साझा स्मृति मेमोरी ब्लॉक है जिसे एक से अधिक प्रोग्राम द्वारा एक्सेस किया जा सकता है। एक साझा स्मृति अवधारणा का उपयोग संचार का एक तरीका प्रदान करने और कम अनावश्यक स्मृति प्रबंधन प्रदान करने के लिए किया जाता है।
वितरित साझा मेमोरी DSM . के रूप में संक्षिप्त वितरित प्रणालियों में साझा स्मृति अवधारणा का कार्यान्वयन है। DSM सिस्टम साझा मेमोरी मॉडल को शिथिल युग्मित सिस्टम में लागू करता है जो सिस्टम में स्थानीय भौतिक साझा मेमोरी से वंचित हैं। इस प्रकार के सिस्टम में वितरित साझा मेमोरी एक वर्चुअल मेमोरी स्पेस प्रदान करती है जो सभी सिस्टम (जिसे नोड्स के रूप में भी जाना जाता है) द्वारा एक्सेस किया जा सकता है। ) वितरित पदानुक्रम का।
कुछ सामान्य चुनौतियाँ जिन्हें DSM के कार्यान्वयन के दौरान ध्यान में रखा जाना चाहिए -
-
साझा स्मृति में दूरस्थ रूप से संग्रहीत डेटा के स्मृति पते (स्थान) की ट्रैकिंग।
-
दूरस्थ डेटा के संदर्भों से जुड़े संचार विलंब और उच्च ओवरहेड को कम करने के लिए।
-
DSM में साझा किए गए डेटा की समवर्ती पहुंच को नियंत्रित करना।
इन चुनौतियों के आधार पर वितरित साझा स्मृति को लागू करने के लिए डिज़ाइन किए गए एल्गोरिदम हैं। चार एल्गोरिदम हैं -
- केंद्रीय सर्वर एल्गोरिथम
- माइग्रेशन एल्गोरिथम
- प्रतिकृति एल्गोरिथम पढ़ें
- पूर्ण प्रतिकृति एल्गोरिथम
सेंट्रल सर्वर एल्गोरिथम
सभी साझा डेटा केंद्रीय सर्वर द्वारा बनाए रखा जाता है . वितरित सिस्टम के अन्य नोड डेटा पढ़ने और लिखने का अनुरोध सर्वर के लिए जो पावती संदेशों के साथ अनुरोध करता है और अद्यतन करता है या डेटा तक पहुंच प्रदान करता है ।
इन पावती संदेशों का उपयोग सर्वर द्वारा दिए गए डेटा अनुरोध की स्थिति प्रदान करने के लिए किया जाता है। जब डेटा कॉलिंग फ़ंक्शन को भेजा जाता है, तो यह एक संख्या को स्वीकार करता है जो समवर्ती बनाए रखने के लिए डेटा के एक्सेस अनुक्रम को दर्शाता है। और विफलता के मामले में टाइम-आउट वापस कर दिया जाता है।
बड़े वितरित सिस्टम के लिए, एक से अधिक सर्वर हो सकते हैं। इस मामले में, सर्वर अपने पते का उपयोग करके या मैपिंग फ़ंक्शन का उपयोग करके स्थित होते हैं।

माइग्रेशन एल्गोरिथम
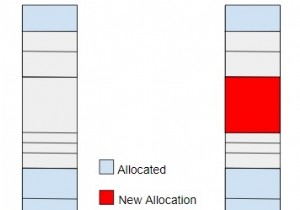
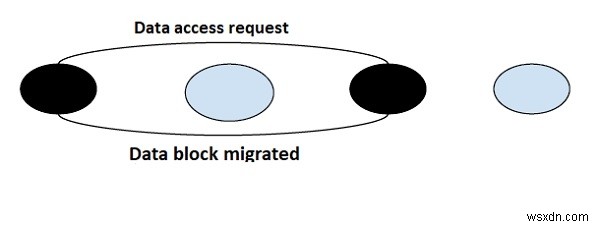
जैसा कि नाम से पता चलता है कि माइग्रेशन एल्गोरिथम डेटा तत्वों के माइग्रेशन का काम करता है। प्रत्येक अनुरोध परोसने वाले केंद्रीय सर्वर का उपयोग करने के बजाय, सिस्टम द्वारा अनुरोधित डेटा वाले ब्लॉक को माइग्रेट किया जाता है इसे आगे की पहुंच और प्रसंस्करण के लिए। यह अनुरोध पर डेटा माइग्रेट करता है।
हालांकि यह एल्गोरिथम अच्छा है यदि कोई सिस्टम डेटा के एक ही ब्लॉक को कई बार एक्सेस करता है और वर्चुअल मेमोरी को एकीकृत करने की क्षमता अवधारणा में कुछ कमियां हैं जिन्हें दूर करने की आवश्यकता है।
एक समय में केवल एक नोड साझा डेटा तत्व तक पहुँचने में सक्षम होता है और पूरे ब्लॉक को उस नोड में स्थानांतरित कर दिया जाता है। साथ ही, यह एल्गोरिथम अधिक थ्रेशिंग के लिए प्रवण . है नोड द्वारा अनुरोध किए जाने पर डेटा आइटम के स्थानांतरण के कारण।
प्रतिकृति एल्गोरिथम पढ़ें
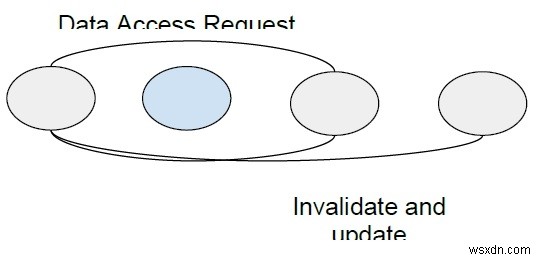
रीड रेप्लिकेशन एल्गोरिथम में, एक्सेस किया जाने वाला डेटा ब्लॉक प्रतिकृति . है और केवल पढ़ने की अनुमति है सभी प्रतियों में। यदि कोई लेखन कार्य किया जाना है, तो सभी कॉपियों के अद्यतन होने तक सभी पठन पहुँच को रोक दिया जाता है।
समवर्ती पहुंच की अनुमति . के रूप में समग्र सिस्टम प्रदर्शन में सुधार हुआ है . लेकिन लिखें ऑपरेशन महंगा है समवर्ती बनाए रखने के लिए साझा किए गए सभी ब्लॉकों को अद्यतन करने की आवश्यकता के कारण। निरंतरता बनाए रखने के लिए डेटा तत्व की सभी प्रतियों को ट्रैक किया जाना है।
पूर्ण प्रतिकृति एल्गोरिथम
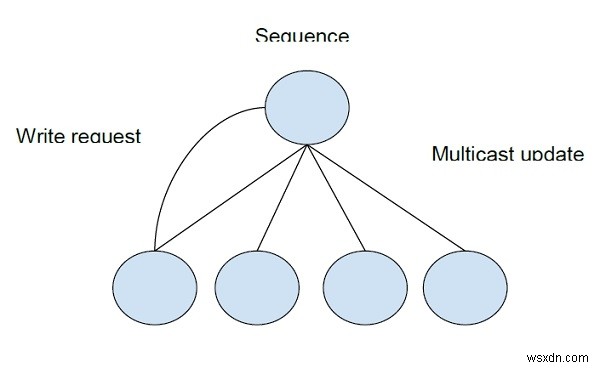
प्रतिकृति एल्गोरिथम को पढ़ने के लिए एक एक्सटेंशन जो नोड्स को पढ़ने और लिखने दोनों को निष्पादित करने की अनुमति देता है समवर्ती के साझा ब्लॉक पर संचालन। लेकिन नोड्स की इस पहुंच को इसकी निरंतरता बनाए रखने के लिए नियंत्रित किया जाता है।
सभी नोड्स की समवर्ती पहुंच पर डेटा की निरंतरता बनाए रखने के लिए अनुक्रम बनाए रखा जाता है और डेटा एक मल्टीकास्ट में किए गए प्रत्येक संशोधन के बाद संशोधनों के साथ सभी डेटा प्रतियाँ परिलक्षित होती हैं।