्ट्रिंग्स में अपरकेस और लोअरकेस वर्णों की संख्या ज्ञात करनी होगी।
यहां हम बिल्ट-इन ऑर्ड () फ़ंक्शन की मदद से प्रत्येक वर्ण के ASCII मान की जाँच करेंगे।
यहां हमने दो काउंटरों को 0 पर असाइन किया है और हम इनपुट स्ट्रिंग को ट्रैवर्स कर रहे हैं और उनके ASCII मानों की जांच कर रहे हैं और उनके काउंटर को क्रमशः बढ़ा रहे हैं।
आइए अब नीचे दिए गए कार्यान्वयन को देखें -
उदाहरण
def upperlower(string):
upper = 0
lower = 0
for i in range(len(string)):
# For lowercase
if (ord(string[i]) >= 97 and
ord(string[i]) <= 122):
lower += 1
# For uppercase
elif (ord(string[i]) >= 65 and
ord(string[i]) <= 90):
upper += 1
print('Lower case characters = %s' %lower,
'Upper case characters = %s' %upper)
# Driver Code
string = 'Tutorialspoint'
upperlower(string) आउटपुट
Lower case characters = 13 Upper case characters = 1
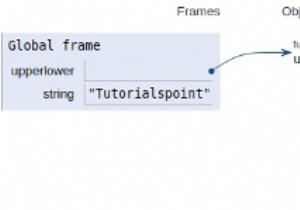
सभी चर और कार्यों को वैश्विक दायरे में घोषित किया गया है जैसा कि नीचे दिए गए चित्र में दिखाया गया है।
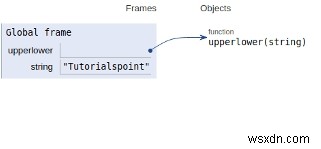
निष्कर्ष
इस लेख में, हमने इनबिल्ट फ़ंक्शंस का उपयोग किए बिना अपर और लोअर केस कैरेक्टर गिनने के दृष्टिकोण के बारे में सीखा।