पायथन अपने विशाल संकुल पुस्तकालय के लिए जाना जाता है। पुस्तकालयों की सहायता से, हम देखेंगे कि PDF को CSV फ़ाइल में कैसे परिवर्तित किया जाए। CSV फ़ाइल कुछ और नहीं बल्कि डेटा का एक संग्रह है, जिसे पंक्तियों और स्तंभों के एक सेट के साथ तैयार किया गया है। PDF को CSV में बदलने के लिए Python लाइब्रेरी में कई पैकेज उपलब्ध हैं, लेकिन हम Tabula-py मॉड्यूल का उपयोग करेंगे। . tabula-py का प्रमुख भाग जावा में लिखा गया है जो पहले PDF दस्तावेज़ को पढ़ता है और Python DataFrame को JSON ऑब्जेक्ट में परिवर्तित करता है।
tabula-py के साथ काम करने के लिए, हमारे सिस्टम में Java पहले से इंस्टॉल होना चाहिए। पीडीएफ फाइल को सीएसवी में बदलने के लिए, हम इन चरणों का पालन करेंगे -
-
सबसे पहले, पाइप इंस्टॉल tabula-py . लिखकर आवश्यक पैकेज इंस्टॉल करें कमांड शेल में।
-
अब, read_pdf("file location", pages=number) . का उपयोग करके फ़ाइल को पढ़ें समारोह। यह डेटाफ़्रेम लौटाएगा।
-
tabula.convert_into('pdf-filename', 'name_this_file.csv',output_format="csv", pages="all") का उपयोग करके DataFrame को एक्सेल फाइल में बदलें। . यह आम तौर पर पीडीएफ फाइल को एक्सेल फाइल में एक्सपोर्ट करता है।
उदाहरण
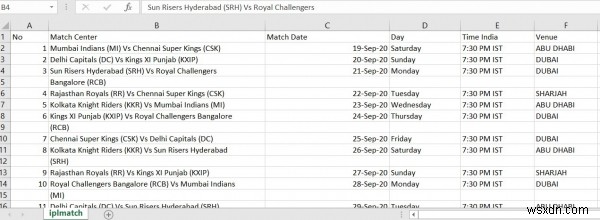
इस उदाहरण में, हमने आईपीएल मैच शेड्यूल दस्तावेज़ . का उपयोग किया है इसे एक्सेल फाइल में बदलने के लिए।
# Import the required Module
import tabula
# Read a PDF File
df = tabula.read_pdf("IPLmatch.pdf", pages='all')[0]
# convert PDF into CSV
tabula.convert_into("IPLmatch.pdf", "iplmatch.csv", output_format="csv", pages='all')
print(df) आउटपुट
उपरोक्त कोड को चलाने से पीडीएफ फाइल एक्सेल (सीएसवी) फाइल में बदल जाएगी।