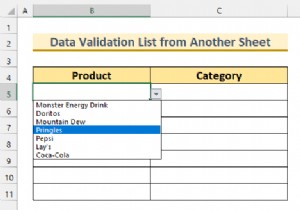
यदि आप वेबपेजों से चीजों को कॉपी और पेस्ट कर रहे हैं और मैन्युअल रूप से उन्हें स्प्रेडशीट में डाल रहे हैं, तो आप या तो नहीं जानते कि डेटा स्क्रैपिंग (या वेब स्क्रैपिंग) क्या है, या आप जानते हैं कि यह क्या है, लेकिन वास्तव में इस विचार के लिए उत्सुक नहीं हैं केवल कुछ घंटे क्लिक करने के बाद स्वयं को बचाने के लिए कोड करना सीखना।
किसी भी तरह से, बहुत सारे नो-कोड डेटा-स्क्रैपिंग टूल हैं जो आपकी मदद कर सकते हैं, और डेटा माइनर का क्रोम एक्सटेंशन अधिक सहज विकल्पों में से एक है। यदि आप भाग्यशाली हैं, तो आप जिस कार्य को करने का प्रयास कर रहे हैं, वह पहले से ही टूल की रेसिपी बुक में शामिल किया जाएगा, और आपको अपना खुद का निर्माण करने में शामिल पॉइंट-एंड-क्लिक चरणों से भी नहीं गुजरना पड़ेगा।
डेटा माइनर कैसे काम करता है?
डेटा माइनर आपके द्वारा लोड किए गए पेजों के टेक्स्ट को देखकर वेबपेजों से और अच्छी तरह से स्वरूपित एक्सेल/सीएसवी फाइलों में डेटा प्राप्त करने में आपकी सहायता करता है। इसका मतलब है कि आपको कुछ पैटर्न को पहचानने के लिए HTML के साथ कम से कम सहज होने की आवश्यकता होगी, लेकिन कुछ भी व्यापक नहीं है। उन्नत HTML और/या जावास्क्रिप्ट कौशल निश्चित रूप से कुछ कार्यों में मदद करेंगे लेकिन अधिकांश चीजों के लिए आवश्यक नहीं हैं। आपके पास कम से कम बुनियादी स्प्रेडशीट कौशल भी होना चाहिए ताकि आप सुनिश्चित हो सकें कि आपका आउटपुट साफ और व्यवस्थित है।
<एच2>1. डेटा माइनर सेट करें
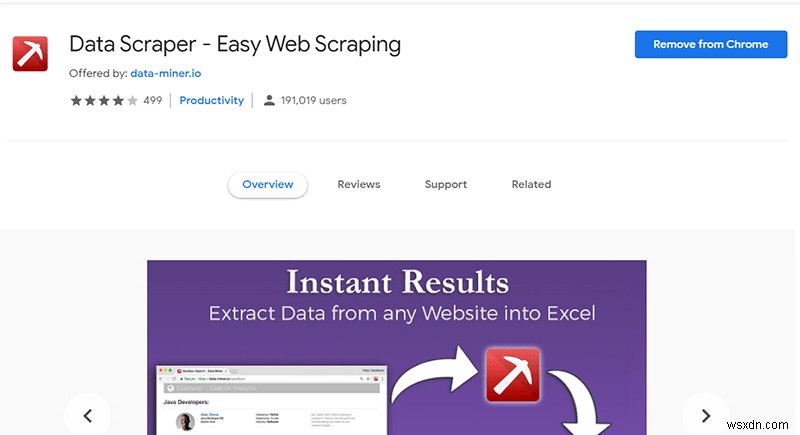
क्रोम या किसी अन्य क्रोमियम ब्राउज़र का उपयोग करके, एक्सटेंशन इंस्टॉल करें। एक्सटेंशन का पिकैक्स आइकन आपके टूलबार में दिखाई देगा, और उस पर क्लिक करने से आप उस पेज पर पहुंच जाएंगे जहां आप एक खाता सेट कर सकते हैं। मुफ़्त संस्करण आपको एक महीने में 500 स्क्रैप देता है, जो शायद आपके लिए पर्याप्त है जब तक कि यह कुछ ऐसा न हो जो आप हर दिन करते हैं।
2. डेटा लोड करें
सबसे पहले, उस पृष्ठ पर नेविगेट करें जिससे आप डेटा निकालना चाहते हैं। यदि आपके पास डेटा के कई पृष्ठ हैं या उनमें से कुछ बटन के पीछे छिपा हुआ है, तो ठीक है - इससे निपटने के तरीके हैं। अभी के लिए, आपको केवल एक प्रतिनिधि नमूने की आवश्यकता होगी ताकि कार्यक्रम को पता चले कि क्या देखना है।
3. नुस्खा के लिए जाँचें
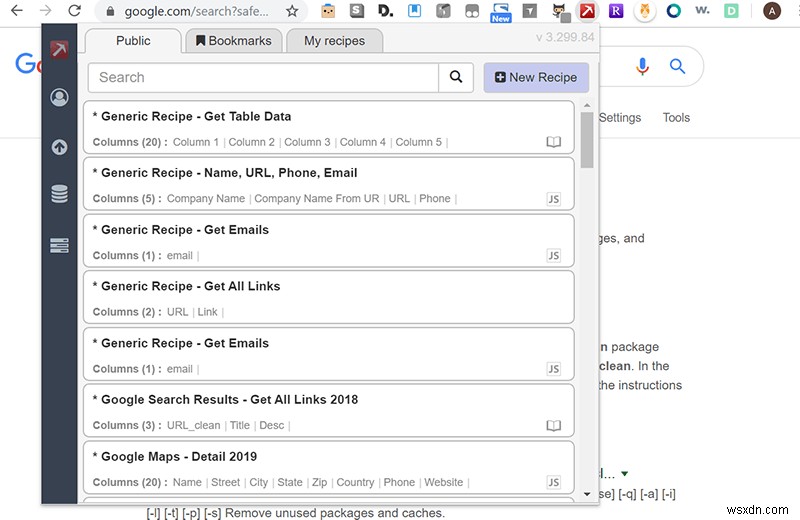
इसके बाद, डेटा माइनर खोलें और मौजूदा व्यंजनों के लिए "सार्वजनिक" टैब देखें। यदि आप किसी लोकप्रिय साइट पर हैं, तो हो सकता है कि किसी अन्य व्यक्ति ने आपके द्वारा खोजे जा रहे डेटा को प्राप्त करने के लिए पहले से ही एक प्रक्रिया बना ली हो, जिससे आपका काफी समय बचेगा। उदाहरण के लिए, Google, Amazon, और Twitter जैसी साइटों में लिंक, मूल्य, टेक्स्ट और अन्य डेटा को तुरंत डाउनलोड करने में आपकी सहायता के लिए बहुत सारी रेसिपी उपलब्ध हैं। डेटा माइनर द्वारा जेनरेट की गई स्प्रेडशीट का पूर्वावलोकन देखने के लिए आप "रन" बटन पर क्लिक करके व्यंजनों का परीक्षण कर सकते हैं। आप "संपादित करें" बटन दबाकर अपनी आवश्यकताओं के अनुरूप मौजूदा व्यंजनों को भी बदल सकते हैं।
4. पृष्ठ प्रकार
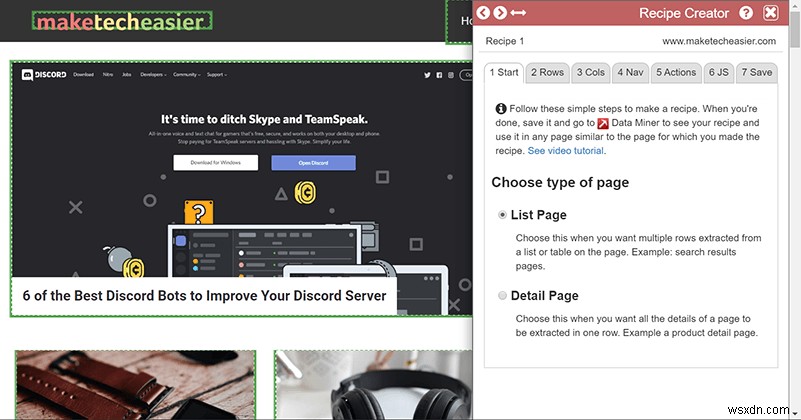
ठीक है, इसलिए किसी भी पूर्वनिर्मित रेसिपी ने आपके लिए काम नहीं किया। यह ठीक है, आप अपना बना सकते हैं। शुरू करने के लिए बस "नई रेसिपी" बटन पर क्लिक करें।
आपकी पहली पसंद "सूची पृष्ठ" या "विवरण पृष्ठ" होगी।
यदि आप एक पृष्ठ से डेटा की एकाधिक पंक्तियों को प्राप्त करने का प्रयास कर रहे हैं, तो "सूची पृष्ठ" चुनें। उदाहरण के लिए, हो सकता है कि आप प्रत्येक खोज परिणाम का लिंक और पृष्ठ शीर्षक डाउनलोड करना चाहें या किसी फ़ीड में पोस्ट की तिथि और सामग्री प्राप्त करना चाहें। यह शायद सबसे आम प्रकार है और जिसे हम यहां डेमो के रूप में उपयोग करेंगे। (विवरण पृष्ठ के चरण अनिवार्य रूप से समान हैं।)
यदि आपके पास एक ही पृष्ठ पर एक चीज़ के बारे में बहुत सी अलग-अलग जानकारी है - एक उत्पाद पृष्ठ, उदाहरण के लिए, जहां आपको इसकी कीमत, विवरण, लिंक और रेटिंग प्राप्त करने और सभी को एक पंक्ति में रखने की आवश्यकता है, तो "विवरण पृष्ठ" चुनें। ।
चरण 5:अपनी पंक्तियां बनाएं
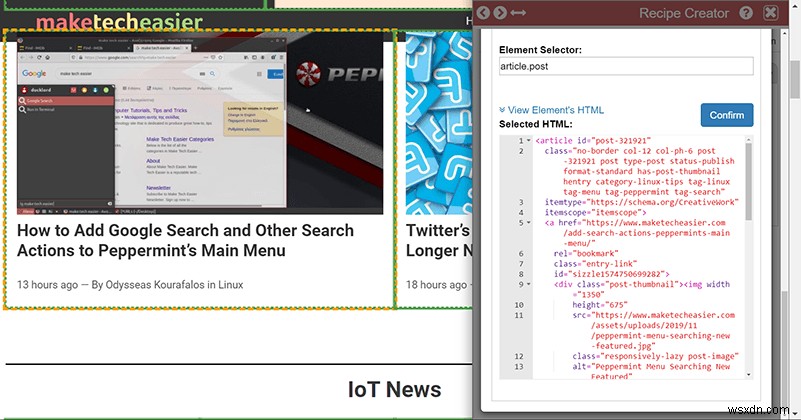
"ढूंढें" बटन दबाएं और अपने माउस को तब तक हिलाएं जब तक कि पीले चयन बॉक्स में वह सभी डेटा शामिल न हो जाए जिसकी आपको अपनी अंतिम स्प्रैडशीट में एकल प्रविष्टि के लिए आवश्यकता होगी। उदाहरण के लिए, यदि आप खोज परिणाम डाउनलोड कर रहे हैं, तो आपको शीर्षक, URL और विवरण को शामिल करने के लिए पर्याप्त बड़े क्षेत्र को हाइलाइट करना होगा, जिनमें से प्रत्येक को आप अगले चरण में अलग-अलग कॉलम में रख सकते हैं। अपना चयन करने के लिए, Shift दबाएं चाबी। यदि आप गलती से क्लिक कर देते हैं तो चिंता न करें; डेटा माइनर आपकी सभी रेसिपी प्रगति को सहेजता है, भले ही आप पेज से दूर नेविगेट करें।
फिर आप "एलिमेंट क्लासेस" या "एचटीएमएल एलिमेंट टाइप" सेक्शन में से कम से कम एक बॉक्स को चेक करना चाहेंगे। आदर्श रूप से, आप उस पृष्ठ पर प्रत्येक तत्व को कवर करने के लिए चयन को दोहराते हुए देखेंगे जो उसी श्रेणी में है जिसे आपने चुना है।
यदि आप पाते हैं कि चयनकर्ता आपकी जरूरत की हर चीज को कवर नहीं कर रहा है, तो केवल एक तत्व का चयन करने का प्रयास करें और "माता-पिता का चयन करें" दबाएं। यह बॉक्स को बड़ा बना देगा और संभवत:आपकी जरूरत की हर चीज पर कब्जा कर लेगा। यदि नहीं, तो आपको HTML में थोड़ी खोजबीन करनी पड़ सकती है और आपको आवश्यक तत्वों के वर्गों और प्रकारों की पहचान करनी पड़ सकती है। जब संदेह हो, तब तक "माता-पिता का चयन करें" को हिट करें जब तक कि बॉक्स एक से अधिक सूची प्रविष्टि को कवर किए बिना उतना बड़ा न हो जाए, क्योंकि यह आपको कॉलम का चयन करते समय अधिक लचीलापन देगा।
डेटा माइनर आपको नीचे "तत्व का HTML देखें" विकल्प देता है और आपको कस्टम चयनकर्ताओं में टाइप करने देता है। यदि आप कहना चाहते हैं, तो "उत्पाद" वर्ग वाले पृष्ठ पर सभी लिंक प्राप्त करें, आप बस a.product टाइप कर सकते हैं . यहीं पर कुछ बुनियादी HTML/CSS ज्ञान वास्तव में काम आएगा।
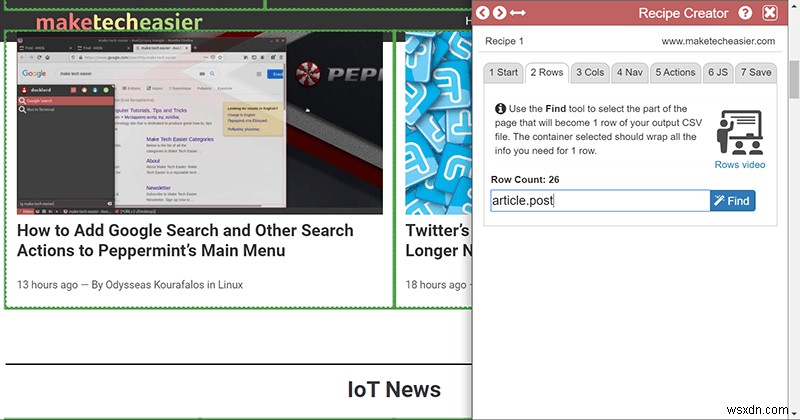
एक बार जब आप मुख्य पंक्ति मेनू पर वापस आ जाते हैं, तो आपको एक "पंक्ति गणना" दिखाई देनी चाहिए, जिसमें आपके नुस्खा द्वारा स्प्रेडशीट में बनाई जाने वाली प्रविष्टियों की संख्या होगी। अगर यह सब कुछ पकड़ नहीं रहा है, तो आपको अपनी पंक्ति चयन को दोबारा जांचना होगा।
6. अपने डेटा को कॉलम में विभाजित करें
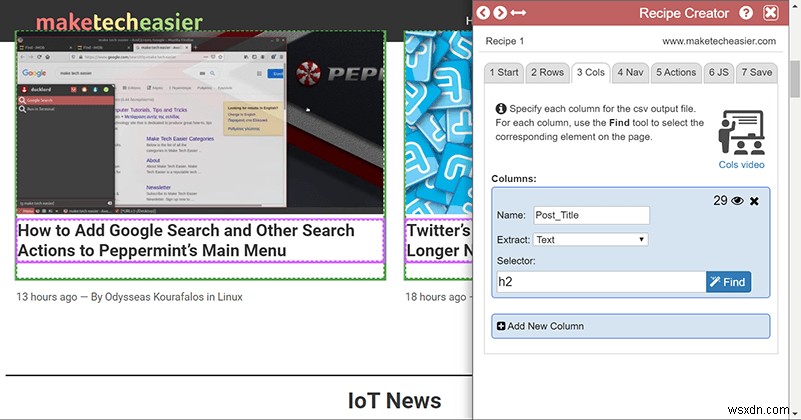
एक बार जब आप अपनी पंक्तियों के लिए सभी डेटा का चयन कर लेते हैं, तो इसे अलग-अलग कॉलम श्रेणियों में उप-विभाजित करके यह सब अच्छा दिखने का समय आ गया है। आपके द्वारा यहां किया जाने वाला प्रत्येक चयन आपके द्वारा अपनी पंक्तियों के लिए चुने गए बॉक्स का एक उपखंड होना चाहिए।
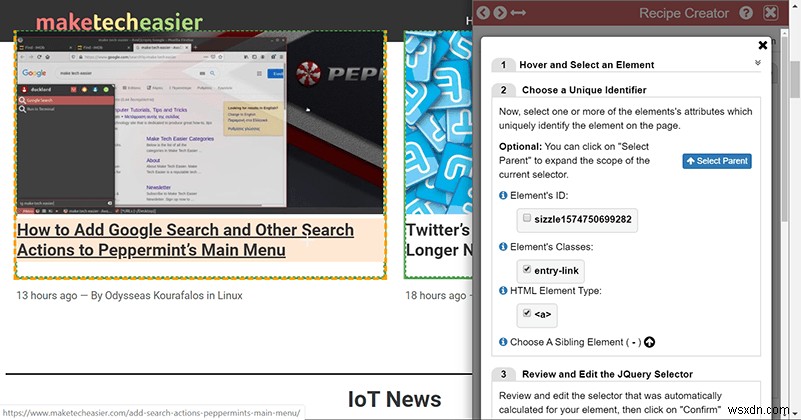
एक कॉलम बनाने के लिए, बस इसके लिए एक नाम टाइप करें और जो आप निकालना चाहते हैं उसे चुनने के लिए फाइंड बटन का उपयोग करें, ठीक उसी तरह जैसे आपने पंक्तियों के लिए किया था। सबसे आम डेटा शायद टेक्स्ट, यूआरएल या इमेज यूआरएल होगा। टेक्स्ट लिंक पर होवर करके URL प्राप्त करना थोड़ा मुश्किल हो सकता है; जब तक आप उस स्तर तक नहीं पहुंच जाते जहां तत्व प्रकार <a> है, तब तक आपको "माता-पिता का चयन करें" को दबाना पड़ सकता है। , जो लिंक के लिए HTML टैग है।
यह सुनिश्चित करने के लिए कि आपके कॉलम में सही प्रकार का डेटा है, बस प्रत्येक कॉलम के नाम के दाईं ओर आंख आइकन दबाएं, संख्या के बगल में जो आपको दिखाता है कि कितने कॉलम चुने गए हैं। यह आपको उस कॉलम के लिए प्रत्येक पंक्ति प्रविष्टि का पूर्वावलोकन दिखाएगा। यदि कुछ बंद है, तो वापस जाएं और पंक्तियों की पहचान करने के लिए आपके द्वारा चुने गए टैग और प्रकारों में बदलाव करें। HTML व्यूअर को खोलने और उस डेटा से जुड़े पैटर्न की जांच करने से न डरें, जिसे आप हथियाने की कोशिश कर रहे हैं।
7. डेटा माइनर को अगले पेज पर जाने का तरीका बताएं
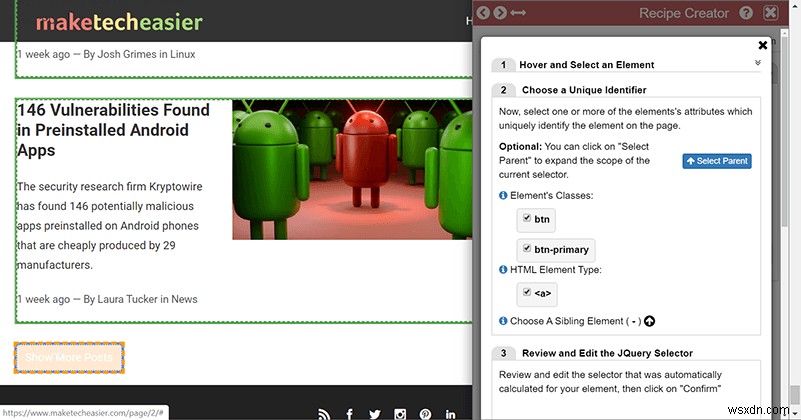
यदि आपके पास निकालने के लिए डेटा के कई पृष्ठ हैं, तो आप शायद हर एक पर क्लिक करके अपनी रेसिपी को बार-बार चलाना नहीं चाहते हैं। इसके आसपास जाने के लिए, बस डेटा माइनर को बताएं कि नेविगेशन बटन को कहां खोजना है, इसे अगले पृष्ठ पर जाने के लिए क्लिक करने की आवश्यकता है। सावधान रहें कि इसे "पेज 2" जैसी किसी चीज़ पर क्लिक करने के लिए न कहें, क्योंकि यह बस, ठीक है, पेज 2 पर जाएगा। फिर से, सुनिश्चित करें कि आप एक <a> का चयन कर रहे हैं। तत्व, और यह सुनिश्चित करने के लिए परीक्षण नेविगेशन बटन का उपयोग करें कि यह काम कर रहा है।
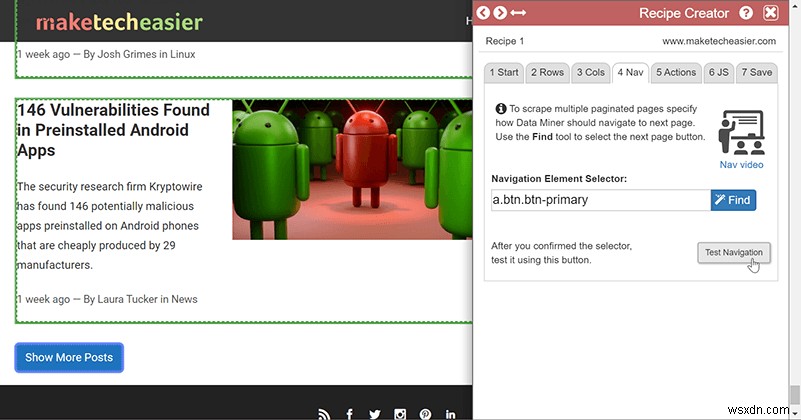
8. डेटा माइनर को बताएं कि डेटा लोड करने के लिए कहां क्लिक करना है या स्क्रॉल करना है
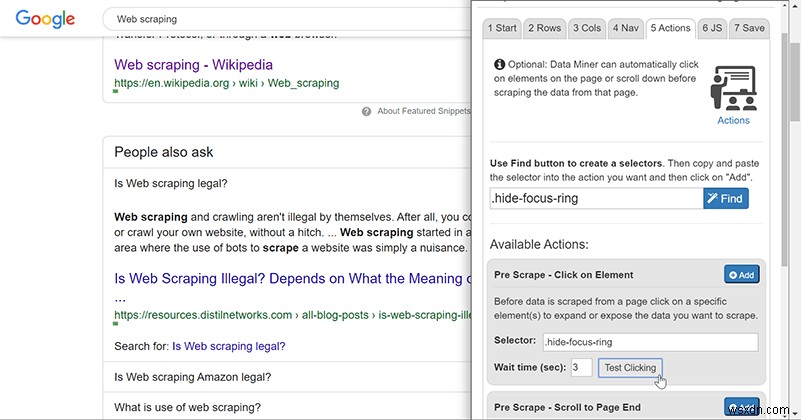
कुछ पेज तब तक डेटा लोड नहीं करते जब तक आप कुछ क्लिक नहीं करते या नीचे स्क्रॉल नहीं करते। सौभाग्य से, डेटा माइनर ये काम भी कर सकता है! उस तत्व का चयन करने के लिए शीर्ष पर "ढूंढें" टूल का उपयोग करें (अब तक आपको उस पर बहुत अच्छा होना चाहिए), फिर चयनकर्ता को उपयुक्त बॉक्स में रखें और यह सुनिश्चित करने के लिए परीक्षण करें कि यह काम करता है।
यह पता लगाना कि कौन सा चयनकर्ता तत्व या अनंत स्क्रॉलबार को सक्रिय करेगा, मुश्किल हो सकता है, लेकिन बुनियादी HTML ज्ञान और कुछ परीक्षण और त्रुटि आपको यहां बहुत दूर ले जाएंगे। आपको यहां जिन चीजों में हेरफेर करने की आवश्यकता होगी उनमें से अधिकांश जावास्क्रिप्ट-आधारित हैं, लेकिन डेटा माइनर को इसे सक्रिय करने के लिए कार्रवाई से जुड़े सीएसएस चयनकर्ता को जानने की जरूरत है, इसलिए आपको ज्यादातर मामलों में किसी भी कोड के साथ खिलवाड़ करने की आवश्यकता नहीं है।
अगला चरण आपको कस्टम जेएस में जोड़ने की अनुमति देता है, जो आप चाहते हैं, लेकिन यह काफी उन्नत है और बुनियादी स्क्रैपिंग के लिए हमें जो चाहिए, उससे आगे जाता है।
9. नुस्खा सहेजें और चलाएं
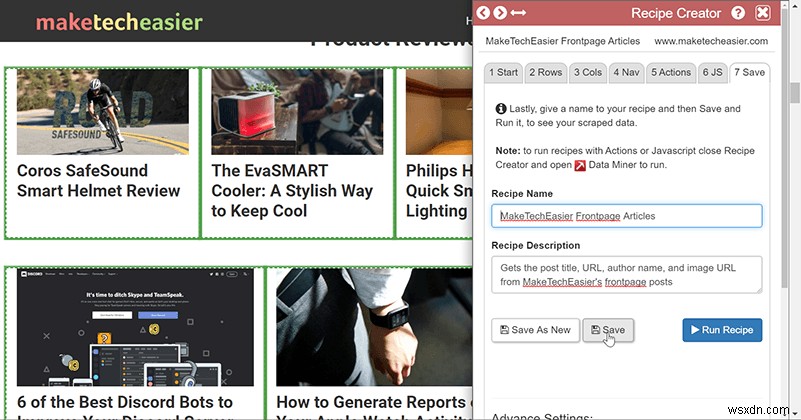
बधाई हो! अब यह देखने का समय है कि क्या यह सब एक साथ आता है। आप जिस पेज पर हैं उस पर रेसिपी चलाएँ और यह देखने के लिए पूर्वावलोकन की जाँच करें कि क्या आपकी पंक्तियाँ और कॉलम वही कर रहे हैं जो उन्हें करना चाहिए था। यदि नहीं, तो आप वापस जा सकते हैं और नुस्खा संपादित कर सकते हैं।
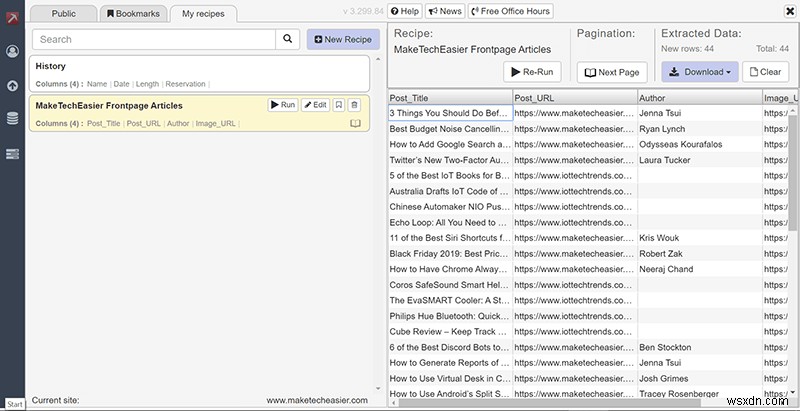
यदि सब कुछ वैसा ही व्यवहार कर रहा है जैसा उसे होना चाहिए, तो आप स्क्रैपर को यह बताने के लिए "अगला पृष्ठ" बटन का उपयोग कर सकते हैं कि उसे कितने पृष्ठ क्रॉल करने चाहिए और उसे कितनी तेजी से जाना चाहिए/ (बहुत तेज़ी से जाने से सिस्टम आपको बॉट के रूप में फ़्लैग कर सकता है।)
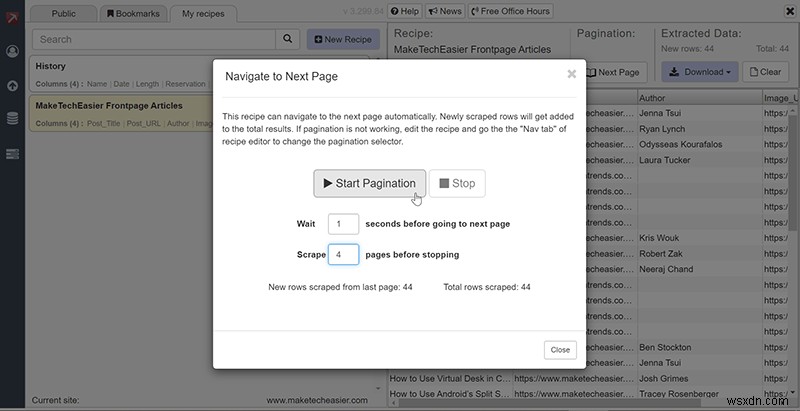
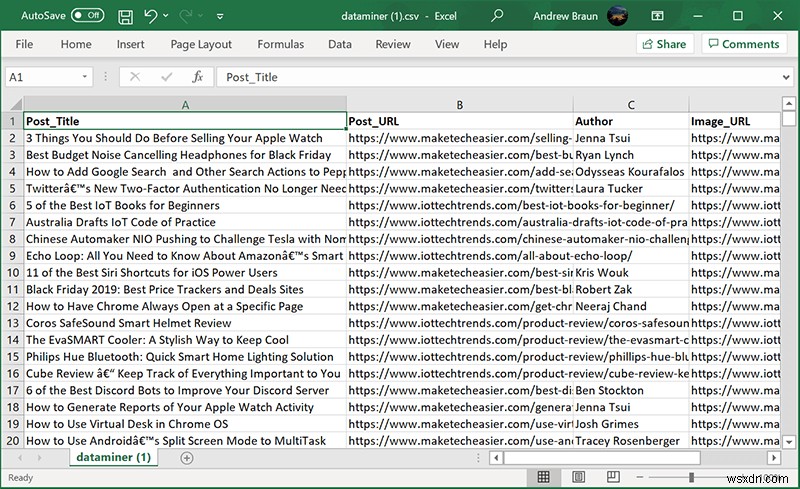
एक बार जब आपके पास आवश्यक सभी डेटा हो, तो आप चुन सकते हैं कि आप इसे डाउनलोड करने के लिए किस फ़ाइल प्रारूप का उपयोग करना चाहते हैं।
मुझे परेशानी हो रही है; क्या कोई आसान तरीका है?
यदि डेटा माइनर प्रोग्राम आपके लिए काम नहीं कर रहा है, तो कई अन्य डेटा-स्क्रैपिंग टूल उपलब्ध हैं:ParseHub, Scraper, Octoparse, Import.io, VisualScraper, आदि। उनमें से कुछ में अधिक सहज इंटरफ़ेस और अधिक स्वचालन हो सकता है, लेकिन आपको अभी भी कम से कम HTML के बारे में और वेब को कैसे व्यवस्थित किया जाता है, इसके बारे में जानने की आवश्यकता होगी। जो चीज डेटा माइनर को शुरुआती लोगों के लिए विशेष रूप से अच्छा बनाती है, वह है इसकी भीड़-भाड़ वाली रेसिपी लाइब्रेरी, जो संभावित रूप से कोड के साथ सबसे छोटी मुठभेड़ से बचने में आपकी मदद कर सकती है। यह, इसके काफी उदार मुफ्त मासिक स्क्रैप पैकेज के साथ, इसे अधिकांश जरूरतों के लिए एक बहुत ही अच्छा टूल बनाता है।