सामान्य वितरण का परिचय
<पी> बेल कर्व केवल उन डेटासेट को देखने के लिए उपयोगी होते हैं जो सामान्य रूप से वितरित होते हैं। तो इससे पहले कि हम बेल कर्व्स में गोता लगाएँ, आइए एक नज़र डालें कि सामान्य वितरण का क्या मतलब है। <पी> मूल रूप से, कोई भी डेटासेट जहां मान बड़े पैमाने पर माध्य के आसपास क्लस्टर किए जाते हैं, उसे सामान्य वितरण (या गॉसियन वितरण जैसा कि इसे कभी-कभी कहा जाता है) कहा जा सकता है। कर्मचारियों के प्रदर्शन संख्या से लेकर साप्ताहिक बिक्री के आंकड़ों तक, स्वाभाविक रूप से एकत्र किए गए अधिकांश डेटासेट ऐसे ही होते हैं।बेल कर्व क्या है और यह उपयोगी क्यों है?
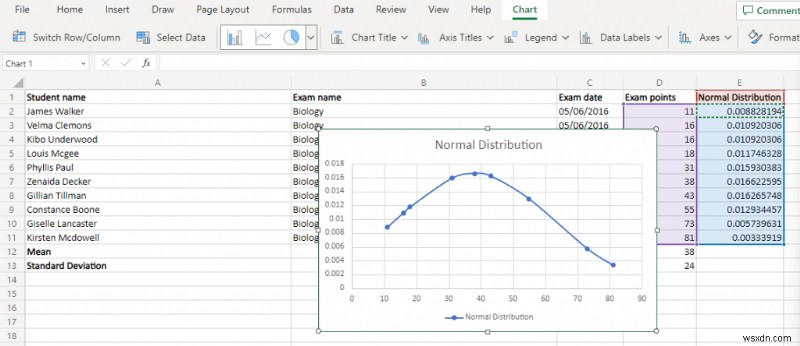
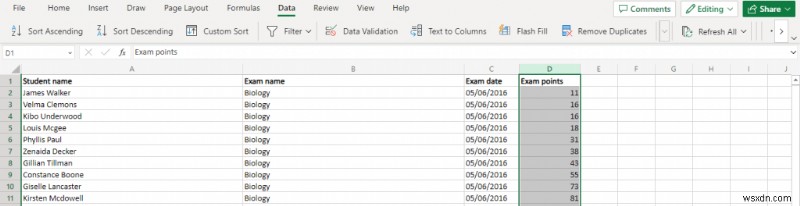
<पी> चूंकि सामान्य वितरण के डेटा बिंदुओं को माध्य के आसपास क्लस्टर किया जाता है, इसलिए प्रत्येक डेटा बिंदु के निरपेक्ष मान के बजाय केंद्रीय माध्य से भिन्नता को मापना अधिक उपयोगी होता है। और इन भिन्नताओं को एक ग्राफ के रूप में प्लॉट करने से एक बेल कर्व प्राप्त होता है। <पी> यह आपको आउटलेर्स को एक नज़र में देखने की अनुमति देता है, साथ ही औसत के संबंध में डेटा बिंदुओं के सापेक्ष प्रदर्शन को भी देखता है। कर्मचारी मूल्यांकन और छात्र स्कोर जैसी चीज़ों के लिए, यह आपको खराब प्रदर्शन करने वालों को अलग बताने की क्षमता देता है। <पी> एक्सेल में कई सरल चार्टों के विपरीत, आप केवल अपने डेटासेट पर एक विज़ार्ड चलाकर घंटी वक्र नहीं बना सकते हैं। डेटा को पहले थोड़ी प्री-प्रोसेसिंग की आवश्यकता होती है। आपको यह करना होगा:- डेटा को आरोही क्रम में क्रमबद्ध करके प्रारंभ करें। आप संपूर्ण कॉलम का चयन करके और फिर डेटा> आरोही क्रम में क्रमित करें पर जाकर यह आसानी से कर सकते हैं
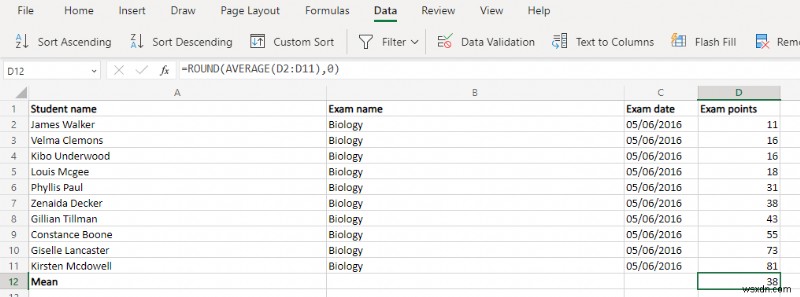
- इसके बाद, औसत फ़ंक्शन का उपयोग करके औसत मान (या माध्य) की गणना करें। चूंकि परिणाम अक्सर दशमलव में होता है, इसलिए इसे राउंड फ़ंक्शन के साथ जोड़ना भी एक अच्छा विचार है।
हमारे नमूना डेटासेट के लिए, फ़ंक्शन कुछ इस तरह दिखता है:
=राउंड(औसत(D2:D11),0)
- अब हमारे पास मानक विचलन की गणना के लिए दो कार्य हैं। STDEV.S का उपयोग तब किया जाता है जब आपके पास केवल जनसंख्या का एक नमूना होता है (आमतौर पर सांख्यिकीय अनुसंधान में) जबकि STDEV.P का उपयोग तब किया जाता है जब आपके पास संपूर्ण डेटासेट होता है। <पी> अधिकांश वास्तविक जीवन के अनुप्रयोगों (कर्मचारी मूल्यांकन, छात्र अंक, आदि) के लिए STDEV.P आदर्श है। एक बार फिर, आप पूर्ण संख्या प्राप्त करने के लिए राउंड फ़ंक्शन का उपयोग कर सकते हैं। <पी> =राउंड(STDEV.P(D2:D11),0)
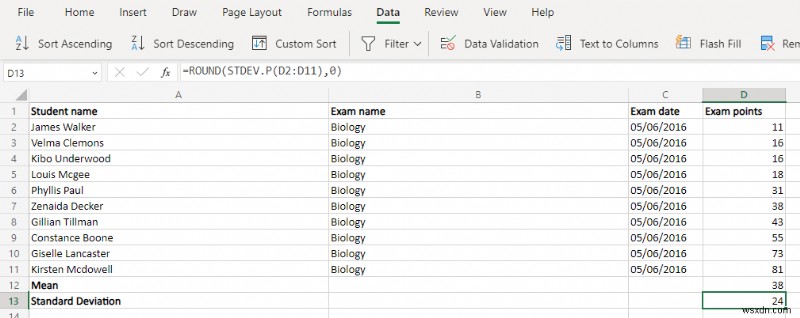
- यह सब उन वास्तविक मूल्यों के लिए तैयारी का काम था जिनकी हमें आवश्यकता है - सामान्य वितरण। बेशक, एक्सेल के पास पहले से ही इसके लिए एक समर्पित फ़ंक्शन भी है। <पी> NORM.DIST फ़ंक्शन संचयी वितरण को सक्षम करने के लिए चार तर्क लेता है - डेटा बिंदु, माध्य, मानक विचलन और एक बूलियन ध्वज। हम अंतिम को सुरक्षित रूप से अनदेखा कर सकते हैं (गलत डालकर) और हमने पहले ही माध्य और विचलन की गणना कर ली है। इसका मतलब है कि हमें बस सेल वैल्यू फीड करने की जरूरत है और हमें परिणाम मिल जाएगा। <पी> =NORM.DIST(D2,$D$12,$D$13,FALSE) <पी> इसे एक सेल के लिए करें और फिर सूत्र को पूरे कॉलम में कॉपी करें - एक्सेल स्वचालित रूप से नए स्थानों से मिलान करने के लिए संदर्भ बदल देगा। लेकिन पहले $ चिह्न का उपयोग करके माध्य और मानक विचलन सेल संदर्भों को लॉक करना सुनिश्चित करें।
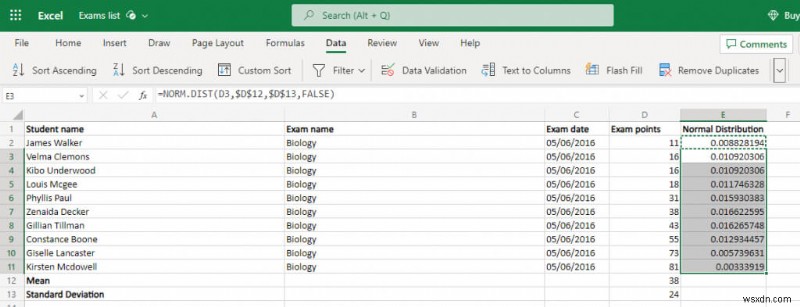
- मूल मानों के साथ इस सामान्य वितरण का चयन करें। वितरण y-अक्ष बनाएगा जबकि मूल डेटा बिंदु x-अक्ष बनाएगा।
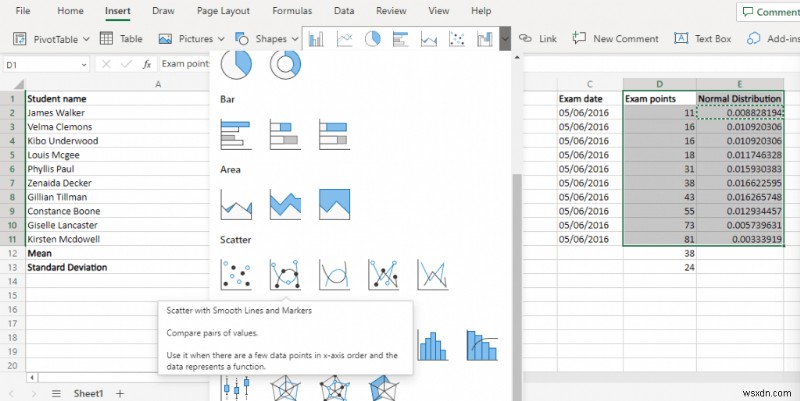
- सम्मिलित करें मेनू पर जाएं और स्कैटर आरेख पर नेविगेट करें। स्मूथ लाइन्स के साथ स्कैटर विकल्प का चयन करें।