प्रशिक्षण परिणामों को 'मैटप्लोटलिब' लाइब्रेरी की मदद से पायथन का उपयोग करके टेंसरफ्लो के साथ देखा जा सकता है। कंसोल पर डेटा को प्लॉट करने के लिए 'प्लॉट' पद्धति का उपयोग किया जाता है।
और पढ़ें: TensorFlow क्या है और Keras कैसे तंत्रिका नेटवर्क बनाने के लिए TensorFlow के साथ काम करता है?
हम केरस अनुक्रमिक एपीआई का उपयोग करेंगे, जो एक अनुक्रमिक मॉडल बनाने में सहायक है जिसका उपयोग परतों के एक सादे ढेर के साथ काम करने के लिए किया जाता है, जहां हर परत में एक इनपुट टेंसर और एक आउटपुट टेंसर होता है।
एक तंत्रिका नेटवर्क जिसमें कम से कम एक परत होती है, एक दृढ़ परत के रूप में जानी जाती है। हम लर्निंग मॉडल बनाने के लिए कन्वेन्शनल न्यूरल नेटवर्क का उपयोग कर सकते हैं।
एक इमेज क्लासिफायरियर एक keras.Sequential मॉडल का उपयोग करके बनाया गया है, और डेटा प्रीप्रोसेसिंग.image_dataset_from_directory का उपयोग करके लोड किया जाता है। डेटा कुशलता से डिस्क से लोड होता है। ओवरफिटिंग की पहचान की जाती है और इसे कम करने के लिए तकनीकों को लागू किया जाता है। इन तकनीकों में डेटा वृद्धि, और ड्रॉपआउट शामिल हैं। 3700 फूलों के चित्र हैं। इस डेटासेट में 5 उप निर्देशिकाएं हैं, और प्रति वर्ग एक उप निर्देशिका है। वे हैं:डेज़ी, सिंहपर्णी, गुलाब, सूरजमुखी और ट्यूलिप।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है।
उदाहरण
print("Calculating the accuracy")
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
print("Calculating the loss")
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
print("The results are being visualized")
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show() कोड क्रेडिट -https://www.tensorflow.org/tutorials/images/classification
आउटपुट
Calculating the accuracy Calculating the loss The results are being visualized
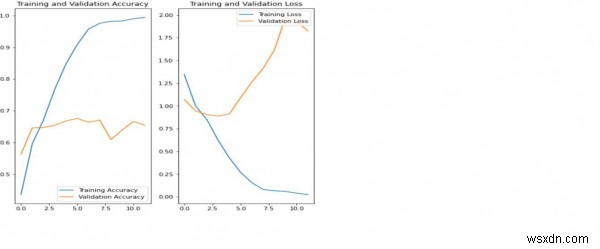
स्पष्टीकरण
-
उपरोक्त प्लॉट इंगित करते हैं कि प्रशिक्षण सटीकता और सत्यापन सटीकता सिंक में नहीं हैं।
-
मॉडल ने सत्यापन डेटासेट पर केवल लगभग 60 प्रतिशत सटीकता हासिल की है।
-
इसे ओवरफिटिंग के रूप में जाना जाता है।
-
समय के साथ प्रशिक्षण सटीकता में रैखिक रूप से वृद्धि हुई है, लेकिन प्रशिक्षण प्रक्रिया में सत्यापन सटीकता लगभग 60 प्रतिशत पर रुक गई है।
-
जब प्रशिक्षण के उदाहरणों की संख्या कम होती है, तो मॉडल शोर या प्रशिक्षण उदाहरणों से अवांछित विवरण सीखता है।
-
यह नए उदाहरणों पर मॉडल के प्रदर्शन को नकारात्मक रूप से प्रभावित करता है।
-
ओवरफिटिंग के कारण, मॉडल नए डेटासेट पर अच्छी तरह से सामान्यीकरण नहीं कर पाएगा।
-
ऐसे कई तरीके हैं जिनसे ओवरफिटिंग से बचा जा सकता है। हम ओवरफिटिंग पर काबू पाने के लिए डेटा वृद्धि का उपयोग करेंगे।