हमें चर आकारों की लिंक्ड सूचियों की एक K संख्या दी जाती है जो उनके अनुक्रम में क्रमबद्ध होती हैं और हमें सूची को परिणामी सूची में इस तरह से मर्ज करना होता है कि परिणामी सरणी को क्रम में क्रमबद्ध किया जाता है और परिणामी सरणी को आउटपुट के रूप में मुद्रित किया जाता है उपयोगकर्ता।
उदाहरण के साथ समझते हैं:-
इनपुट -
इंट के =3;
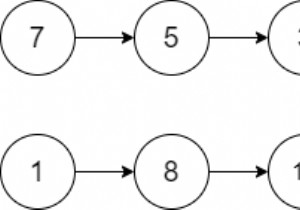
सूची [0] =नया नोड(11);
सूची [0]। अगला =नया नोड(15);
सूची [0] .next.next =नया नोड(17);
सूची [1] =नया नोड(2);
सूची [1]। अगला =नया नोड (3);
list[1].next.next =नया नोड(26);
सूची[1].next.next.next =नया नोड(39);
सूची[2] =नया नोड(4);
सूची[2]। अगला =नया नोड(8);
सूची[2].नेक्स्ट.नेक्स्ट =नया नोड(10);
आउटपुट −विलय की गई सूची है-->
2>> 3>> 4>> 8>> 10>> 11>> 15>> 17>> 26>> 39>> शून्य
स्पष्टीकरण -हमें K संख्या की लिंक्ड सूचियाँ दी गई हैं जिन्हें क्रम में क्रमबद्ध किया गया है। विलय प्रक्रिया में जावा तुलनित्र फ़ंक्शन का उपयोग करके लिंक की गई सूची के प्रमुख की तुलना करना और परिणामी सरणी में उन्हें एक साथ मर्ज करना शामिल है।
इनपुट -
इंट के =2;
सूची [0] =नया नोड(1);
सूची [0]। अगला =नया नोड (4);
सूची [0] .next.next =नया नोड(5);
सूची [1] =नया नोड(2);
सूची [1]। अगला =नया नोड (3);
list[1].next.next =नया नोड(6);
सूची[1].next.next.next =नया नोड(8);
आउटपुट - मर्ज की गई सूची है-->
1>> 2>> 3>> 4>> 5>> 6>> 8>> शून्य
स्पष्टीकरण -हमें K संख्या की लिंक्ड सूचियाँ दी गई हैं जिन्हें क्रम में क्रमबद्ध किया गया है। विलय प्रक्रिया में जावा तुलनित्र फ़ंक्शन का उपयोग करके लिंक की गई सूची के प्रमुख की तुलना करना और परिणामी सरणी में उन्हें एक साथ मर्ज करना शामिल है।
नीचे दिए गए प्रोग्राम में इस्तेमाल किया गया तरीका इस प्रकार है -
-
हम सूची (के) की संख्या के साथ इनपुट कर रहे हैं जिसे मर्ज करने की आवश्यकता है।
-
एक नोड क्लास को इनिशियलाइज़ किया जाता है जो एक लिंक्ड लिस्ट के नोड्स बनाने के लिए जिम्मेदार होता है।
-
उसके बाद लिंक की गई सूची के नोड्स को क्रमबद्ध क्रम में प्रारंभ किया जाता है और लिंक की गई सूची के प्रमुख को फ़ंक्शन (मर्जलिस्ट) के माध्यम से के रूप में पैरामीटर के साथ पारित किया जाता है।
-
फ़ंक्शन के अंदर लूप के अंदर दूसरी सूची से एक लूप को पुनरावृत्त किया जाता है, दूसरे लूप को पुनरावृत्त किया जाता है जिसमें तत्व की तुलना के लिए सभी उपयोगिता शामिल होती है।
-
पहली और पहली सूची दोनों के शीर्ष को वेरिएबल में कैप्चर और संग्रहीत किया जाता है।
-
फिर दोनों शीर्षों को छोटे शीर्ष तत्व के लिए जाँचा जाता है और परिणाम और परिणामी शीर्ष को अंतिम सूची के प्रमुख के रूप में सेट किया जाता है।
-
फिर सूची के निम्नलिखित तत्वों के लिए इसी तरह की प्रक्रिया की जाती है और डेटा की तुलना उनके सही क्रम के अनुसार की जाती है।
-
यदि सूची को अंत तक पुनरावृत्त किया जाता है तो अंतिम नोड को शून्य पर सेट कर दिया जाता है और अंतिम सूची उपयोगकर्ता को आउटपुट के रूप में वापस कर दी जाती है।
उदाहरण
आयात करें अगला नोड; सार्वजनिक नोड (इंट डेटा) { यह डेटा =डेटा; यह अगला =शून्य; }}पब्लिक क्लास टेस्टक्लास{ पब्लिक स्टैटिक नोड मर्जलिस्ट्स (नोड[] लिस्ट, इंट के) { प्रायोरिटी क्यू <नोड> प्रायोरिटी क्यू; प्राथमिकता क्यू =नई प्राथमिकता क्यू <नोड> (तुलनित्र.comparingInt (ए -> ((नोड) ए)। डेटा)); प्राथमिकता क्यूई.एडऑल (Arrays.asList (सूची)। उपसूची (0, के)); नोड सिर =अशक्त, अंतिम =अशक्त; जबकि (!priorityQueue.isEmpty ()) {नोड मिनट =प्राथमिकता क्यू.पोल (); अगर (सिर ==शून्य) {सिर =अंतिम =मिनट; } और { last.next =min; अंतिम =मिनट; } अगर (न्यूनतम। अगला! =शून्य) {प्राथमिकता क्यूई। जोड़ें (न्यूनतम। अगला); } } वापसी सिर; } सार्वजनिक स्थैतिक शून्य मुख्य (स्ट्रिंग [] एस) { int k =3; नोड [] सूची =नया नोड [के]; सूची [0] =नया नोड (11); सूची [0]। अगला =नया नोड (15); सूची [0]। अगला। अगला =नया नोड (17); सूची [1] =नया नोड (2); सूची [1]। अगला =नया नोड (3); सूची [1]। अगला। अगला =नया नोड (26); सूची [1]। अगला। अगला। अगला =नया नोड (39); सूची [2] =नया नोड (4); सूची [2]। अगला =नया नोड (8); सूची [2]। अगला। अगला =नया नोड (10); System.out.println ("मर्ज की गई सूची है -->"); नोड हेड =मर्जलिस्ट (सूची, के); जबकि (सिर! =शून्य) {System.out.print(head.data + ">>"); सिर =सिर। अगला; } System.out.print("null"); }}आउटपुट
यदि हम उपरोक्त कोड चलाते हैं तो यह निम्न आउटपुट उत्पन्न करेगा
मर्ज की गई सूची है-->2>> 3>> 4>> 8>> 10>> 11>> 15>> 17>> 26>> 39>> शून्य