सी भाषा में फोर्क() फ़ंक्शन
<पी> फोर्क() फ़ंक्शन कॉलिंग प्रक्रिया का डुप्लिकेट बनाता है। हालाँकि चाइल्ड प्रक्रिया मूल प्रक्रिया की डुप्लिकेट है, वे कुछ गुणों जैसे आवंटित मेमोरी क्षेत्र, पीआईडी, आदि को साझा नहीं करते हैं। इसके बाद, आइए फोर्क() फ़ंक्शन के सिंटैक्स को देखें: <पी> फोर्क() फ़ंक्शन मूल प्रक्रिया में परिणाम के रूप में चाइल्ड प्रक्रिया की पीआईडी लौटाता है, जबकि उसी कॉल का चाइल्ड प्रक्रिया पर कोई प्रभाव नहीं पड़ता है और परिणामस्वरूप 0 लौटाता है। यह तंत्र हमें "if" स्थिति के माध्यम से दो प्रक्रियाओं में अलग-अलग कोड निष्पादित करने की अनुमति देता है जहां स्थिति fork() का रिटर्न मान है। आइए इस निम्नलिखित अवधारणा को देखें: <पी> अगर (कांटा() ==0){
चाइल्ड प्रक्रिया के लिए कोड
} <पी> अन्यथा
{
मूल प्रक्रिया के लिए कोड
} <पी> इस तरह, मूल प्रक्रिया उस कोड को निष्पादित करती है जो "अन्य" कथन के घुंघराले ब्रेसिज़ के बीच होता है, जबकि चाइल्ड प्रक्रिया उस कोड को निष्पादित करती है जो "if" कथन में होता है। <पी> आइए इसे एक सरल उदाहरण से देखें। निम्नलिखित कोड जो हम देखते हैं उसमें दो अनंत लूप हैं। मूल प्रक्रिया में, प्रोग्राम "अन्य" कथन के अनुरूप लूप में आता है जो "मूल प्रक्रिया के लिए लिखें" संदेश प्रदर्शित करता है, जबकि फोर्क() द्वारा बनाई गई चाइल्ड प्रक्रिया में "if" कथन में आता है जो "चाइल्ड प्रक्रिया के लिए लिखें" संदेश प्रदर्शित करता है। <पी> #शामिल
#शामिल
{
जबकि (1){
प्रिंटफ ("चाइल्ड प्रोसेस द्वारा लिखें \n");
नींद(5);}
} <पी> अन्यथा
{
जबकि (1){
प्रिंटफ ("मूल प्रक्रिया द्वारा लिखें \n");
नींद(2);}
}
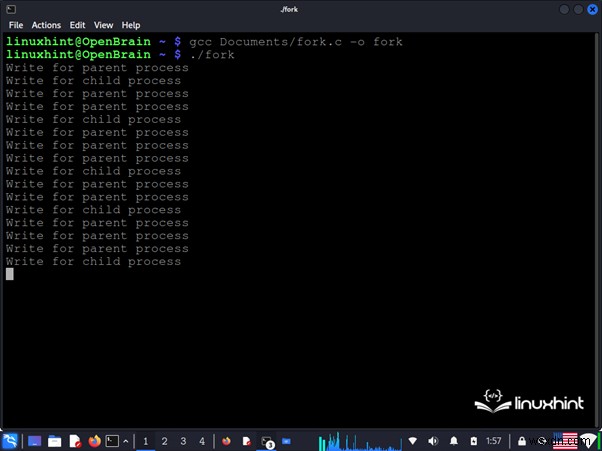
} <पी> निम्नलिखित छवि इस कोड के संकलन और निष्पादन को दिखाती है। जैसा कि कमांड कंसोल में देखा गया है, प्रत्येक प्रक्रिया अलग-अलग कोड निष्पादित करती है: <पी>
C भाषा में ExecXXX() फ़ंक्शन
<पी> फ़ंक्शंस का execXXX() परिवार एक चल रही प्रक्रिया को एक नई प्रक्रिया से बदल देता है। नई प्रक्रिया की छवि को मेमोरी क्षेत्र में कॉपी किया जाता है जो उस प्रक्रिया को आवंटित किया जाता है जिसे प्रतिस्थापित किया जा रहा है, अन्य चीजों के अलावा, इसके पीआईडी और आवंटित संसाधनों को संरक्षित किया जाता है। <पी> इस समूह के फ़ंक्शन जिन्हें "unistd.h" हेडर में परिभाषित किया गया है, वे अपने इनपुट के आधार पर विभिन्न कॉल विधियों का उपयोग करते हैं और "वैरिएडिक्स" प्रकार के होते हैं, इसलिए वे पुरानी प्रक्रिया से नई प्रक्रिया में तर्क या पॉइंटर्स की एक अनिर्दिष्ट सूची पास कर सकते हैं। इसके बाद, आइए प्रत्येक फ़ंक्शन के लिए सिंटैक्स देखें। <पी> int execl(const char *path, const char *arg, ...(char *) NULL );int execlp(const char *file, const char *arg, ... (char *) NULL );
int execle(const char *path, const char *arg, ... , (char *) NULL, char * const envp[] ); <पी> int execv(const char *path, char *const argv[]);
int execvp(const char *फ़ाइल, char *const argv[]);
int execvpe(const char *फ़ाइल, char *const argv[],
चार *const envp[]); <पी> execl(), execle(), और execv() फ़ंक्शंस एक स्ट्रिंग के लिए अपने पहले इनपुट तर्क के रूप में एक पॉइंटर का उपयोग करते हैं जिसमें नई प्रक्रिया की निष्पादन योग्य फ़ाइल का पूर्ण पथ होता है, जबकि execlp(), execvp(), और execvpe() वर्तमान निर्देशिका में फ़ाइल के नाम का उपयोग करते हैं। दूसरा इनपुट वे तर्क हैं जिन्हें आप नई प्रक्रिया में पास करते हैं। ये या तो const char *arg स्ट्रिंग्स या char *const argv[] स्ट्रिंग्स के पॉइंटर्स की एक सूची होनी चाहिए। <पी> अब, आइए एक उदाहरण देखें जो एक प्रक्रिया को बदलने और इनपुट तर्कों को एक प्रोग्राम से दूसरे प्रोग्राम में पास करने के लिए execv() फ़ंक्शन का उपयोग करता है। <पी> ऐसा करने के लिए, हम दो बहुत ही सरल कोड बनाते हैं। एक मूल प्रक्रिया है जो चाइल्ड प्रक्रिया को निष्पादित करने के लिए execv() फ़ंक्शन को कॉल करती है। जब execv() फ़ंक्शन चाइल्ड प्रक्रिया शुरू करता है, तो यह उसे दो इनपुट तर्कों को एक स्ट्रिंग के रूप में पास करता है जिसे चाइल्ड प्रक्रिया पुनः प्राप्त करेगी और शेल पर प्रदर्शित करेगी।
बाल प्रक्रिया
<पी> चाइल्ड प्रक्रिया कोड का एक सरल टुकड़ा है जो "मैं चाइल्ड प्रोसेस हूं" संदेश प्रिंट करता है, मूल प्रक्रिया द्वारा भेजे गए इनपुट तर्क को पुनर्प्राप्त करता है, और उन्हें शेल पर प्रदर्शित करता है। चाइल्ड प्रक्रिया के लिए कोड यहां दिया गया है: <पी>#शामिल
#शामिल करें
#शामिल
int मुख्य(int argc, char *argv[])
{
प्रिंटफ ("मैं चाइल्ड प्रोसेस हूं\n\n");
प्रिंटफ ("तर्क 1:%s\n", argv[1]);
प्रिंटफ़ ("तर्क 2:%s\n", argv[2]);
}
<पी> हम इस कोड को संकलित करते हैं और इसके उत्पादन को ".bin" एक्सटेंशन के साथ "बच्चे" नाम के तहत "दस्तावेज़ों" में सहेजते हैं जैसा कि निम्नलिखित में दिखाया गया है: <पी>
~$ gcc दस्तावेज़/child.c -o दस्तावेज़/child.bin
<पी> इस प्रकार, हम चाइल्ड एक्ज़ीक्यूटेबल फ़ाइल को "डॉक्यूमेंट्स" में सेव करते हैं। मूल प्रक्रिया में execv() को कॉल करते समय इस निष्पादन योग्य का पथ इनपुट तर्क पथ होता है।
मूल प्रक्रिया
<पी> मूल प्रक्रिया वह है जिसमें से हम execv() फ़ंक्शन को चाइल्ड प्रक्रिया से बदलने के लिए कॉल करते हैं। इस कोड में, हम स्ट्रिंग्स के लिए पॉइंटर्स की एक सरणी को परिभाषित करते हैं जो execv() फ़ंक्शन द्वारा खुलने वाली प्रक्रिया के इनपुट तर्कों का प्रतिनिधित्व करते हैं। <पी> निम्नलिखित चित्रण में, आप देख सकते हैं कि स्ट्रिंग्स के लिए पॉइंटर्स की एक सरणी सही ढंग से कैसे बनाई जाए। इस मामले में, इसमें चार पॉइंटर्स होते हैं और इसे "arg_Ptr[]" कहा जाता है। <पी> एक बार पॉइंटर ऐरे परिभाषित हो जाने के बाद, प्रत्येक पॉइंटर को एक स्ट्रिंग के साथ असाइन किया जाना चाहिए जिसमें इनपुट तर्क होता है जिसे हम चाइल्ड प्रक्रिया को भेजते हैं। Execxx() फ़ंक्शंस का उपयोग करने के लिए एक सामान्य नियम के रूप में, पहला तर्क एक स्ट्रिंग होना चाहिए जिसमें निष्पादन योग्य फ़ाइल का नाम और एक्सटेंशन शामिल हो, और अंतिम पॉइंटर NULL होना चाहिए। <पी> इस प्रकार, हम प्रत्येक सूचक को एक स्ट्रिंग प्रारूप में संबंधित तर्क निर्दिष्ट करते हैं: <पी>arg_Ptr[0] ="child.bin";
arg_Ptr[1] =" नमस्ते ";
arg_Ptr[2] ="प्रक्रिया 2";
arg_Ptr[3] =शून्य;
<पी> अगला चरण execv() फ़ंक्शन को कॉल करना है, उस स्ट्रिंग को पास करना जिसमें निष्पादन योग्य फ़ाइल का पूर्ण पथ पहले तर्क के रूप में और स्ट्रिंग्स की सरणी arg_Ptr[] दूसरे तर्क के रूप में शामिल है। आप मूल प्रक्रिया का पूरा कोड निम्नलिखित में देख सकते हैं: <पी>
#शामिल है
#शामिल है
#शामिल है
#शामिल है
#शामिल है
पूर्णांक मुख्य(){
प्रिंटफ ("मैं मूल प्रक्रिया हूं");
चार *arg_Ptr[4];
arg_Ptr[0] ="child.c";
arg_Ptr[1] =" नमस्ते ";
arg_Ptr[2] ="प्रक्रिया 2";
arg_Ptr[3] =शून्य;
execv('/home/linuxhint/Documents/child.bin', arg_Ptr);
}
<पी> हम इस कोड को संकलित करते हैं जो ".c" फ़ाइल का पथ और आउटपुट का नाम निर्दिष्ट करता है: <पी>
~$ gcc दस्तावेज़/parent.c -o पैटर्न
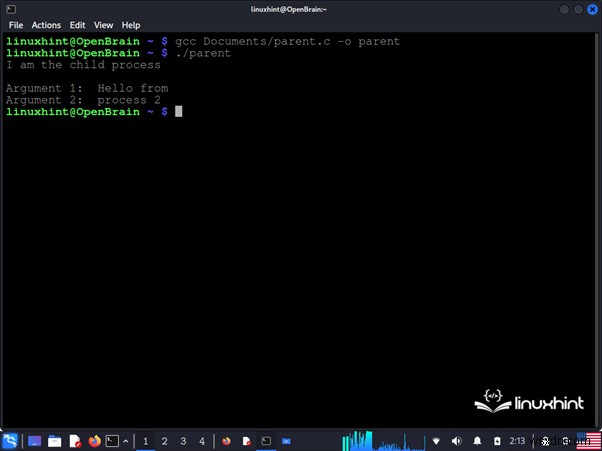
<पी> फिर, हम आउटपुट चलाते हैं: <पी> मूल प्रक्रिया "मैं मूल प्रक्रिया हूं" संदेश प्रदर्शित करती है, प्रत्येक इनपुट तर्क के लिए एक स्ट्रिंग निर्दिष्ट करके स्ट्रिंग सरणी बनाती है जो अगली प्रक्रिया में पारित हो जाती है, और execv() फ़ंक्शन को कॉल करती है। <पी> यदि execv() फ़ंक्शन सफलतापूर्वक निष्पादित होता है, तो "child.bin" निष्पादन योग्य मूल प्रक्रिया को बदल देता है और इसकी आईडी और आवंटित मेमोरी को अपने कब्जे में ले लेता है। इसलिए, इस कार्रवाई को पूर्ववत नहीं किया जा सकता. <पी> चाइल्ड प्रक्रिया "मैं चाइल्ड प्रोसेस हूं" संदेश प्रदर्शित करती है और कमांड कंसोल पर प्रदर्शन के लिए मूल प्रक्रिया द्वारा पारित किए गए प्रत्येक इनपुट तर्क को पुनः प्राप्त करती है। <पी>
लिनक्स में नई प्रक्रियाएँ बनाने के लिए फ़ोर्क() और Execve() फ़ंक्शंस का संयोजन
<पी> जैसा कि हमने अब तक देखा है, fork() फ़ंक्शन एक प्रक्रिया को डुप्लिकेट करता है, जबकि execve() एक प्रक्रिया को प्रतिस्थापित करता है। इस उदाहरण में, हम देखेंगे कि डुप्लिकेट से एक नई प्रक्रिया खोलने के लिए हम इन दोनों फ़ंक्शन का संयोजन में उपयोग कैसे कर सकते हैं जिसे बाद में बदल दिया जाता है। ऐसा करने के लिए, हम पहले देखे गए दो कार्यों से कोड को जोड़ते हैं ताकि fork() मूल प्रक्रिया को डुप्लिकेट कर सके और execve() इसे एक निष्पादन योग्य से बदल दे, जो इस मामले में, वही है जो हमने पिछले "child.bin" उदाहरण में उपयोग किया था। <पी> अब, हम ".c" एक्सटेंशन के साथ एक खाली फ़ाइल लेते हैं और प्रोग्राम कोड डालते हैं जो हमने fork() फ़ंक्शन उदाहरण में देखा था। <पी> इस प्रोग्राम में, हम केवल चाइल्ड प्रक्रिया के कोड को संशोधित करते हैं ताकि execv() फ़ंक्शन इसे "child.bin" निष्पादन योग्य से बदल दे, जबकि मुख्य कार्य fork() फ़ंक्शन उदाहरण के समान है। <पी> ऐसा करने के लिए, हम execv() फ़ंक्शन उदाहरण से मुख्य() फ़ंक्शन की सामग्री को कॉपी करते हैं और "if" कथन की सामग्री को इस कोड से प्रतिस्थापित करते हैं। अब, आइए देखें कि पूरा कार्यक्रम कैसा दिखता है: <पी> #शामिल#शामिल
{
प्रिंटफ ("मैं चाइल्ड प्रोसेस हूं\n");
चार *arg_Ptr[5];
arg_Ptr[0] ="child.c";
arg_Ptr[1] =" नमस्ते ";
arg_Ptr[2] ="प्रक्रिया 2";
arg_Ptr[3] =शून्य;
execv(/home/linuxhint/Documents/child.bin", arg_Ptr);
} <पी> अन्यथा
{
जबकि (1){
प्रिंटफ़ (" मूल प्रक्रिया द्वारा लिखें \n");
नींद(3);}
}
} <पी> इस तरह, सिस्टम पर एक नया बनाकर प्रक्रिया को दोहराया जाता है जिसे execv() फ़ंक्शन फिर "child.bin" निष्पादन योग्य प्रक्रिया से बदल देता है। इसके बाद, हम इस कोड के संकलन के साथ एक छवि देखते हैं। <पी>
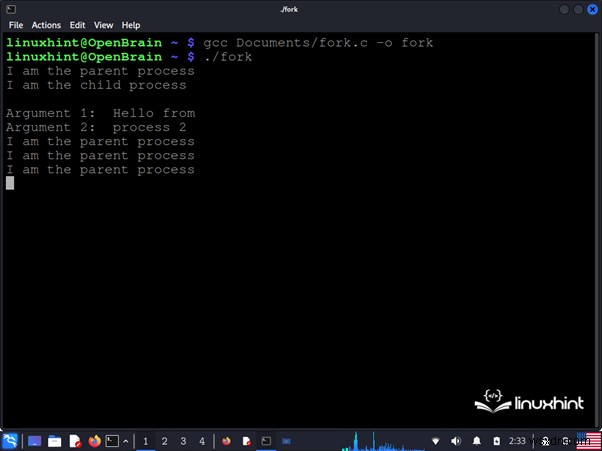 <पी> जैसा कि हम छवि में देख सकते हैं, fork() फ़ंक्शन इसे डुप्लिकेट करके एक नई प्रक्रिया बनाता है, जिसे execv() फ़ंक्शन ने फिर "child.bin" निष्पादन योग्य से बदल दिया।
<पी> जैसा कि हम छवि में देख सकते हैं, fork() फ़ंक्शन इसे डुप्लिकेट करके एक नई प्रक्रिया बनाता है, जिसे execv() फ़ंक्शन ने फिर "child.bin" निष्पादन योग्य से बदल दिया।