मूल रूप से 27 नवंबर, 2020 को ObjectRocket.com/blog पर प्रकाशित हुआ।
Elasticsearch® डिफ़ॉल्ट सेटिंग्स के साथ आपके क्लस्टर में डेटा फैलाने में कमाल है, लेकिन आपके क्लस्टर के बढ़ने के बाद, प्रभावशीलता बढ़ाने के लिए आपको अपनी डिफ़ॉल्ट सेटिंग्स को समायोजित करना चाहिए। आइए शार्डिंग की कुछ बुनियादी बातों पर ध्यान दें और कुछ अनुक्रमण और शार्ड सर्वोत्तम अभ्यास प्रदान करें।
इलास्टिक्स खोज शार्डिंग का परिचय

इलास्टिक्स खोज शार्क कैसे काम करती है, इसके बारे में कई दस्तावेज़ हैं, लेकिन शार्डिंग की मूल अवधारणा आपके डेटा को कई छोटे टुकड़ों में तोड़ रही है ताकि खोज समानांतर में कई हिस्सों पर काम कर सके। इंडेक्स फ़ंक्शंस के क्लस्टरिंग और समानांतरीकरण की सुविधा के लिए, अपने इलास्टिक्स खोज इंस्टेंस में प्रत्येक इंडेक्स को क्रमांकित स्लाइस में विभाजित करें। इन स्लाइस को शार्ड्स कहा जाता है। आइए उनके कुछ प्रमुख व्यवहारों को देखें:
- प्रत्येक शार्ड प्रतिकृति की संख्या के आधार पर प्रतिकृति बनाता है सूचकांक के लिए सेटिंग। तो, प्रतिकृतियों की संख्या . के लिए एक की स्थापना, प्रत्येक शार्ड की दो प्रतियां होती हैं:एक प्राथमिक शार्ड और एक प्रतिकृति टुकड़ा प्राथमिक शार्ड मुख्य शार्द है और इसका उपयोग
indexing/write. के लिए किया जाता है औरsearch/readसंचालन, जबकि प्रतिकृति शार्क का उपयोग केवलsearch/read. के लिए किया जाता है संचालन और प्राथमिक विफल होने पर पुनर्प्राप्ति के लिए। - रेप्लिका शार्क को उनके पैरेंट . से अलग होस्ट पर रहना चाहिए प्राथमिक शार्ड.
- शार्ड डिफ़ॉल्ट रूप से क्लस्टर में होस्ट की संख्या में स्वचालित रूप से फैल जाते हैं, लेकिन एक ही भौतिक होस्ट में कई प्राथमिक शार्क हो सकते हैं। आप इस व्यवहार को संशोधित करने के लिए इलास्टिक्स खोज सेटिंग्स का उपयोग कर सकते हैं (पुनर्संतुलन, शार्क आवंटन, और इसी तरह), लेकिन यह प्रक्रिया इस पोस्ट के दायरे से बाहर है।
- प्रत्येक शार्ड को केवल एक ही मेजबान में रहना चाहिए क्योंकि शार्ड अविभाज्य हैं।
- आप इंडेक्स बनाने के दौरान इंडेक्स द्वारा बनाए जाने वाले शार्क की संख्या सेट कर सकते हैं, या आप ग्लोबल डिफॉल्ट का उपयोग कर सकते हैं। अनुक्रमणिका बनाने के बाद, आप पुन:अनुक्रमणित किए बिना शार्क की संख्या नहीं बदल सकते।
- आप अनुक्रमणिका निर्माण के दौरान अनुक्रमणिका की प्रतिकृतियों की संख्या निर्धारित कर सकते हैं, या आप वैश्विक डिफ़ॉल्ट का उपयोग कर सकते हैं। इंडेक्स बनाने के बाद आप इस नंबर को बदल सकते हैं।
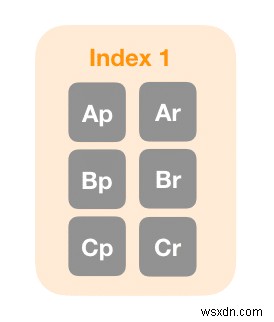
आइए एक छोटा सा उदाहरण देखें। मैंने तीन की शार्प काउंट और एक की प्रतिकृति सेटिंग के साथ एक इंडेक्स बनाया। जैसा कि आप पिछले आरेख में देख सकते हैं, Elasticsearch आपके लिए छह शार्क बनाता है:तीन प्राथमिक शार्क (Ap, Bp, और Cp) और तीन प्रतिकृति शार्क (Ar, Br, और Cr)।
Elasticsearch यह सुनिश्चित करता है कि प्रतिकृतियां और प्राइमरी अलग-अलग होस्ट पर हैं, लेकिन आप एक ही होस्ट के लिए कई प्राथमिक शार्क आवंटित कर सकते हैं। मेज़बानों के विषय पर, आइए जानें कि आप अपने मेज़बानों को शार्क कैसे आवंटित करते हैं।
शार्ड आवंटन और क्लस्टर Elasticsearch
Elasticsearch डिफ़ॉल्ट रूप से सभी उपलब्ध मेजबानों में शार्क आवंटित करने का प्रयास करता है। रैकस्पेस ऑब्जेक्ट रॉकेट में, प्रत्येक क्लस्टर में मास्टर नोड्स, क्लाइंट नोड्स और डेटा नोड्स होते हैं। हमारे आर्किटेक्चर में डेटा नोड्स बाल्टी बनाते हैं जिस पर आप शार्क असाइन कर सकते हैं।
पिछले उदाहरण का उपयोग करते हुए, आइए उन छह शार्क को लें और उन्हें दो डेटा नोड्स (न्यूनतम) के साथ इलास्टिक्स खोज क्लस्टर के लिए एक ऑब्जेक्ट रॉकेट को असाइन करें। निम्नलिखित आरेख में, आप देख सकते हैं कि प्रत्येक शार्क के लिए, एक डेटा नोड पर प्राथमिक भूमि, जबकि प्रतिकृति दूसरे नोड पर होने की गारंटी है। ध्यान रखें कि यहां दिए गए उदाहरण केवल एक संभावित आवंटन दिखाते हैं। आवंटन से कोई फर्क नहीं पड़ता, केवल एक निश्चित बात यह है कि एक प्रतिकृति को हमेशा उसके प्राथमिक से अलग डेटा नोड पर रखा जाता है।
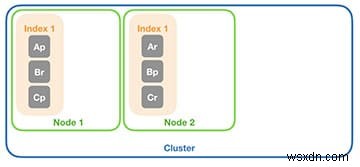
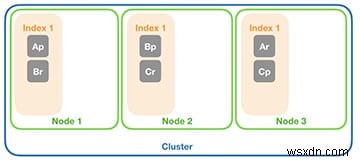
अब, इस उदाहरण का विस्तार करें और तीसरा डेटा नोड जोड़ें। ध्यान दें कि दो शार्क नए डेटा नोड में चले गए हैं, इसलिए आपके पास प्रत्येक नोड पर दो शार्क हैं।
अंत में, इस क्लस्टर में दो की शार्प काउंट और दो प्रतियों की संख्या के साथ एक नया इंडेक्स जोड़ें। यह आपको दो नई प्राइमरी (Xp और Yp) और चार प्रतिकृतियां (Xr0, Xr1, Yr0, Yr1) देता है जिसे आप निम्न चित्र में देखे अनुसार पूरे क्लस्टर में फैला सकते हैं:
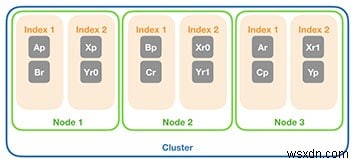
बस।
नुकसान
Elasticsearch आपके लिए पूरी मेहनत करता है, लेकिन इससे बचने के लिए कुछ नुकसान हैं।
Pitfall #1—विशाल अनुक्रमणिका और विशाल शार्क
बड़े पैमाने पर शार्क के साथ बड़े पैमाने पर सूचकांक का समस्या निवारण Elasticsearch में कम करने के लिए सबसे आसान मुद्दों में से एक है। एक उपयोगकर्ता एक बहुत ही प्रबंधनीय एकल अनुक्रमणिका के साथ शुरू होता है। हालाँकि, जैसे-जैसे उनका आवेदन बढ़ता है, वैसे-वैसे उनकी index. इससे बड़े शार्क बनते हैं क्योंकि शार्ड का आकार सीधे क्लस्टर डेटा की मात्रा से संबंधित होता है।
इसका कारण पहला मुद्दा क्लस्टर उपयोग में खराब दक्षता है। जैसे-जैसे शार्ड्स बढ़ते हैं, उन्हें एडेटा नोड पर रखना कठिन होता जाता है। वहां एक शार्क को स्टोर करने के लिए डेटा नोड मुक्त स्थान का एक बड़ा ब्लॉक लेता है। यह स्थिति बहुत अधिक अप्रयुक्त, व्यर्थ स्थान वाले नोड्स की ओर ले जाती है। उदाहरण के लिए, यदि मेरे पास 8 जीबी डेटा नोड्स हैं, लेकिन प्रत्येक शार्ड 6 जीबी है, तो मैं अपने प्रत्येक डेटानोड पर 2 जीबी फंसे रहूंगा। दूसरा मुद्दा है हॉट स्पॉटिंग . यदि आप अपने डेटा को कुछ टुकड़ों में समेकित करते हैं, तो जटिल प्रश्नों को बड़ी संख्या में नोड्स में विभाजित नहीं किया जा सकता है और समानांतर में निष्पादित किया जा सकता है।
इंडेक्स के साथ कंजूस न हों
रुकी हुई जगह की समस्याओं को हल करने के लिए कई इंडेक्स का इस्तेमाल करें. क्लस्टर में शार्क की संख्या बढ़ाने और डेटा को समान रूप से फैलाने के लिए अपने डेटा को कई इंडेक्स में फैलाएं। इसके अलावा, टेट्रिस गेम की तरह, जब इलास्टिक्स खोज में शार्क होती है, तो कई इंडेक्स को क्यूरेट करना आसान होता है। Elasticsearch में अन्य नाम क्षमताएं अभी भी आपके ऐप में कई उदाहरणों को एकल अनुक्रमणिका के रूप में प्रदर्शित कर सकती हैं। अधिकांश Elastic Stack डिफ़ॉल्ट रूप से दैनिक अनुक्रमणिका बनाता है, जो एक अच्छा अभ्यास है। फिर आप विशिष्ट तिथि सीमाओं तक खोजों के दायरे को सीमित करने के लिए उपनामों का उपयोग कर सकते हैं, पुराने इंडेक्स को उम्र के रूप में निकालने के लिए क्यूरेटर का उपयोग कर सकते हैं, और इंडेक्स सेटिंग्स को संशोधित कर सकते हैं क्योंकि आपका डेटा पुराने डेटा को फिर से इंडेक्स किए बिना बढ़ता है।
आपके इंडेक्स का आकार बढ़ने पर शार्प काउंट बढ़ाएं
इंडेक्स को अधिक बार जोड़ें और जैसे-जैसे आपका इंडेक्स बढ़ता है, शार्प काउंट बढ़ाएं। जब आप देखते हैं कि शार्प आकार आपके वांछित स्थान से अधिक होने लगे हैं, तो आप प्रत्येक इंडेक्स के लिए अधिक शार्क का उपयोग करने के लिए अपने इंडेक्स टेम्प्लेट (या जो भी आप नई इंडेक्स बनाने के लिए उपयोग करते हैं) को अपडेट कर सकते हैं। हालांकि, यह केवल तभी मदद करता है जब आप अक्सर नए इंडेक्स बनाते हैं, इसलिए यह अनुशंसा दूसरे स्थान पर है। अन्यथा, आपको शार्प काउंट को संशोधित करने के लिए रीइंडेक्स करना होगा, जो कई इंडेक्स को प्रबंधित करने की तुलना में अधिक काम का प्रतिनिधित्व करता है।
हमारे अंगूठे का नियम:यदि एक शार्ड डेटा नोड के आकार के 40% से बड़ा है, तो वह शार्ड शायद बहुत बड़ा है। इस मामले में, अधिक शार्प वाली अनुक्रमणिका में पुन:अनुक्रमणित करने या बड़े योजना आकार (प्रति डेटा नोड अधिक क्षमता) तक जाने की अनुशंसा की गई थी।
पिटफ़ॉल #2—बहुत अधिक अनुक्रमणिका या शार्प
उलटा बहुत अधिक इंडेक्स या शार्क है। पिछले भाग को पढ़ने के बाद, आप बस इतना कह सकते हैं, “ठीक है। मैं हर दस्तावेज़ को उसके सूचकांक में डालूँगा और एक लाख शार्क बनाऊँगा"। समस्या यह है कि इंडेक्स और शार्क के ऊपर की ओर है। वह ओवरहेड स्टोरेज, मेमोरी रिसोर्सेज और प्रोसेसिंग परफॉर्मेंस में खुद को प्रकट करता है।
क्योंकि क्लस्टर को सभी शार्क की स्थिति को बनाए रखना चाहिए और जहां वे स्थित हैं, बड़ी संख्या में शार्क एक बड़ा बहीखाता संचालन बन जाता है, जो स्मृति उपयोग को प्रभावित करता है। साथ ही, क्योंकि आपको प्रश्नों को अधिक तरीकों से विभाजित करने की आवश्यकता होती है, आप प्रश्नों के लिए अधिक समय व्यतीत करते हैं या एकत्रित होते हैं। यह नुकसान क्लस्टर के आकार, उपयोग के मामले और अन्य कारकों पर अत्यधिक निर्भर है, लेकिन सामान्य तौर पर, हम कुछ अनुशंसाओं के साथ इसे कम कर सकते हैं।
शार्ड 50 GB से बड़े नहीं होने चाहिए
सामान्य तौर पर, 25 जीबी बड़े शार्क के लिए एक आदर्श आकार है, और 50 जीबी को पुन:अनुक्रमण की आवश्यकता होती है। यह विचार शार्ड के प्रदर्शन और आवश्यकता पड़ने पर उस शार्ड को हिलाने की प्रक्रिया से संबंधित है। पुनर्संतुलन करते समय, शार्क को क्लस्टर में एक अलग नोड में ले जाएं। एक 50 जीबी डेटा ट्रांसफर में बहुत अधिक समय लग सकता है और पूरी प्रक्रिया के दौरान दो नोड्स को जोड़ सकते हैं।
शार्ड आकार को डेटा नोड आकार के 40% से कम रखें
जैसा कि पहले उल्लेख किया गया है, दूसरा शार्ड आकार मीट्रिक जो हमें रूचि देता है वह डेटा नोड क्षमता का प्रतिशत है जो एक शार्क लेता है। रैकस्पेस ऑब्जेक्ट रॉकेट सेवा पर, हम विभिन्न योजना आकार प्रदान करते हैं जो डेटा नोड्स पर भंडारण की मात्रा से संबंधित होते हैं। यह सुनिश्चित करने के लिए क्लस्टर और शार्क को आकार देने का प्रयास करें कि सबसे बड़े शार्क डेटा नोड की क्षमता का 40% से अधिक नहीं लेते हैं। विभिन्न आकारों के कई इंडेक्स वाले क्लस्टर में, यह काफी प्रभावी है। हालांकि, बहुत कम बड़े इंडेक्स वाले क्लस्टर में, और भी अधिक आक्रामक होते हैं और डेटा नोड की क्षमता को 30% से कम रखने का प्रयास करते हैं।
आदर्श रूप से, सुनिश्चित करें कि आप डेटा नोड पर क्षमता को कम नहीं कर रहे हैं। यदि आपकी शार्क डेटा नोड के आकार का लगभग 45% है, तो आपको उस शार्क को रखने के लिए लगभग आधे उपयोग पर डेटा नोड की आवश्यकता होगी। यह बहुत अधिक अप्रयुक्त अतिरिक्त क्षमता है!
निष्कर्ष
सही शार्ड और इंडेक्सिंग सेटिंग्स का चयन करना मुश्किल हो सकता है, लेकिन योजना बनाकर, कुछ अच्छे निर्णय लेकर, और जैसे-जैसे आप आगे बढ़ते हैं, आप अपने क्लस्टर को स्वस्थ और बेहतर तरीके से चला सकते हैं। हम व्यवसायों को उनके इलास्टिक्स खोज उदाहरणों को हर समय परिष्कृत करने में मदद करते हैं।
रैकस्पेस डीबीए सेवाओं के बारे में अधिक जानें।
कोई टिप्पणी करने या प्रश्न पूछने के लिए प्रतिक्रिया टैब का उपयोग करें। आप विक्रय चैट . पर भी क्लिक कर सकते हैं अभी चैट करने और बातचीत शुरू करने के लिए।