डेटाबेस बैकअप और रिकवरी उन महत्वपूर्ण दैनिक गतिविधियों में से एक है जो डेटाबेस एडमिनिस्ट्रेटर (DBA) करता है। एक डेटाबेस बैकअप आपके डेटा की एक प्रति है जिसका उपयोग डेटा हानि की स्थिति में डेटा को पुनर्प्राप्त करने के लिए किया जा सकता है।
यह ब्लॉग आपको दिखाता है कि Apache® Cassandra® डेटाबेस का बैकअप कैसे लें और विफलता के बाद उन्हें कैसे पुनर्स्थापित करें।
परिचय
हालांकि अपाचे कैसेंड्रा विकेंद्रीकृत है, यह किसी भी व्यावसायिक डेटा को खोए बिना एकल और बहु-नोड विफलताओं को सहन कर सकता है, जब तक कि क्लस्टर में एक नोड में डेटा होता है। हालांकि, सर्वोत्तम अभ्यास के रूप में, आपको डेटाबेस के लिए बैकअप कॉन्फ़िगर करना चाहिए।
किसी भी विफलता के मामले में, जैसे संपूर्ण क्लस्टर पुनर्निर्माण, डेटा भ्रष्टाचार, आकस्मिक डेटा हटाना, और इसी तरह, आप बैकअप से डेटा पुनर्प्राप्त कर सकते हैं और न्यूनतम या बिना किसी प्रभाव के व्यावसायिक संचालन जारी रख सकते हैं।
अधिक से अधिक कंपनियां नोएसक्यूएल डेटाबेस का उपयोग कर रही हैं, जैसे कि कैसेंड्रा, बड़ी मात्रा में व्यावसायिक डेटा को सफलतापूर्वक प्रबंधित करने के लिए, जिसे अधिक लोकप्रिय रूप से बिग डेटा के रूप में जाना जाता है। कैसंड्रा, व्यापक रूप से कई प्रमुख संगठनों द्वारा उपयोग किया जाता है, बिग डेटा का समर्थन करने के लिए मापनीयता, दोष-सहिष्णुता और स्थिरता सुनिश्चित करता है।
कैसेंड्रा डेटाबेस बैकअप और पुनर्स्थापित करें
कैसेंड्रा डेटाबेस का स्नैपशॉट लेने और आवश्यकता पड़ने पर इसे पुनर्स्थापित करने के लिए आप निम्न उपयोगिताओं का उपयोग कर सकते हैं:
nodetool(स्नैपशॉट लेने के लिए)sstableloader(स्नैपशॉट बैकअप को पुनर्स्थापित करने के लिए)
निम्न छवि sstableloader का उपयोग करके क्लाउड क्लस्टर से Cassandracluster में जाने को दर्शाती है :
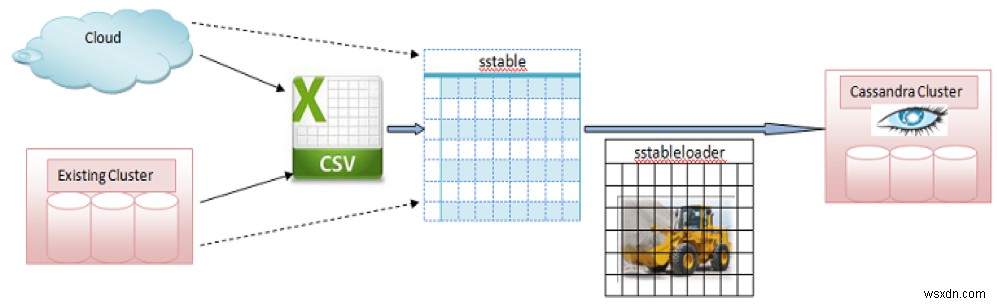
छवि स्रोत :https://dzone.com/articles/using-casandras-sstable-bulk
बैकअप
निम्न उदाहरण nodetool का उपयोग करता है कैसेंड्रा डेटाबेस का एक स्नैपशॉट लेने के लिएकीस्पेस(उपयोगकर्ता) कर्मचारी . नामक तालिका के साथ ।
स्रोत कैसेंड्रा क्लस्टर विवरण:
$ nodetool -u cassandra -pw ******** -h localhost status
Datacenter: us-central1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.128.0.2 121.52 KiB 256 63.3% 5957997f-7471-4c21-bead-37a6604812e2 f
UN 10.128.0.3 92.22 KiB 256 68.0% 87c2a663-a965-4675-b5ed-c4a46d77c796 f
UN 10.128.0.4 225.3 KiB 256 68.8% 8e12557f-be00-4387-bff3-ef51f431b9a0 f
कीस्पेस का बैकअप लेने के लिए निम्न कमांड का उपयोग करें :
$ nodetool -h localhost -u cassandra -pw ****** snapshot users -t "users-201904201800"
Requested creating snapshot(s) for [users] with snapshot name [users-201904201800] and options {skipFlush=false}
Snapshot directory: users-201904201800
यह एक बैकअप स्नैपशॉट बनाता है जैसा कि निम्न उदाहरण में दिखाया गया है:
/bitnami/cassandra/data/data/users/employee-c1319df0636211e9a0e3570eb7f8fd5f/snapshots/users-201904201800
$ ls -ltr
total 44
-rw-r--r-- 2 cassandra cassandra 16 Apr 20 12:05 md-1-big-Filter.db
-rw-r--r-- 2 cassandra cassandra 56 Apr 20 12:05 md-1-big-Summary.db
-rw-r--r-- 2 cassandra cassandra 32 Apr 20 12:05 md-1-big-Index.db
-rw-r--r-- 2 cassandra cassandra 134 Apr 20 12:05 md-1-big-Data.db
-rw-r--r-- 2 cassandra cassandra 10 Apr 20 12:05 md-1-big-Digest.crc32
-rw-r--r-- 2 cassandra cassandra 43 Apr 20 12:05 md-1-big-CompressionInfo.db
-rw-r--r-- 2 cassandra cassandra 4683 Apr 20 12:05 md-1-big-Statistics.db
-rw-r--r-- 2 cassandra cassandra 92 Apr 20 12:05 md-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 31 Apr 20 12:05 manifest.json
-rw-r--r-- 1 cassandra cassandra 865 Apr 20 12:05 schema.cql
$ date
Sat Apr 20 12:08:21 UTC 2019
अब, /स्नैपशॉट को संग्रहित करें बैकअप निर्देशिका फ़ाइलें और tarfile को /bitnami/Cassandra/data/data/backup में ले जाएं निर्देशिका।
$ tar -cvf users-201904201800.tar *.*
manifest.json
md-1-big-CompressionInfo.db
md-1-big-Data.db
md-1-big-Digest.crc32
md-1-big-Filter.db
md-1-big-Index.db
md-1-big-Statistics.db
md-1-big-Summary.db
md-1-big-TOC.txt
schema.cql
$ ls -ltr
total 64
-rw-r--r-- 2 cassandra cassandra 16 Apr 20 12:05 md-1-big-Filter.db
-rw-r--r-- 2 cassandra cassandra 56 Apr 20 12:05 md-1-big-Summary.db
-rw-r--r-- 2 cassandra cassandra 32 Apr 20 12:05 md-1-big-Index.db
-rw-r--r-- 2 cassandra cassandra 134 Apr 20 12:05 md-1-big-Data.db
-rw-r--r-- 2 cassandra cassandra 10 Apr 20 12:05 md-1-big-Digest.crc32
-rw-r--r-- 2 cassandra cassandra 43 Apr 20 12:05 md-1-big-CompressionInfo.db
-rw-r--r-- 2 cassandra cassandra 4683 Apr 20 12:05 md-1-big-Statistics.db
-rw-r--r-- 2 cassandra cassandra 92 Apr 20 12:05 md-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 31 Apr 20 12:05 manifest.json
-rw-r--r-- 1 cassandra cassandra 865 Apr 20 12:05 schema.cql
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:22 users-201904201800.tar
cp *.tar /bitnami/cassandra/data/data/backup.
/bitnami/cassandra/data/data/backup
$ ls -ltr
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:23 users-201904201800.tar
बैकअप टार फ़ाइल को गैर-डिफ़ॉल्ट स्थान पर कॉपी करने के बाद, कर्मचारी . को छोड़ दें टेबल।
नोट :कैसेंड्रा क्लस्टर में परिभाषित विभाजन कुंजियों और प्रतिकृति कारकों के आधार पर डेटा वितरित करता है, इसलिए आपको इस बैकअप कमांड को अपने सभी नोड्स से चलाना होगा। यह उदाहरण crontab में Linux® शेल स्क्रिप्ट का उपयोग करता है, जो एक ही बार में सभी नोड्स का बैकअप लेता है।
$ cqlsh -u cassandra -p *******
Connected to Test_Cassandra at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.4 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cassandra@cqlsh> use users;
cassandra@cqlsh:users> select * from employee;
emp_id | employee_address | employee_name
--------+------------------+---------------
8796 | Singapore | Joy
5647 | London | Mike
3452 | Canada | Nancy
6453 | China | John
(4 rows)
cassandra@cqlsh:users> drop table employee;
cassandra@cqlsh:users> select * from employee;
InvalidRequest: Error from server: code=2200 [Invalid query] message="unconfigured table employee"
पुनर्स्थापित करें
कर्मचारी . को पुनर्स्थापित करने के लिए कीस्पेस (उपयोगकर्ता) . से तालिका स्नैपशॉट बैकअप, आपको sstableloader . का उपयोग करना चाहिए उपयोगिता। sstableloader उपयोगिता न केवल प्रत्येक नोड के लिए sstables के सेट की प्रतिलिपि बनाती है, बल्कि डेटा के उपयुक्त भाग को एक क्लस्टर के लिए परिभाषित प्रतिकृति रणनीति के आधार पर प्रत्येक नोड में स्थानांतरित करती है। ध्यान दें कि डेटा को पुनर्स्थापित करने के लिए खाली तालिका का होना आवश्यक नहीं है।
टार फ़ाइल को बैकअप/उपयोगकर्ताओं . में पुनर्स्थापित करने के लिए निम्न चरणों का उपयोग करें :
$ pwd
/bitnami/cassandra/data/data/backup/users
$ ls -ltr
total 20
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:23 users-201904201800.tar
$ tar -xvf *.tar
manifest.json
md-1-big-CompressionInfo.db
md-1-big-Data.db
md-1-big-Digest.crc32
md-1-big-Filter.db
md-1-big-Index.db
md-1-big-Statistics.db
md-1-big-Summary.db
md-1-big-TOC.txt
schema.cql
उस तालिका के नाम के साथ उपयोगकर्ता निर्देशिका के लिए एक सॉफ्ट लिंक बनाएं जिसे आप पुनर्स्थापित करने जा रहे हैं।
$ ln -s /bitnami/cassandra/data/data/backup/users employee
$ ls -ltr
total 64
-rw-r--r-- 1 cassandra cassandra 865 Apr 20 12:05 schema.cql
-rw-r--r-- 1 cassandra cassandra 92 Apr 20 12:05 md-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 56 Apr 20 12:05 md-1-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 4683 Apr 20 12:05 md-1-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 32 Apr 20 12:05 md-1-big-Index.db
-rw-r--r-- 1 cassandra cassandra 16 Apr 20 12:05 md-1-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 10 Apr 20 12:05 md-1-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 134 Apr 20 12:05 md-1-big-Data.db
-rw-r--r-- 1 cassandra cassandra 43 Apr 20 12:05 md-1-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 31 Apr 20 12:05 manifest.json
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:23 users-201904201800.tar
lrwxrwxrwx 1 cassandra cassandra 41 Apr 20 15:56 employee -> /bitnami/cassandra/data/data/backup/users
.cql . का उपयोग करके तालिका संरचना बनाएं फ़ाइल जो स्नैपशॉट बैकअप द्वारा उत्पन्न की गई थी।
जब आप कीस्पेस . के लिए बैकअप निष्पादित करते हैं , यह schema.cql . नामक फ़ाइल उत्पन्न करता है जिसमें कीस्पेस . में रहने वाली वस्तुओं की डेटा परिभाषा भाषा (DDL) शामिल है ।
schema.cql . का उपयोग करें एक कर्मचारी वस्तु बनाने के लिए, जो गलती से गिर गई।
$ cqlsh -u cassandra -p ******** -f schema.cql
Warnings:
dclocal_read_repair_chance table option has been deprecated and will be removed in version 4.0
dclocal_read_repair_chance table option has been deprecated and will be removed in version 4.0
$ cqlsh -u cassandra -p ******* -f schema.cql
sstableloader . का उपयोग करके स्नैपशॉट से डेटा पुनर्स्थापित करें , जो प्रत्येकस्थिरों . को पढ़ता है बैकअप से और डेटा को क्लस्टर में स्ट्रीम करता है। यह तब क्लस्टर में परिभाषित प्रतिकृति रणनीति के आधार पर डेटा के प्रासंगिक भाग को प्रत्येक नोड में स्थानांतरित करता है।
Syntax: sstableloader -u <username> -pw passwrod -d <hostname> <employee table softlink name with location>
डेटा को पुनर्स्थापित करने के लिए निम्न आदेश का उपयोग करें:
$ sstableloader -u cassandra -pw ******** -d cassandra-cluster-1-node-0 /bitnami/cassandra/data/data/backup/users/employee
Established connection to initial hosts
Opening sstables and calculating sections to stream
Streaming relevant part of /bitnami/cassandra/data/data/backup/users/md-1-big-Data.db to [/10.128.0.2, /10.128.0.3, /10.128.0.4]
progress: [/10.128.0.2]0:0/1 0 % [/10.128.0.3]0:0/1 0 % [/10.128.0.4]0:1/1 100% total: 33% 0.032KiB/s (avg: 0.032KiB/s)
progress: [/10.128.0.2]0:0/1 0 % [/10.128.0.3]0:0/1 0 % [/10.128.0.4]0:1/1 100% total: 33% 0.000KiB/s (avg: 0.031KiB/s)
progress: [/10.128.0.2]0:0/1 0 % [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 66% 0.113KiB/s (avg: 0.050KiB/s)
progress: [/10.128.0.2]0:1/1 100% [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 100% 85.129KiB/s (avg: 0.074KiB/s)
progress: [/10.128.0.2]0:1/1 100% [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 100% 0.000KiB/s (avg: 0.073KiB/s)
progress: [/10.128.0.2]0:1/1 100% [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 100% 0.000KiB/s (avg: 0.073KiB/s)
Summary statistics:
Connections per host : 1
Total files transferred : 3
Total bytes transferred : 0.393KiB
Total duration : 5346 ms
Average transfer rate : 0.073KiB/s
Peak transfer rate : 0.074KiB/s
प्रत्येक नोड के लिए अपने अस्तबल से डेटा पुनर्प्राप्त करने के लिए इन चरणों को दोहराएं।
nodetool repair . का उपयोग करके डेटा को सुधारें , जो नोड पर संग्रहीत डेटा की सभी प्रतिकृतियों की तुलना करता है जिस पर कमांड चलता है और प्रत्येक प्रतिकृति को नवीनतम संस्करण में अपडेट करता है।
$ nodetool repair -u Cassandra -pw ********
[2019-04-21 07:59:14,701] Starting repair command #1 (5b123ad0-640b-11e9-a0e3-570eb7f8fd5f), repairing keyspace users with repair options (parallelism: parallel, primary range: false, incremental: true, job threads: 1, ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 768, pull repair: false)
[2019-04-21 07:59:16,450] Repair completed successfully
[2019-04-21 07:59:16,451] Repair command #1 finished in 1 second
[2019-04-21 07:59:16,460] Replication factor is 1. No repair is needed for keyspace 'system_auth'
[2019-04-21 07:59:16,474] Starting repair command #2 (5c22e780-640b-11e9-a0e3-570eb7f8fd5f), repairing keyspace system_traces with repair options (parallelism: parallel, primary range: false, incremental: true, job threads: 1, ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 513, pull repair: false)
finished (progress: 1%)
[2019-04-21 07:59:17,653] Repair completed successfully
[2019-04-21 07:59:17,653] Repair command #2 finished in 1 second
कर्मचारी . में डेटा सत्यापित करें टेबल, जिसे हमने गिरा दिया। पिछला कमांड आपके द्वारा पहले लिए गए बैकअप से डेटा को पुनर्स्थापित करता है। अब आपको यह देखने के लिए डेटा को सत्यापित करने की आवश्यकता है कि क्या इसे ठीक से पुनर्स्थापित किया गया था।
$ cqlsh -u cassandra -p ********
Connected to Test_Cassandra at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.4 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cassandra@cqlsh> use users;
cassandra@cqlsh:users> select * from employee;
emp_id | employee_address | employee_name
--------+------------------+---------------
8796 | Singapore | Joy
5647 | London | Mike
3452 | Canada | Nancy
6453 | China | John
(4 rows)
निष्कर्ष
इस पोस्ट में, आपने सीखा कि कैसेंड्राडेटाबेस में किसी तालिका का बैकअप और पुनर्स्थापित करना है। हालांकि, यदि आपको एक पूर्ण कुंजी स्थान/डेटाबेस को पुनर्स्थापित करने की आवश्यकता है, तो तालिका के पुनर्स्थापना भाग के बिना पूर्ववर्ती चरणों का उपयोग करें। आपको कीस्पेस . को फिर से बनाना होगा और sstableloader . का उपयोग करके डेटा लोड करें ।
स्रोत और लक्ष्य डेटाबेस क्लस्टर में नोड्स की संख्या sstableloader से कोई फर्क नहीं पड़ता क्योंकि यह प्रत्येक स्थिरों . को पढ़ता है बैकअप से। फिर, यह डेटा को क्लस्टर में परिभाषित प्रतिकृति रणनीति के अनुसार डेटा रखते हुए क्लस्टर में स्ट्रीम करता है।
कोई टिप्पणी करने या प्रश्न पूछने के लिए प्रतिक्रिया टैब का उपयोग करें।
विशेषज्ञ प्रशासन, प्रबंधन और कॉन्फ़िगरेशन के साथ अपने परिवेश को अनुकूलित करें
रैकस्पेस की एप्लिकेशन सेवाएं(RAS) विशेषज्ञ अनुप्रयोगों के व्यापक पोर्टफोलियो में निम्नलिखित पेशेवर और प्रबंधित सेवाएं प्रदान करते हैं:
- ईकामर्स और डिजिटल अनुभव प्लेटफॉर्म
- एंटरप्राइज रिसोर्स प्लानिंग (ईआरपी)
- बिजनेस इंटेलिजेंस
- बिक्री बल ग्राहक संबंध प्रबंधन (सीआरएम)
- डेटाबेस
- ईमेल होस्टिंग और उत्पादकता
हम वितरित करते हैं:
- निष्पक्ष विशेषज्ञता :हम तत्काल मूल्य प्रदान करने वाली क्षमताओं पर ध्यान केंद्रित करते हुए आपकी आधुनिकीकरण यात्रा को सरल और मार्गदर्शन करते हैं।
- कट्टर अनुभव ™:हम पहले एक प्रक्रिया को जोड़ते हैं। प्रौद्योगिकी दूसरा। व्यापक समाधान प्रदान करने के लिए समर्पित तकनीकी सहायता के साथ दृष्टिकोण।
- बेजोड़ पोर्टफोलियो :हम व्यापक क्लाउड अनुभव लागू करते हैं ताकि आपको सही क्लाउड पर सही तकनीक को चुनने और परिनियोजित करने में मदद मिल सके।
- फुर्तीली डिलीवरी :हम आपसे मिलते हैं जहां आप अपनी यात्रा में हैं और सफलता को अपने साथ संरेखित करते हैं।
आरंभ करने के लिए अभी चैट करें।